エージェント向け製品設計
Salesforceが「Headless 360」を発表し、UIを廃止して全機能をAPIやMCP経由でAIエージェントに開放する方針を示したことで、ソフトウェア設計における「UIの死」と「Agent中心のインタラクション」への移行が現実的な業界標準となりつつある。
キーポイント
SalesforceのHeadless 360発表
Salesforceは27年史で最大のアーキテクチャ転換として、プラットフォームの全機能をAPI、MCPツール、CLIコマンドとして公開する「Headless 360」を発表し、ブラウザを開かずにAIエージェントがシステムを操作可能にした。
インタラクションモデルの転換
従来の「ユーザー→UI→DB」から、「ユーザー→ユーザーのAgent→ソフトウェアのAgent→DB」という2層のエージェント協調モデルへ移行しており、UIは消滅するが、バックグラウンドでのAgent間連携が重要になる。
UIの死と80/20の逆転
UIが完全に消滅するわけではないが、人間とソフトウェアのインタラクションのうち80%をAIエージェントが担うようになり、開発者は「人間向けのUI」と「Agent向けのインターフェース」の両方を設計する必要がある。
MCPとRampの実証
FinTech企業のRampでは、ClaudeやChatGPTなどのAIエージェント経由でのMCP利用により、週間アクティブユーザーが3ヶ月で10倍に成長しており、このトレンドは既に市場で顕在化している。
影響分析・編集コメントを表示
影響分析
SalesforceのHeadless 360発表は、単なる機能追加ではなく、エンタープライズソフトウェアの根本的なアーキテクチャとビジネスモデルの転換を示唆しています。これにより、従来のGUI依存型SaaS企業の競争優位性が崩れ、MCPやAPI経由でエージェントに提供される「頭なし(Headless)」なインフラ構築能力が新たな参入障壁となります。今後、UIの質よりも「Agentとの親和性」が製品選定の主要因となるため、開発者はインタフェース設計の視点を一変させる必要があります。
編集コメント
Salesforceの「Headless 360」は、UI設計のパラダイムシフトを象徴する出来事であり、今後は「ユーザー体験」だけでなく「エージェントとのインタラクション設計」が製品競争力の核心になる。
もしあなたが私と同じように、X(旧Twitter)の特定のタイムラインを頻繁にチェックしているなら、「ユーザーインターフェースは死んだ」という主張を目にしたことがあるはずです。
「Obsidian で第二の脳を構築する方法」のような投稿と、「Anthropic が某業界を完全に壊滅させた」といった投稿が混在するフィードをスクロールしているうちに、やがて「MCP、API、CLI、あるいはその中間の手段で AI エージェント(AI Agent)に利用できない製品は生き残れない」という意見を目にするようになります。
この傾向は Ramp においてすでに顕著です。過去3ヶ月間で、Claude、ChatGPT、その他の AI エージェントを通じて当社の製品を利用する顧客が増えるにつれ、MCP における週間アクティブユーザー数が10倍に増加しました。(MCP:Model Context Protocol、モデルコンテキストプロトコル。これは AI エージェントが外部ツールやデータにアクセスするための標準的な手段と理解できます。)
先週、Salesforce はこの判断を積極的に受け入れた最初の伝統的なソフトウェア大手の一つとなりました。
https://www.salesforce.com/ は水曜日、同社27年の歴史において最も過激なアーキテクチャ変革を発表し、「[https://www.salesforce.com/news/stories/salesforce-headless-360-announcement/」を立ち上げました。これはプラットフォーム全体を対象とした大規模な計画で、プラットフォーム内のすべての機能を API、MCP ツール、または CLI コマンドとして公開し、AI エージェントがブラウザを開くことなくシステム全体を操作できるようにするものです。
この発表は、Salesforceがサンフランシスコで開催する年次https://www.salesforce.com/tdx/大会で発表され、100以上の新しいツールやスキルがすぐに開発者に公開されました。また、これは企業ソフトウェアの頭上に懸かる死活問題に正面から応えるものです:AIエージェントがすでに推論、計画、実行を行えるようになった今、企業はグラフィカルインターフェースを備えたCRM(Customer Relationship Management)システムをなお必要とするのか?
Salesforceの答えは「不要」であり、これこそがポイントです。
Salesforceのこの一手は賢明であり、これが容易な決定ではなかったことは想像に難くありません。多くの営業担当者にSalesforceの使用感を尋ねれば、彼らはおそらくSalesforceを使うのが好きではないと答えるでしょう。しかし、Salesforceがこれほどまでに普及している理由の大きな部分は、そのユーザー体験(UX)が十分に慣れ親しんだものであることです。営業責任者は通常、チーム全体を新しい技術に適応させることを望みません;多くの場合、機能の豊かさよりも一貫性の方が重要です。
Benioff氏とそのチームは、この堀(護城河)が侵食されつつあることを認めています。彼らはまた、今後多くの行動がClaude、ChatGPT、そしてユーザーには見えないバックグラウンドのプロセスを通じて行われるという現実を積極的に受け入れ始めています。
私はユーザーインターフェース(UI)が死滅すると考えていません。人間はまだボタンをクリックし、設定を確認し、タスクが完了したことを確認したいと考えています。しかし、パレートの法則(二八法则)は逆転しています:未来における人間とソフトウェアの80%のインタラクションは、AIエージェントを通じて行われることになります。これはあなたが何を構築する必要があるかだけでなく、どのようにそれを構築するかをも変えるでしょう。
新しいインタラクションモード
過去20年間、人々がソフトウェアとインタラクションする主要な方法は以下の通りでした:
ユーザー → インターフェース → データベース
製品を開き、クリックして操作し、タスクを完了させます。インターフェースこそがソフトウェアを体験する方法です。多くの人にとって、インターフェース自体が製品そのものです。
しかし、AIエージェントがより多くの作業を引き受けるにつれて、新しい中間層が登場しました:
ユーザー → ユーザーのAIエージェント(例:Claude)→ データベース
AIエージェントはユーザーに代わって行動します。それは読み取り、書き込み、製品の閲覧を行い、ユーザーが自ら操作する必要がなくなります。突然、インターフェースは消滅します。エージェントは直接基盤システムと対話し始めます。
ただし、このモードも急速に変化しています。ソフトウェア会社は——そしてそうすべきです——独自のAIエージェントと能力を設計しています。したがって、新しいモードはより以下のようになります:
ユーザー → ユーザーのAIエージェント → ソフトウェア独自のAIエージェント → データベース
このモデルでは、ソフトウェア独自のAIエージェントがユーザーのエージェントの複雑さを処理します:ビジネスロジックの実行、ルールの適用、後者が持たないコンテキストの補完。2つの大規模言語モデル(LLM)が協力して、同じ結果に向けて進みます。
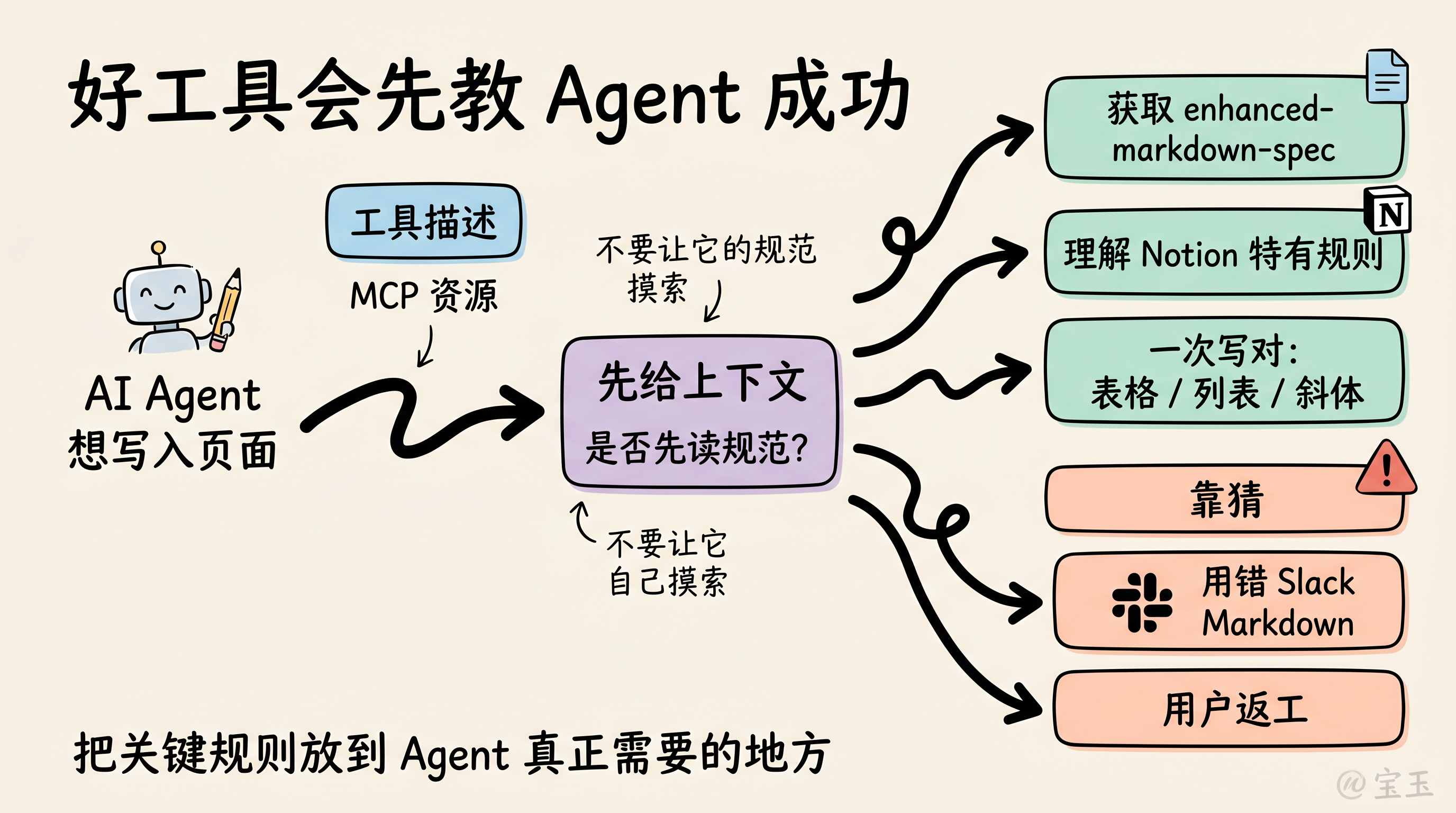
AIエージェントに成功する方法を教える
現在、私のブレインストーミング、執筆、アイデア出しの大部分は、大規模言語モデルとの共同作業によって行われています。ドラフトが共有準備ができると、NotionのMCPサーバーを通じてNotionに送信します。私は長年Google Docsの忠実なユーザーでしたが、NotionのMCPが私の習慣を変えました。
Notion MCPの利用者として私が賞賛している点は、AIエージェントに何かを書かせると、それがほぼ毎回完璧に実行されることです。表、箇条書き、斜体、リストなど、考えられるフォーマットはすべて正しく処理されます。
これは偶然ではなく、設計された結果です。
Notion の notion-create-pages ツール説明には、最初から「完全な Markdown 仕様の詳細が必要な場合は、まず MCP リソース notion://docs/enhanced-markdown-spec を取得してください。Markdown 構文を推測したり、幻覚で生成したりしないでください」と明記されています。私がエージェントにページへの書き込みを指示した際、その最初の行動はまさにこの仕様の取得でした。まず仕様を読み、その後で書き込みを開始します。Notion 固有の仮定はすべて明示され、汎用モデルのデフォルト理解に依存することはありません。
旧世界では、こうした仕様は API ドキュメントに記載されていました。Notion に接続する開発者はドキュメントを読み、ルールを理解し、変換層を構築していました。現在では、Notion は AI エージェントが実際に必要とする瞬間に、直接仕様を提供します。
Slack MCP を使用した経験があるなら、逆のケースを経験しているかもしれません。あなたの AI エージェントは標準 Markdown をデフォルトで使用しますが、Slack 独自の特定フォーマットに従いません。その結果、書式修正に費やす時間が、手動でメッセージを作成する時間よりも多くなることがあります:

もちろん、Slack のフォーマットガイドはオンラインで入手可能であり、保存してエージェントに使い方を教えることも可能です。しかし、それは煩雑であり、本来ユーザーが気にすべきことではありません。
あなたが考えるべきは、あなたのエージェントを呼び出す人が、成功するために何を知る必要があるかです。そして、その情報を積極的に提供してください。エージェントに独自で調査させるのではなく、手助けしてあげましょう。
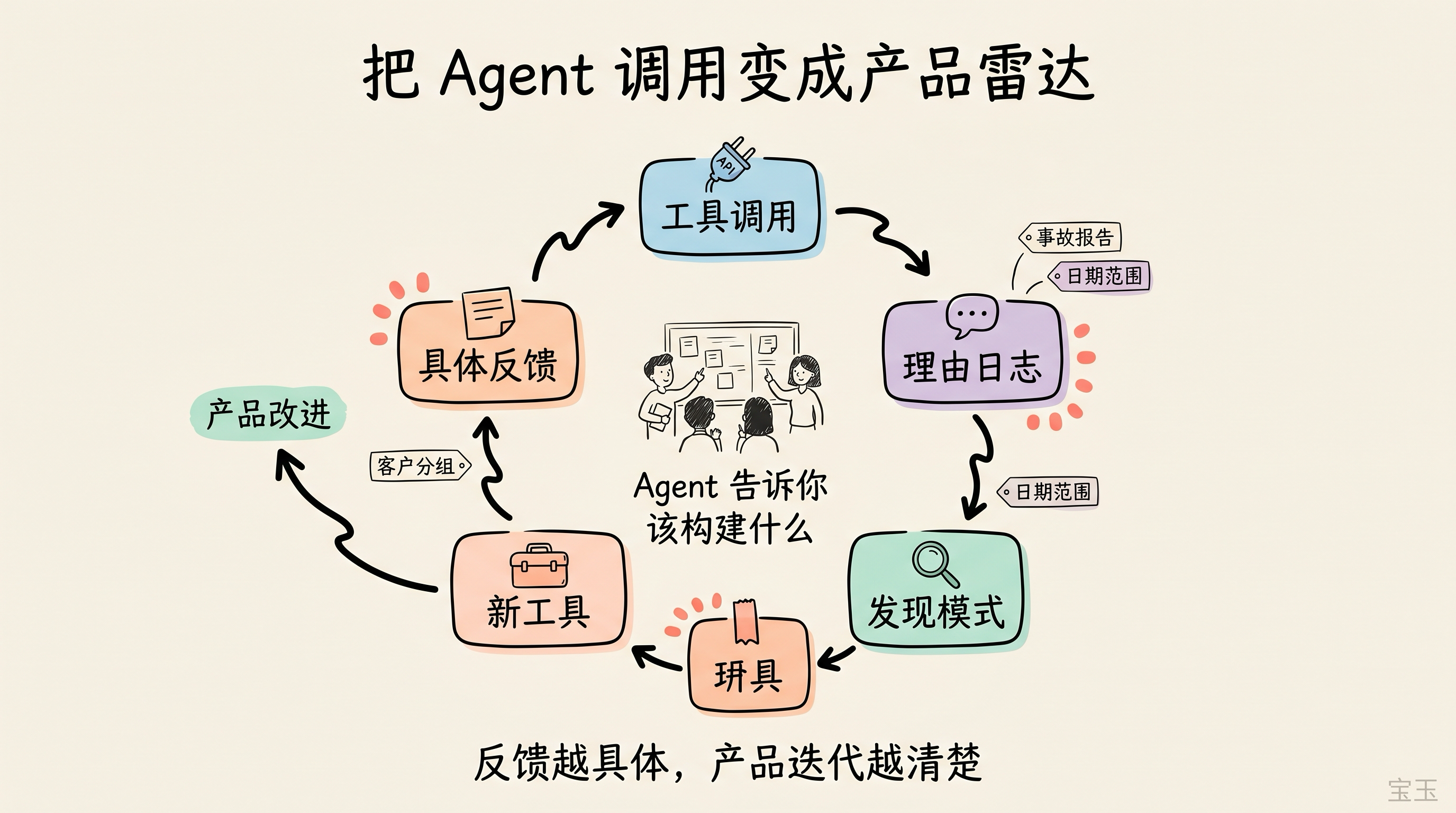
フィードバックループの構築
Ramp で MCP を公開した当初、最大の課題は観測可能性(observability)でした。ツール呼び出しの数は確認できましたが、それらの呼び出しを引き起こしたチャットのコンテキストは見えませんでした。単に呼び出し数を知るだけでは、何が機能し、何が壊れ、ユーザーが実際に何を実現しようとしているのかを教えてくれません。
その後、私たちはいくつかの方法でこの問題を解決しました:
- 各ツール呼び出しに「理由」の記入を要求する。 すべての MCP または CLI ツール呼び出しにおいて、AI エージェントに rationale 引数を含めさせ、リクエストを発行する理由を説明させます。チャット内容は見えませんが、この理由によって意図を再構築できます。理由に含まれるパターンから、ユーザーの本当の目的がわかります。
- フィードバックツールを提供する。 独立したツールを公開しました。AI エージェントが壁にぶつかったり、特定のパターンが機能しないことに気づいたりした場合、このツールを呼び出すことができます。エージェントは、本来達成しようとしていたこと、試した内容、そして行き詰まった箇所を提出します。
- 特定のツールにコンテキストシードを追加する。 単一のツールに対して、後ほど有用となるコンテキストを捕捉するために特別に設計された引数を追加します。この情報はエージェントが取得可能ですが、能動的に収集しない場合、後からでは推測するしかなくなります。
顧客サポートプラットフォームを構築し、ツールを通じて顧客がチケットを取得できるようにしていると想像してください。時間が経つと、理由ログの中で「インシデントレポートを生成中」「インシデント概要のドラフト作成中」「ダウンタイム振り返り関連チケットの収集中」といった類似の表現が繰り返し目立つようになります。
これは新たな製品機能のシグナルです! 関連するチケットを識別し、重大度を評価し、影響を受けた顧客グループを取得し、強力な制約付きフォーマットで概要をドラフト作成する build-incident-report ツールを作成できます。
このツールが公開された後、以下のようなフィードバックが届き始めるかもしれません。「レポートに3日前のチケットが含まれているが、それらは今回のインシデントには関係ない」「無料プランユーザーのチケットを常に振り返りに含めてしまうが、これらのユーザーはインシデント振り返りには含まれるべきではない」。突然、あなたの AI エージェントが、次に構築すべきことをあなたに教えてくれるようになります。
AI エージェントは間違いなくハルシネーションを起こします。しかし、フィードバックの点において、それらはあなたが製品に送る人間のユーザーの大多数よりも、具体的かつ一貫性のある報告を行う傾向があります。
レポートに無関係なチケットが含まれている場合は、日付範囲のパラメータを追加します。フリープランの顧客を含めるべきでない場合は、顧客セグメントのフィルターを追加します。各フィードバックループは、製品改善のための新たな入力口となります。
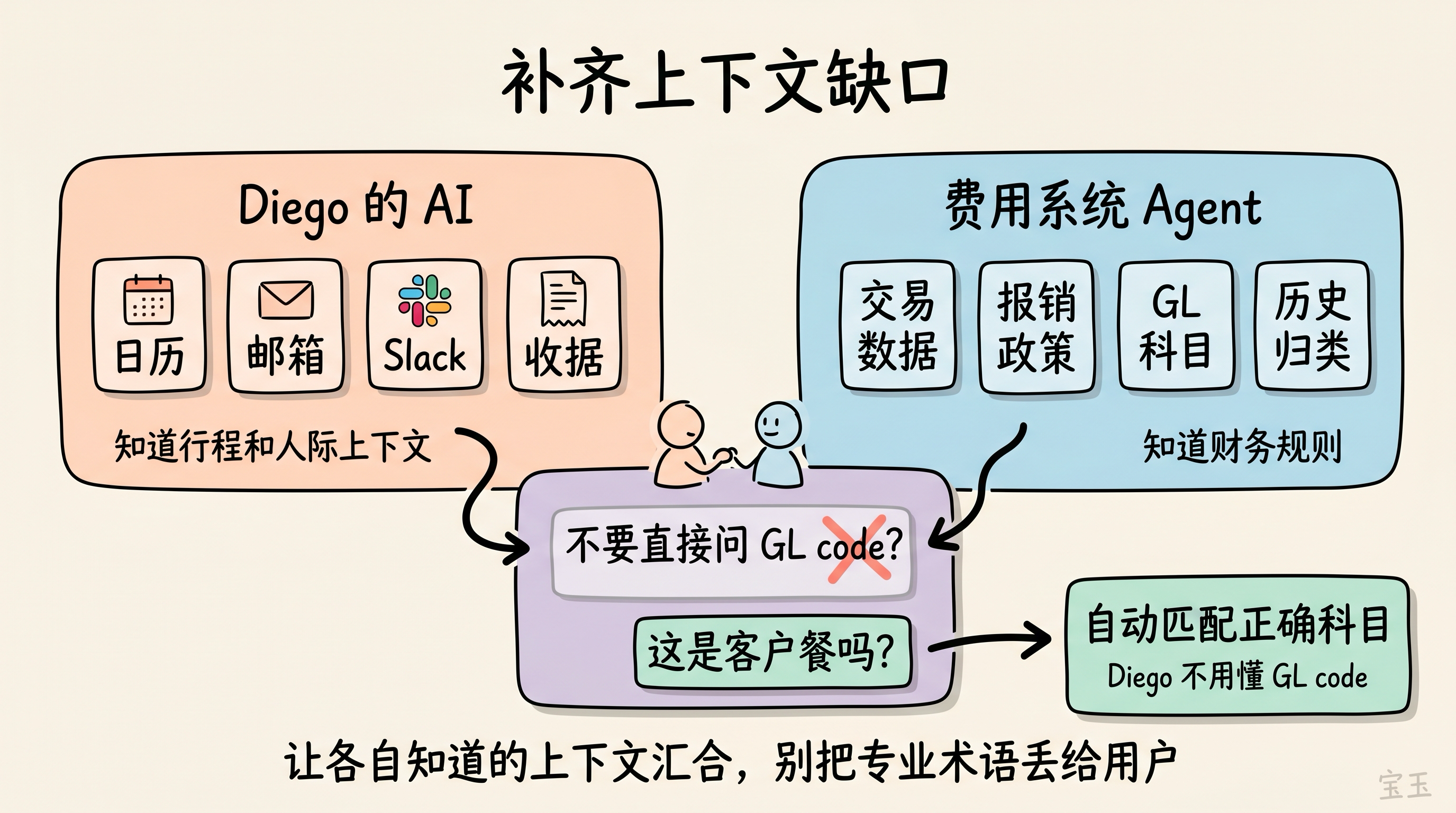
文脈のギャップに注意する
あらゆる AI エージェント間のやり取りにおいて、あなたのシステムは呼び出し元エージェントが知らない文脈の一部を保持しており、一方、呼び出し元エージェントもあなたのシステムが知らない文脈の一部を保持しています。これらのやり取りを設計する際、どちらの側がどの情報において優位性を持っているかを明確に判断すべきです。
例えば、Diego が出張に出ました。彼の AI 首席補佐官は、経費管理システムのエージェントから Slack の通知を受け取ります:最近の出張で未処理の精算があるとのことです。現在、2 つの AI エージェントは同じ目標——これらの精算を正しく提出すること——に向かっています。
これら 2 つのエージェントは、それぞれ異なる文脈を持っています。
Diego の AI 首席補佐官が知っていること:
- Diego のカレンダー:どの会議が行われ、いつ、誰と行ったか
- Diego のメール:ホテルやフライトの確認メールの添付ファイル
- Diego の Slack:Kokkari での夕食を、Acme チームを招待した会話スレッドに関連付けることができる
- Diego のレシート:メールの添付ファイルや写真ギャラリーから取得
経費管理システムが知っていること:
- 元の取引データ(例:店舗名、取引時刻)
- 精算提出に関する会社のポリシー
- 会社の総勘定元帳科目(GL accounts)(GL は通常 General Ledger、つまり財務会計における総勘定元帳の分類を指します)
- 会社の過去の費用分類の習慣
従来の API は、この問題をユーザーに戻します:「ここに GL コードの入力が必要な取引があります。このインターフェースを呼び出して 150 個の GL コードオプションを取得し、自分で選択してください。」
適切に設計された AI エージェント間のやり取りは、この処理を逆に行います——GL コードを直接要求するのではなく、文脈を要求します。これは顧客接待費、チーム会議費、それとも個人の旅行支出でしょうか?AI 首席補佐官は、カレンダーエントリや Slack の会話から答えを見つけることができます。その後、経費管理システムは、自身が欠いていた文脈に基づいて、正しい科目を自動的に適用します。
Diego も彼のエージェントも、GL コードが具体的に何であるかを知らなくても構いません。財務チームは正確な分類を得ることができます。双方は各自が知っている情報を貢献し、最終的に Diego——そして彼の会計担当者にとっても——より良い結果を納品します。
エージェントからエージェントへのやり取りを設計する際、文脈のギャップに必ず注意してください。あなたのエージェントがどこで苦手であるかを認めることは完全に許容されます——なぜなら、你们は実際には同じユーザーのためにサービスを提供しているからです。
過去では、インターフェースは Diego と彼の経費システムの間に挟まれていました。現在、インターフェースは彼のエージェントとあなたのエージェントの間に挟まれています。
この変化は、製品チームの仕事の定義を再定義します。過去には、あなたはタスクを迅速に完了し、ミスを避け、自分の作業を見える化したい生身の人間のために製品を設計していました。現在でも、あなたは同じ人をサービスしていますが、その間に仲介者(エージェント)が追加されています。その直感、文脈、および限界は人間とは異なります。
AI エージェントが成功する方法を教えること、フィードバックループを構築すること、文脈のギャップに注意すること——これら 3 つのことの背後にある本質的な問いは同じです:あなたのエージェントを呼び出す側が、仕事を遂行するために本当に必要としているものは何か?あなたはそれらをそのエージェントに提供していますか?
多くの企業はMCPを1つリリースし、「私たちもAIエージェントに対応しています」というチェックボックスにチェックを入れるだけで、次のステップへ進んでしまいます。その利用数は数四半期は増加するかもしれませんが、その後停滞します。時が経つにつれて、顧客は細部まで磨き込まれた製品へと流れていき、おざなりな対応の製品は避けられるようになります。
当初、人間ユーザーのために製品を設計したように、AIエージェントのためにも真摯に製品を設計してください。なぜなら、やがて請求書にサインする相手こそがエージェントであることに気づくことになるからです。
原文を表示
原文:Designing for Agents**
作者:Teddy Riker
如果你和我一样,经常混在 X 上同一个信息圈里刷动态,那么你大概也见过这种说法:用户界面已经死了。
你会一边刷到“我如何用 Obsidian 搭建第二大脑”,一边刷到“Anthropic 彻底杀死了某某行业”这类帖子。然后很快,你就会看到有人说:一个产品如果不能被 AI 智能体(AI Agent)通过 MCP、API、CLI,或者介于它们之间的方式使用,那它就活不下去。
这个趋势在 Ramp 已经很明显。过去三个月里,随着越来越多客户开始通过 Claude、ChatGPT 和其他 AI 智能体进入我们的产品,我们 MCP 上的每周活跃用户增长了 10 倍。(MCP,Model Context Protocol,模型上下文协议,可以理解为一种让 AI 智能体调用外部工具和数据的标准方式。)**
上周,Salesforce 成了最早主动拥抱这个判断的传统软件巨头之一。
https://www.salesforce.com/ 周三宣布了这家公司 27 年历史上最激进的一次架构转型,推出了“https://www.salesforce.com/news/stories/salesforce-headless-360-announcement/”——这是一项覆盖整个平台的大计划:把平台里的每一项能力都暴露成 API、MCP 工具或 CLI 命令,让 AI 智能体可以在完全不打开浏览器的情况下操作整个系统。
这项发布是在 Salesforce 于旧金山举办的年度 https://www.salesforce.com/tdx/ 大会上宣布的,并且立刻向开发者开放了 100 多个新工具和技能。它也正面回应了一个悬在企业软件头顶的生死问题:当 AI 智能体已经能够推理、规划和执行时,一家公司还需要一个带图形界面的 CRM 吗?
Salesforce 的回答是:不需要——而这正是重点。
Salesforce 这一步很聪明,而且我很难想象这会是一个容易做出的决定。你问大多数销售,他们大概率会告诉你,他们并不喜欢用 Salesforce。但 Salesforce 之所以无处不在,很大一部分原因正是它的用户体验(UX)足够熟悉。销售负责人通常并不想让整个团队重新适应一套新技术;在很多时候,一致性比功能强大更重要。
Benioff 和他的团队正在承认:这条护城河正在被侵蚀。他们也开始主动拥抱一个现实——未来大量使用行为会通过 Claude、ChatGPT 以及其他用户根本看不见的后台流程来完成。
我并不认为用户界面(UI)正在死亡。人类仍然想要点击按钮、查看配置、确认任务已经完成。但二八法则已经反过来了:未来人与软件之间 80% 的交互,都会通过 AI 智能体完成。这不仅会改变你需要构建什么,也会改变你构建它的方式。
新的交互模式
过去二十年里,人们和软件交互的主要方式是:
用户 → 界面 → 数据库
你打开一个产品,点来点去,把事情做完。界面就是你体验软件的方式。对大多数人来说,界面本身就是产品。
但随着 AI 智能体接手越来越多工作,一个新的中间层出现了:
用户 → 用户的 AI 智能体(比如 Claude)→ 数据库
AI 智能体代表用户行动。它读取、写入、浏览产品,这样用户就不用亲自操作。突然之间,界面消失了。智能体开始直接和底层系统对话。
不过,这个模式也在迅速变化。软件公司正在——而且也应该——设计自己的 AI 智能体和能力。所以新的模式更像这样:
用户 → 用户的 AI 智能体 → 软件自己的 AI 智能体 → 数据库
在这个模型里,软件自己的 AI 智能体会替用户的智能体处理复杂性:执行业务逻辑、落实规则、补充后者没有的上下文。两个大语言模型(LLM)一起协作,朝着同一个结果推进。
教会 AI 智能体如何成功
我现在大部分头脑风暴、写作和构思,都是和大语言模型一起完成的。当一篇草稿准备好分享时,我会通过 Notion 的 MCP 服务器把它推到 Notion 里。我曾经是 Google Docs 的忠实用户很多年,但 Notion 的 MCP 改变了我的习惯。
作为 Notion MCP 的用户,我很欣赏的一点是:每次我让 AI 智能体写点什么,它几乎都能一次到位。表格、项目符号、斜体、列表,你能想到的格式,它都不会出错。
这不是偶然,而是设计出来的。
Notion 的 notion-create-pages 工具描述一开始就写着:“如需完整 Markdown 规范,必须先获取 MCP 资源 notion://docs/enhanced-markdown-spec。不要猜测或幻觉 Markdown 语法。”当我让智能体写入一个页面时,它做的第一件事就是获取这份规范。先读规范,再动笔。所有 Notion 特有的假设,都会被明确指出,而不是依赖通用模型的默认理解。
在旧世界里,这类规范会放在 API 文档里。接入 Notion 的开发者会读文档、理解规则,然后写一个转换层。现在,Notion 会在 AI 智能体真正需要的时候,直接把规范交到它手里。
如果你用过 Slack MCP,可能就体验过相反的情况。你的 AI 智能体会默认使用标准 Markdown,却没有遵守 Slack 自己那套特定格式。结果是,你花在修改格式上的时间,可能比自己手写消息还多:
当然,Slack 的格式指南在网上能找到,你也可以把它保存下来,再教你的智能体怎么用。但这很烦,而且本来就不该是用户需要操心的事。
你应该思考:调用你家智能体的人,需要知道什么才能成功?然后主动把这些信息交给它。不要让它自己摸索。
建立反馈循环
当我们刚在 Ramp 发布 MCP 时,最大的问题是可观测性(observability)。我们能看到工具调用量,但看不到触发这些调用的聊天上下文。仅仅知道调用量,并不能告诉我们什么有效、什么坏了、用户到底想完成什么。
后来我们用几种方式解决了这个问题:
- 每次工具调用都要求填写“理由”。 每一次 MCP 或 CLI 工具调用,都要求 AI 智能体带上一个 rationale 参数,解释它为什么要发起这个请求。我们看不到聊天内容,但这个理由可以重建意图。理由里的模式,会告诉我们用户到底想做什么。
- 提供一个反馈工具。 我们发布了一个独立工具。当 AI 智能体遇到阻碍,或者发现某种模式行不通时,它可以调用这个工具。它会提交自己原本想做什么、尝试了什么、卡在了哪里。
- 给特定工具加入上下文种子。 我们会给单个工具加入专门设计的参数,用来捕捉之后会有用的上下文:这些信息智能体能拿到,但如果不主动收集,我们之后只能靠猜。
想象一下,你正在做一个客户支持平台,并提供工具让客户抓取工单。过了一段时间,你开始在理由日志里反复看到类似表达:“正在生成事故报告”“正在起草事故摘要”“正在收集停机复盘相关工单”。
这就是一个新产品功能的信号!你可以做一个 build-incident-report 工具,用来识别相关工单、评估严重程度、拉取受影响的客户群体,并用一种强约束的格式起草摘要。
这个工具上线后,你可能又会开始收到反馈:“报告拉进了三天前的工单,但那些不属于这次事故”,或者“它总是把免费套餐用户的工单也放进复盘里,但这些用户不应该出现在事故复盘中”。突然之间,你的 AI 智能体开始告诉你的 AI 智能体:接下来到底该构建什么。
AI 智能体当然会幻觉。但在反馈这件事上,它们往往比你真正发给产品的多数人类用户更具体,也更一致。
如果报告拉进了无关工单,你就增加一个日期范围参数。如果不该包含免费套餐客户,你就增加一个客户分组筛选器。每一个反馈循环,都会变成产品改进的新入口。
留意上下文缺口
在任何 AI 智能体交互中,你的系统掌握一些调用方智能体不知道的上下文;而调用方智能体也掌握一些你的系统不知道的上下文。设计这些交互时,你应该清楚地判断:哪一方在哪些信息上更有优势。
比如 Diego 去出了一趟差。他的 AI 首席幕僚收到一条来自费用管理系统智能体的 Slack 提醒:他最近这趟出差还有未完成的报销。现在,两个 AI 智能体都指向同一个目标:正确提交这些报销。
这两个智能体各自带着不同的上下文。
Diego 的 AI 首席幕僚知道:
- Diego 的日历:知道哪些会议发生了、在什么时候、和谁一起
- Diego 的邮箱:有酒店和航班确认邮件附件
- Diego 的 Slack:能把 Kokkari 那顿晚餐关联到一个他邀请 Acme 团队的对话线程
- Diego 的收据:来自邮件附件和照片图库
费用管理系统知道:
- 原始交易数据,比如商户、交易时间
- 公司关于报销提交的政策
- 公司的总账科目(GL accounts)(GL 通常指 General Ledger,也就是财务记账里的总账分类)
- 公司过往的费用归类习惯
传统 API 会把问题丢回给用户:“这里有一笔交易需要填写 GL code。请调用这个接口获取 150 个 GL code 选项,然后自己选一个。”
设计得好的 AI 智能体交互会反过来处理这件事——它不会直接索要 GL code,而是索要上下文:这是一顿客户餐、团队餐,还是个人旅行支出?AI 首席幕僚可以从日历条目或 Slack 对话里找到答案。然后费用管理系统根据自己原本缺失的那部分上下文,自动套用正确的科目。
Diego 和他的智能体都不需要知道 GL code 到底是什么。财务团队也能得到准确的分类。双方各自贡献自己知道的信息,最终交付一个对 Diego——也对他的会计——都更好的结果。
当你设计这种智能体到智能体的交互时,一定要留意上下文缺口。承认你的智能体在哪些地方不擅长,是完全可以的——因为你们其实是在服务同一个用户。
过去,界面夹在 Diego 和他的费用系统之间。现在,界面夹在他的智能体和你的智能体之间。
这个变化重新定义了产品团队的工作。过去,你是在为一个想快速完成任务、避免犯错、看得见自己工作的真人设计产品。现在,你仍然是在服务同一个人,只不过中间多了一个代理者。它的直觉、上下文和局限,都和人类不同。
教会 AI 智能体如何成功、建立反馈循环、留意上下文缺口,这三件事背后其实都在问同一个问题:调用你家智能体的一方,到底需要什么才能把工作做好?你有没有把这些东西交给它?
大多数公司会发布一个 MCP,勾上“我们也支持 AI 智能体了”这个框,然后继续往前走。它们的使用量可能会增长几个季度,然后停滞。随着时间推移,客户会流向那些真正打磨细节的产品,也会绕开那些只是敷衍了事的产品。
像当初为人类用户设计产品一样,认真为 AI 智能体设计产品。因为你很快就会发现,最后签支票的,可能正是它。
関連記事
Amazon Quick と New Relic を活用したエージェント型インシデントトリアージアシスタントの構築方法
AWS は、サイト信頼性エンジニアが複数のツール間で証拠収集や影響評価を行う負担を軽減するため、Amazon Quick と New Relic を組み合わせたエージェント型インシデントトリアージアシスタントの構築手法を発表した。
エージェントシステムにおける意図と実行の架橋
Amazon Science は、AI エージェントのパフォーマンスはモデル自体の問題ではなく、LLM とツール間の仲介役となるハッチ(OS)の設計がボトルネックであると指摘し、意図を実行に移すシステムの重要性を強調した。
マイクロソフト、Frontier ユーザー向けに Scout AI エージェントを本格展開
マイクロソフトは、Microsoft 365 の自動化を強化する常時稼働型エージェント「Scout」を Frontier プログラムのユーザーへ提供を開始した。同エージェントは多段階ルーチンの実行やローカルファイルとの連携、OpenAI や Anthropic モデルのサポート機能を備えている。