Toto 2.0:時系列予測がスケーリング時代へ突入
Datadog が公開した時系列予測モデル「Toto 2.0」は、パラメータ規模の拡大に伴い性能が向上し、既存ベンチマークで最上位を記録する画期的な成果を示した。
キーポイント
スケーリング効果の実証
400 万パラメータから 25 億パラメータまでサイズが拡大するにつれて性能が向上し、2.5B の時点でも飽和の兆候は見られないことが確認された。
主要ベンチマークでの首位獲得
Datadog 独自の BOOM、汎用標準である GIFT-Eval、そして汚染耐性を持つ TIME など、すべてのテストで最高スコアを記録した。
前世代からの劇的な進化
Toto 1.0 と比較して品質を維持するためのパラメータ効率が 7 倍向上し、推論速度も大幅に高速化されている。
汎用性と学習データの特性
事前学習時に公的な時系列データを使用せず、観測可能性データと合成データのみで訓練されたにもかかわらず、汎用ベンチマークで圧倒的な性能を発揮した。
影響分析・編集コメントを表示
影響分析
この発表は、時系列予測分野において「スケーリング則」が成立することを明確に示し、従来の統計的手法や小規模モデルからの転換を加速させる契機となる。特に、公的データへの依存度を下げつつ汎用性を高める手法は、プライバシーやデータ可用性の制約がある実務現場での AI 導入を後押しする重要な指針となる。
編集コメント
時系列予測の分野で「スケーリング則」が明確に証明されたことは、産業用 AI の未来を大きく拓くニュースです。特にデータプライバシーを考慮した合成データの活用戦略は、実務家にとって非常に示唆に富む内容となっています。
本日、オープンウェイトの時系列予測モデルのファミリーであるToto 2をHugging Face上でリリースいたします。400万パラメータから25億パラメータまでをカバーするToto 2.0は、シンプルかつオープンな問いに答えるために設計されています。「時系列ファウンデーションモデル(TSFMs)は、スケールするにつれて性能が向上するのか?」という問いに対する私たちの結果は、「できる」というものです。主なポイントは以下の通りです。
- スケーリングが機能する。あらゆるサイズにおいて、下位のサイズよりも改善が見られ、25億パラメータにおいても飽和の兆候は見られません。
- 実施したすべてのベンチマークで最高クラスを達成。Toto 2.0は、Datadogの観測可能性予測用ベンチマークであるBOOM、標準的な汎用ベンチマークであるGIFT-Eval、そして新しい汚染耐性ゼロショットベンチマークであるTIMEにおいて、いずれもトップの座を獲得しました。
- Toto 1.0からの世代を超えた飛躍。Toto 2.0は、同等の品質を達成する際のパラメータ効率が7倍向上しており、推論時の速度も劇的に高速化されています。
- 観測可能性データと合成データでトレーニングされ、広範な一般化が可能。Toto 2.0は事前学習中に公開されている予測データを一切使用していませんが、汎用ベンチマークでは分野をリードしています。
CRPS ランクとパラメータ数の関係(左:BOOM、右:GIFT-Eval)における主要なファウンデーションモデルの比較。数値が低いほど優れています。パレートフロンティアは、各パラメータ予算で達成可能な最良の CRPS ランクを示す軌跡であり、その線上または近傍にある点は、利用可能なサイズ対品質の最適トレードオフを表します。Toto 2.0 のすべてのサイズは両方のベンチマークにおいてこのフロンティア上またはその近傍に位置し、ファミリー全体を通じてモデルサイズの増加に伴い CRPS ランクが単調に向上しています。
![]() image CRPS ランクとパラメータ数の関係(左:BOOM、右:GIFT-Eval)における主要なファウンデーションモデルの比較。数値が低いほど優れています。パレートフロンティアは、各パラメータ予算で達成可能な最良の CRPS ランクを示す軌跡であり、その線上または近傍にある点は、利用可能なサイズ対品質の最適トレードオフを表します。Toto 2.0 のすべてのサイズは両方のベンチマークにおいてこのフロンティア上またはその近傍に位置し、ファミリー全体を通じてモデルサイズの増加に伴い CRPS ランクが単調に向上しています。
image CRPS ランクとパラメータ数の関係(左:BOOM、右:GIFT-Eval)における主要なファウンデーションモデルの比較。数値が低いほど優れています。パレートフロンティアは、各パラメータ予算で達成可能な最良の CRPS ランクを示す軌跡であり、その線上または近傍にある点は、利用可能なサイズ対品質の最適トレードオフを表します。Toto 2.0 のすべてのサイズは両方のベンチマークにおいてこのフロンティア上またはその近傍に位置し、ファミリー全体を通じてモデルサイズの増加に伴い CRPS ランクが単調に向上しています。
本記事ではまず、結果とスケーリングの振る舞いについて解説し、推論レイテンシの改善や長期ホライズンにおける安定性を含めて説明します。その後、TSFM(時系列予測モデル)における次のボトルネックと機会がどこにあるか、すなわち古典的なベースラインとの長期ホライズンのギャップを埋めること、データのキュレーション、下流の価値を追跡する評価手法、そしてマルチモーダル性について詳しく詳述します。まもなく、トレーニングデータやアーキテクチャ・トレーニングレシピの詳細、および小規模なプロキシモデルで一度ハイパーパラメータを調整する u-μP ハイパーパラメータ転送パイプラインに関する技術レポートを公開予定です。
Toto 2.0 モデルの重みと、分散型 u-μP トレーニング用のインフラストラクチャライブラリ (dd_unit_scaling) は、どちらも Apache 2.0 ライセンスの下で利用可能です。
結果
Toto 2.0 は、BOOM、GIFT-Eval、および TIME において、新たな最先端性能を達成しました。BOOM では、すべてのサイズがパレートフロンティア上に位置しています。GIFT-Eval のファウンデーションモデルの中では、Toto 2.0 の3つの最大サイズが首位を独占しています。微調整済み、アンサンブル、およびエージェント型システムを含むより広範なリーダーボードでは、微調整済みの 2.5B (FT) と「Toto 2.0 Family and Friends」(FnF) アンサンブルが、堂々と上位2位を獲得しました。TIME では、Toto 2.0 の3つの最大バリアントがトップランクを占めています。
すべてのベンチマークでは複数の指標における結果が報告されています。CRPS(Continuous Ranked Probability Score)は確率的予測の品質を測定し、将来の値に対する予測分布が観測された結果とどの程度整合しているかを評価します。これは、本番環境での予測ユースケースに最も直接的に関連する指標です。MASE(Mean Absolute Scaled Error)は、単純な季節ベースラインに対して正規化されたポイント予測の精度を測定します。指標がランクとして報告される場合、スコアはすべてのベンチマークデータセット全体で平均化され、異種データ間での比較が可能になります。
BOOM
BOOM は、CPU、メモリ、リクエストレイテンシ、エラーレートといった観測可能性メトリクスに基づく予測を評価します。これらは、本番環境の監視システムが重視するシグナルです。
CRPS ランク、CRPS、MASE のすべての指標において BOOM 結果が顕著に向上し、数値が低いほど優れています。Toto 2.0 の全 5 サイズは、あらゆる指標で他のすべてのファウンデーションモデルを上回っています。Toto 2.0 22m は、パラメータ数が約 7 分の 1という規模でありながら、3 つの指標すべてにおいて Toto 1.0 と同等かそれ以上の性能を発揮しています。Toto モデルは紫色で塗りつぶされています。
![]() image CRPS ランク、CRPS、MASE のすべての指標において BOOM 結果が顕著に向上し、数値が低いほど優れています。Toto 2.0 の全 5 サイズは、あらゆる指標で他のすべてのファウンデーションモデルを上回っています。Toto 2.0 22m は、パラメータ数が約 7 分の 1という規模でありながら、3 つの指標すべてにおいて Toto 1.0 と同等かそれ以上の性能を発揮しています。Toto モデルは紫色で塗りつぶされています。
image CRPS ランク、CRPS、MASE のすべての指標において BOOM 結果が顕著に向上し、数値が低いほど優れています。Toto 2.0 の全 5 サイズは、あらゆる指標で他のすべてのファウンデーションモデルを上回っています。Toto 2.0 22m は、パラメータ数が約 7 分の 1という規模でありながら、3 つの指標すべてにおいて Toto 1.0 と同等かそれ以上の性能を発揮しています。Toto モデルは紫色で塗りつぶされています。
すべての Toto 2.0 サイズは、BOOM におけるパレートフロンティア(最適解の集合)上に位置しています。つまり、特定のパラメータ数において、より優れた予測を生成する他のファウンデーションモデルは存在しません。3 つの最大サイズがチャートをリードしており、CRPS ランクはそれぞれ 3.88 (2.5B)、3.96 (1B)、4.25 (313m) です。これらに続く 22m モデルは 5.52 のスコアで、すでに Toto 1.0 (6.94) を上回っており、前世代と比較してパラメータ効率において 7 倍の改善を達成しています。また、4m モデルは 7.17 のスコアであり、Toto 1.0 や Chronos-2 (7.39) と競合できる性能を持ちながら、サイズはそれらの 30〜40 分の 1という非常に小さい規模であるため、エッジデバイスでの展開に適した強力な選択肢となっています。
GIFT-Eval: ファウンデーションモデル
GIFT-Eval は、エネルギー、小売、気象、金融などの分野にわたる 97 のデータセットをカバーする汎用予測ベンチマークです。特筆すべきは、Toto 2.0 ベースモデルがこれらの分野のいずれかの公開データを学習していないことです。
GIFT-Eval の結果は、ファウンデーションモデルのみを対象にフィルタリングしたものであり(微調整済み、アンサンブル、エージェント型システムは除外)、CRPS ランク、MASE ランク、CRPS、および MASE について示されています。数値が低いほど優れています。Toto 2.0 のサイズは紫色で強調表示されています。3 つの最大の Toto 2.0 サイズが CRPS ランクで首位を争い、一方 2.5B が MASE ランクで首位に立っています。
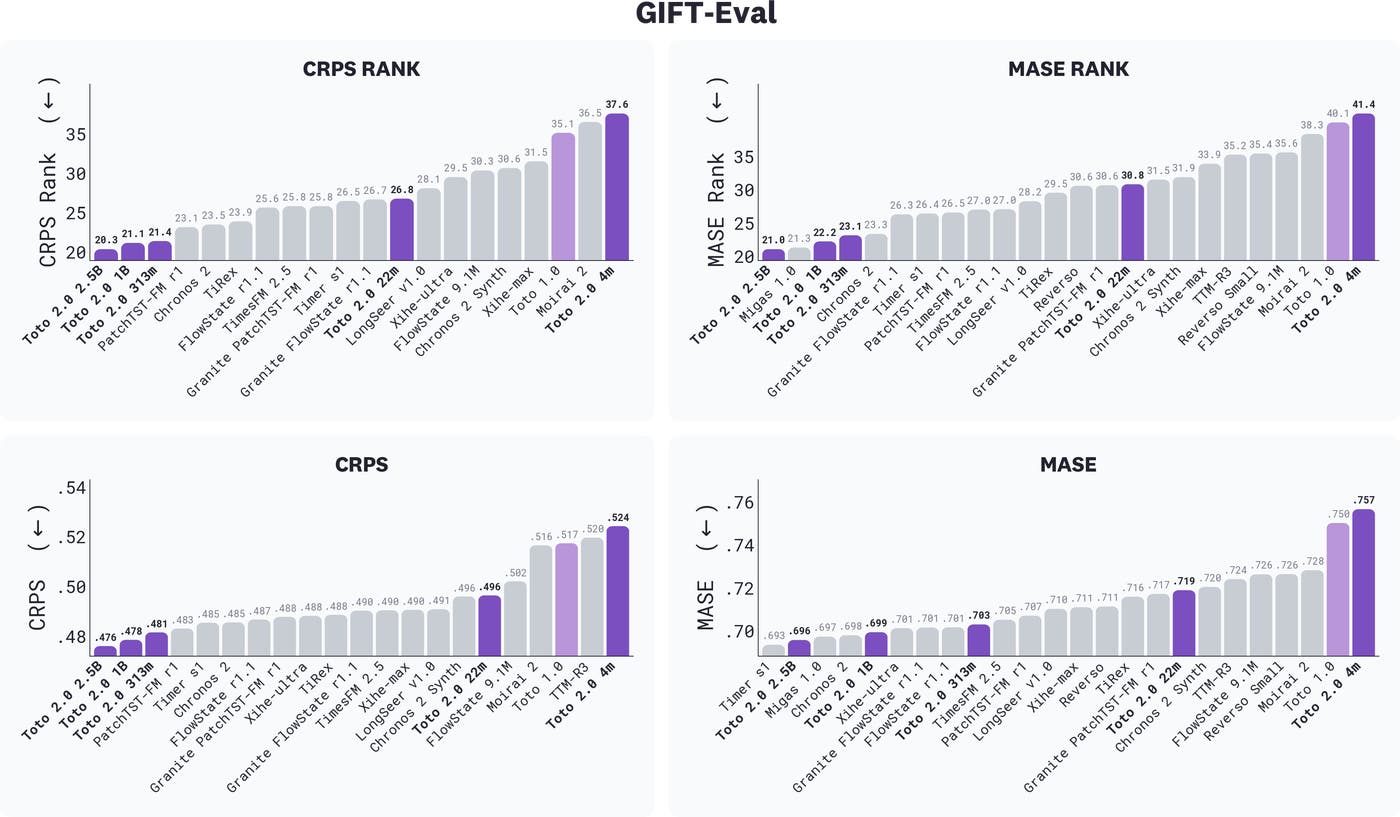 image GIFT-Eval の結果は、ファウンデーションモデルのみを対象にフィルタリングしたものであり(微調整済み、アンサンブル、エージェント型システムは除外)、CRPS ランク、MASE ランク、CRPS、および MASE について示されています。数値が低いほど優れています。Toto 2.0 のサイズは紫色で強調表示されています。3 つの最大の Toto 2.0 サイズが CRPS ランクで首位を争い、一方 2.5B が MASE ランクで首位に立っています。
image GIFT-Eval の結果は、ファウンデーションモデルのみを対象にフィルタリングしたものであり(微調整済み、アンサンブル、エージェント型システムは除外)、CRPS ランク、MASE ランク、CRPS、および MASE について示されています。数値が低いほど優れています。Toto 2.0 のサイズは紫色で強調表示されています。3 つの最大の Toto 2.0 サイズが CRPS ランクで首位を争い、一方 2.5B が MASE ランクで首位に立っています。
Toto 2.0 はファウンデーションモデルの中で第1位を獲得しています。CRPS ランクにおけるスコアは、最大の3サイズがそれぞれ 19.5(2.5B)、20.3(1B)、20.5(313m)であり、313m と次点のファウンデーションモデルである PatchTST-FM r1 [^8](22.1)との間には 1.6 ポイントの開きがあります。強力な競合相手である Chronos-2 は 22.4 です。また、22m のスコアは 25.7 で、Toto 1.0(33.9)を 8 ポイント上回っています。すべてのサイズにおいて、ランク指標では下位のモデルよりも厳密に改善されています。
GIFT-Eval: 微調整済みモデル
事前学習済みファウンデーションモデルに加えて、GIFT-Eval リーダーボードには、ベンチマークの公式トレーニングスプリット上で微調整されたファウンデーションモデル(finetuned foundation models)や、複数のファウンデーションモデルを組み合わせるアジェンティック手法およびアンサンブル手法のエントリーも含まれています。Toto 2.0 の 5 つのベースモデルは、微調整済みモデルの出発点として機能します。Toto ベースモデルが下流タスクのためにいかに容易に微調整可能かを確認するため、分布内データ(in-distribution data)を利用する 2 つのアプローチを検討しました。1 つ目は GIFT-Eval のトレーニングスプリットを含む混合データ上で単一モデルを微調整する方法、もう 1 つ目は学習されたウィンドウごとの重み付けスキームを用いて複数のモデルをアンサンブルする方法です。両方ともリーダーボードの上位にランクインし、CRPS と MASE の両方で、それぞれアンサンブルが 1 位、微調整が 2 位を獲得しました。
GIFT-Eval リーダーボードは、ファウンデーションモデル、ファインチューニング済みモデル、アンサンブル、そしてエージェント型システムを含むすべての提出タイプを表示しています。このリーダーボードでは、「ファインチューニング済み」という用語は、アンサンブルやエージェント型システムも含め、GIFT-Eval のトレーニング分割を使用するあらゆるモデルを指す包括的な用語として使用されています。Toto 2.0 のサイズは紫色でハイライトされ、ファインチューニング済みモデルはピンク色の枠線で囲まれています。Toto 2.0 FnF は CRPS ランク、MASE ランク、CRPS、および MASE のすべての項目で第1位を獲得し、Toto 2.0 2.5B-FT 単独でも以前のリーダーボードエントリーすべてを上回る第2位にランクインしています。
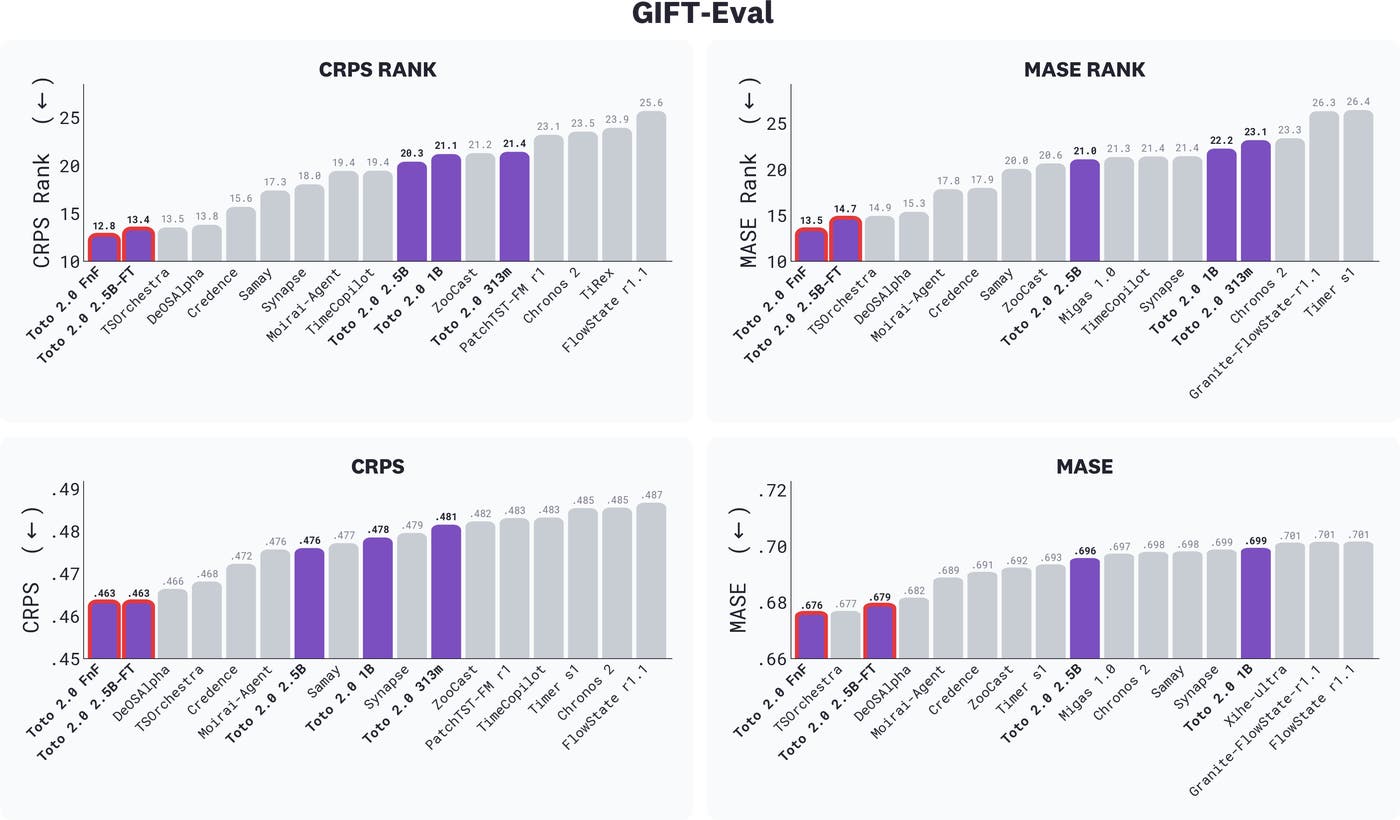 image GIFT-Eval リーダーボードは、ファウンデーションモデル、ファインチューニング済みモデル、アンサンブル、そしてエージェント型システムを含むすべての提出タイプを表示しています。このリーダーボードでは、「ファインチューニング済み」という用語は、アンサンブルやエージェント型システムも含め、GIFT-Eval のトレーニング分割を使用するあらゆるモデルを指す包括的な用語として使用されています。Toto 2.0 のサイズは紫色でハイライトされ、ファインチューニング済みモデルはピンク色の枠線で囲まれています。Toto 2.0 FnF は CRPS ランク、MASE ランク、CRPS、および MASE のすべての項目で第1位を獲得し、Toto 2.0 2.5B-FT 単独でも以前のリーダーボードエントリーすべてを上回る第2位にランクインしています。
image GIFT-Eval リーダーボードは、ファウンデーションモデル、ファインチューニング済みモデル、アンサンブル、そしてエージェント型システムを含むすべての提出タイプを表示しています。このリーダーボードでは、「ファインチューニング済み」という用語は、アンサンブルやエージェント型システムも含め、GIFT-Eval のトレーニング分割を使用するあらゆるモデルを指す包括的な用語として使用されています。Toto 2.0 のサイズは紫色でハイライトされ、ファインチューニング済みモデルはピンク色の枠線で囲まれています。Toto 2.0 FnF は CRPS ランク、MASE ランク、CRPS、および MASE のすべての項目で第1位を獲得し、Toto 2.0 2.5B-FT 単独でも以前のリーダーボードエントリーすべてを上回る第2位にランクインしています。
アンサンブルはまず GIFT-Eval リーダーボードで、微調整済みの 2.5B モデルを上回ります。しかし、より興味深い発見は、そのアンサンブルの「内部」に何があるかです。メタ学習者のソフトマックス重みは、各候補モデルが予測に対して実際にどの程度貢献しているかを明らかにします。Toto 2.0 ファミリーはアンサンブルにおける最大の貢献者であり、平均して予測の 39% を占めています。これはプール内の他のあらゆるモデル(Chronos 2 は 32%)や、残りの 4 つのオープンソースモデルを合わせたものよりも多い数値です。この組み合わせのほぼ 40% が一貫して Toto にルーティングされているという事実は、Toto がプール内の他モデルが捉えられないパターンをキャプチャする上で独自の役割を果たしていることを示しています。つまり、メタ学習者が自由にすべての重みを調整できる場合、他のどのソースよりも Toto ファミリーにより多くの重み(コスト)を割くことになります。
TIME は、確立されたベンチマークに影響を与えるテストセット汚染を緩和するために特別に選ばれた「新鮮な」データセットから構築された、最近のタスク中心のゼロショット予測ベンチマークです。Toto 2.0 はリーダーボードの上位を独占し、2.5B、313m、および 1B モデルがすべての TIME メトリックでトップ 3 を占めています。次に優れた外部ファウンデーションモデルは、1B モデルに明確な差をつけて後塵を拝しています。22m モデルはランクメトリックで 5 位に入り、テストした以前の世代のあらゆるファウンデーションモデルを上回っており、22m から上のすべてのサイズが Toto 1.0 を上回る性能を示しました。
TIME における CRPS ランク、MASE ランク、CRPS、および MASE の結果。数値が小さいほど優れています。Toto 2.0 のサイズは紫色で強調表示されています。すべての指標において 2.5B が Toto 2.0 の中で最良のサイズであり、厳密な単調性をわずかに逸脱しているのは 313m で、これは 1B をわずかに上回っています。
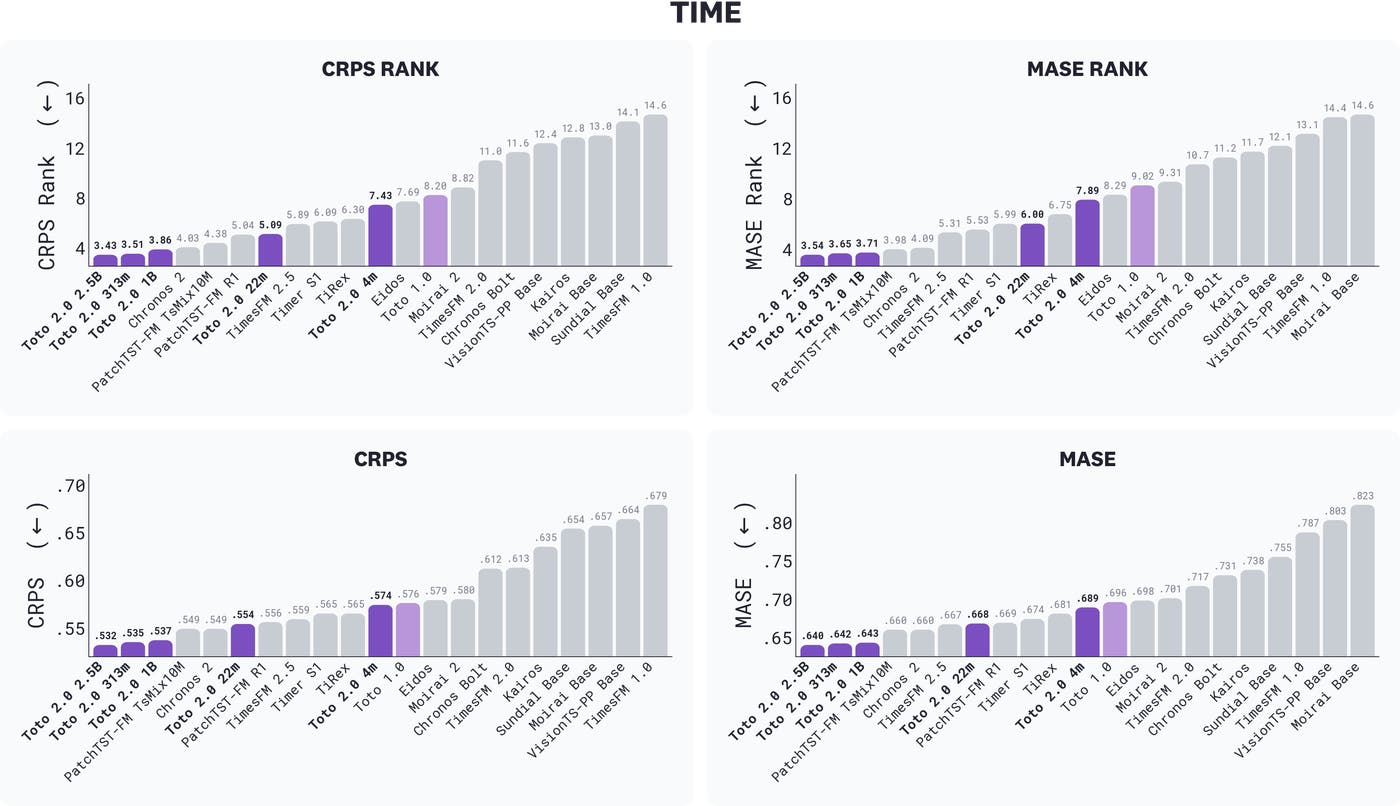 image TIME における CRPS ランク、MASE ランク、CRPS、および MASE の結果。数値が小さいほど優れています。Toto 2.0 のサイズは紫色で強調表示されています。すべての指標において 2.5B が Toto 2.0 の中で最良のサイズであり、厳密な単調性をわずかに逸脱しているのは 313m で、これは 1B をわずかに上回っています。
image TIME における CRPS ランク、MASE ランク、CRPS、および MASE の結果。数値が小さいほど優れています。Toto 2.0 のサイズは紫色で強調表示されています。すべての指標において 2.5B が Toto 2.0 の中で最良のサイズであり、厳密な単調性をわずかに逸脱しているのは 313m で、これは 1B をわずかに上回っています。
推論レイテンシ
Toto 2.0 は、Toto 1.0 のバックボーンに対する一連の改良を含んでいます。その一つが連続パッチマスキング(CPM: Contiguous Patch Masking)で、これによりモデルはステップバイステップではなく、並列パス全体で予測を完了できるようになります。CPM は予測品質を向上させるだけでなく、Toto 2.0 を劇的に高速化します。1024 ステップの予測を行う場合、Toto 1.0 では最大 16 の逐次的自己回帰ステップが必要ですが、Toto 2.0 のシングルパスモードでは単一のフォワードパスで完了します。
GIFT-Eval における前世代の SOTA(State-of-the-Art: 最先端)モデルである Chronos-2 および Toto 1.0 と比較して、フォワードパスのレイテンシを評価しました。この予測期間において、Toto 2.0 のすべてのサイズは Toto 1.0 よりも大幅に高速です。313m モデルは、パラメータ数 120m の Chronos-2 とほぼ同等のレイテンシで動作します。2048 以上の予測期間においても、シングルパスモードの 2.5B でさえ Chronos-2 よりも高速です。
左:予測長 1024 における順伝播レイテンシとパラメータ数の関係。Toto 2.0 のすべてのサイズが Toto 1.0 より大幅に高速です。右:予測長(対数スケール)に対する順伝播レイテンシ。Toto 2.0 は、合成信号において最適であると見出した 768 ポイントの予測長まで、シングルパスモードで平坦な性能を維持します。
<img loading="lazy" srcset="https://web-assets.dd-static.net/42588/1778698889-f6-forward-pass-latency-vs-parameter-count.png?format=auto&fit=bounds&quality=75&disable=upscale&width=1026&dpr=1 1x, https://web-assets.dd-static.net/42588/1778698889-f6-forward-pass-latency-vs-parameter-count.png?format=auto&fit=bounds&quality=75&disable=upscale&width=1026&dpr=1.5 1.5x, https://web-assets.dd-static.net/42588/1778698889-f6-forward-pass-latency-vs-parameter-count.png?format=auto&fit=bounds&quality=75&disable=upscale&width=1026&dpr=2 2x, https://web-assets.dd-static.net/42588/1778
原文を表示
Today we’re releasing Toto 2, a family of open-weights time series forecasting models, on Hugging Face. Spanning 4m to 2.5B parameters, Toto 2.0 is designed to answer a simple and open question: Can time series foundation models (TSFMs) improve as they scale? Our results show they can. The highlights:
- Scaling that works. Every size improves on the one below it, with no sign of saturation at 2.5B.
- Best in class on every benchmark we tested. Toto 2.0 takes the top spots on BOOM (Datadog's observability forecasting benchmark), GIFT-Eval (the standard general-purpose benchmark), and TIME (a new contamination-resistant zero-shot benchmark).
- A generational jump from Toto 1.0. Toto 2.0 is 7× more parameter-efficient at matching quality and dramatically faster at inference time.
- Trained on observability and synthetic data, generalizes broadly. Toto 2.0 does not see any public forecasting data during pretraining, yet leads the field on general-purpose benchmarks.
This post first walks through the results and scaling behavior, including inference latency improvements and long-horizon stability. It then details where we think the next set of bottlenecks and opportunities for TSFMs are: closing the long-horizon gap with classical baselines, data curation, evaluation that tracks downstream value, and multimodality. We will soon release a technical report providing more details on our training data, our architectural and training recipes, and our u-μP hyperparameter transfer pipeline that tunes hyperparameters once on a small proxy model.
Both the Toto 2.0 model weights and our infrastructure library for distributed u-μP training (dd_unit_scaling) are available under the Apache 2.0 license.
Results
Toto 2.0 sets a new state of the art on BOOM, GIFT-Eval, and TIME. On BOOM, every size sits on the Pareto frontier. Among foundation models on GIFT-Eval, the three largest Toto 2.0 sizes lead the field. On the broader leaderboard that includes finetuned, ensemble, and agentic systems, our finetuned 2.5B (FT) and "Toto 2.0 Family and Friends" (FnF) ensemble take the top two slots outright. On TIME, the three largest Toto 2.0 variants hold top ranks.
All benchmarks report results across several metrics. CRPS (Continuous Ranked Probability Score) measures the quality of a probabilistic forecast, scoring how well a predicted distribution over future values aligns with observed outcomes. It is the metric most directly relevant to production forecasting use cases. MASE (Mean Absolute Scaled Error) measures point forecast accuracy, normalized against a naive seasonal baseline. Where metrics are reported as ranks, scores are averaged across all benchmark datasets to enable comparison across heterogeneous data.
BOOM
BOOM evaluates forecasting on observability metrics like CPU, memory, request latency, and error rates. These are the signals production monitoring systems care about.
Every Toto 2.0 size sits on the Pareto frontier of BOOM: at any given parameter count, no other foundation model produces better forecasts. The three largest sizes lead the chart, with CRPS ranks of 3.88 (2.5B), 3.96 (1B), and 4.25 (313m). Behind them, the 22m at 5.52 already clears Toto 1.0 (6.94), establishing a 7× parameter-efficiency improvement over the previous generation. The 4m, at 7.17, is competitive with Toto 1.0 and Chronos-2 (7.39) despite being 30–40× smaller, making it a strong option for edge deployment.
GIFT-Eval: Foundation models
GIFT-Eval is a general-purpose forecasting benchmark spanning 97 datasets across domains such as energy, retail, weather, and finance. Notably, Toto 2.0 base models are not trained on any public data from these domains.
Toto 2.0 ranks first among foundation models. The three largest sizes score 19.5 (2.5B), 20.3 (1B), and 20.5 (313m) on CRPS rank, with a 1.6-point gap separating the 313m from the next best foundation model, PatchTST-FM r1 [^8] at 22.1. Chronos-2, a strong competitor, sits at 22.4. The 22m at 25.7 beats Toto 1.0 (33.9) by 8 points. Every size strictly improves on the one below it on rank metrics.
GIFT-Eval: Finetuned models
In addition to pretrained foundation models, the GIFT-Eval leaderboard also includes entries for finetuned foundation models (those that have been tuned on the official training split of the benchmark), as well as agentic and ensembling methods that combine multiple foundation models. The five Toto 2.0 base models serve as the starting point for our finetuned models. To see how easily Toto base models can be finetuned for downstream tasks, we explored two approaches that use in-distribution data: finetuning a single model on a mix that includes the GIFT-Eval train split, and ensembling multiple models with a learned per-window weighting scheme. Both place at the top of the leaderboard, with ensembling and finetuning taking first and second on both CRPS and MASE rank.
The ensemble takes first on the GIFT-Eval leaderboard, ahead of the finetuned 2.5B. But the more interesting finding is what’s *inside* the ensemble. The meta-learner’s softmax weights reveal what each candidate actually contributes to that prediction. The Toto 2.0 family is the largest contributor to the ensemble, accounting for 39% of predictions on average—more than any other model in the pool, including Chronos 2 (32%), and more than the four remaining open models combined. The fact that nearly 40% of that combination is consistently routed through Toto demonstrates Toto's distinctive role in capturing patterns that the rest of the pool cannot. In other words: when the meta-learner is free to weight everything it has, it spends more on the Toto family than on any other source.
TIME
TIME is a recent, task-centric zero-shot forecasting benchmark constructed from “fresh”* *datasets specifically chosen to mitigate the test-set contamination that affects established benchmarks. Toto 2.0 sweeps the top of the leaderboard: the 2.5B, 313m, and 1B take the top three positions on every TIME metric, with the next best external foundation model trailing the 1B by a clear margin. The 22m comes in fifth on rank metrics, ahead of every prior-generation foundation model we tested, and every size from the 22m up outperforms Toto 1.0.
Inference latency
Toto 2.0 includes a series of refinements to the Toto 1.0 backbone, including contiguous patch masking (CPM), which lets the model predict an entire forecast in one parallel pass instead of step by step. CPM doesn't just improve forecast quality, it makes Toto 2.0 dramatically faster. A 1024-step forecast with Toto 1.0 requires up to 16 sequential autoregressive steps; with Toto 2.0 in single-pass mode, it's one forward pass.
We evaluate forward pass latency against Toto 1.0 and Chronos-2, the previous SOTA model on GIFT-Eval. Every Toto 2.0 size is significantly faster than Toto 1.0 at this horizon. Our 313m runs at roughly the same latency as Chronos-2 at 120m parameters. At horizons of 2048+, even the 2.5B in single-pass mode remains faster than Chronos-2.
<img loading="lazy" srcset="https://web-assets.dd-static.net/42588/1778698889-f6-forward-pass-latency-vs-parameter-count.png?format=auto&fit=bounds&quality=75&disable=upscale&width=1026&dpr=1 1x, https://web-assets.dd-static.net/42588/1778698889-f6-forward-pass-latency-vs-parameter-count.png?format=auto&fit=bounds&quality=75&disable=upscale&width=1026&dpr=1.5 1.5x, https://web-assets.dd-static.net/42588/1778698889-f6-forward-pass-latency-vs-parameter-count.png?format=auto&fit=bounds&quality=75&disable=upscale&width=1026&dpr=2 2x, https://web-assets.dd-static.net/42588/1778
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み