AI を駆使した説明と実験による脳理解の探求
Microsoft Research などが開発した GCT(Generative Causal Testing)は、LLM を用いて脳予測モデルのブラックボックスを解読し、検証可能な仮説へと変換することで、言語神経科学における「説明可能性」の課題に画期的な解決策をもたらしました。
キーポイント
ブラックボックスの可視化と言語化
脳活動予測モデルの膨大なパラメータを、LLM が解析して「食品準備」や「場所の名前」などの短く読みやすい説明に変換する手法です。
因果検証による仮説の確証
生成された説明に基づいて LLM が新たな物語を作成し、被験者に提示して脳画像で反応を検証することで、仮説の正否を直接テストします。
既存知見の再確認と新発見
既知の脳の選択性を確認するだけでなく、従来は区別が難しかった隣接領域や、対話・時計時間・測定値などに特化した前頭葉の微小領域を発見しました。
生成因果テスト(GCT)の二段階アプローチ
GCT は、予測モデルから得られた重要なフレーズを LLM で要約して仮説を生成する「説明」段階と、その仮説を検証するために新しい物語を作成し脳スキャンで検証する「検証」段階からなる。
相関関係を超えた因果性の証明
特定の脳領域の活動が、生成された物語に対してベースラインテキストよりも有意に高い場合、その説明は単なる相関ではなく真の因果テストに合格したとみなされる。
解釈不能なモデルを科学仮説へ変換
この手法は、ブラックボックス化されがちな予測モデルを、追試によって確認または反証可能な簡潔な科学的仮説へと翻訳する役割を果たす。
GCTの検証と信頼性
合成されたストーリーは対象領域を確実に活性化させ、脳予測モデルが安定しているほど説明の信頼性も高まることが確認されました。
影響分析・編集コメントを表示
影響分析
この研究は、単なる予測精度の向上にとどまらず、AI モデルを科学的理論へと変換するプロセスそのものを自動化・加速させるパラダイムシフトを示しています。これにより、神経科学における仮説生成と検証のサイクルが劇的に短縮され、脳機能の解明速度が飛躍的に向上することが期待されます。
編集コメント
「AI が科学をどう変えるか」を示す象徴的な事例であり、ブラックボックス化が進む AI モデルを、人間が理解・検証可能な形に変換する XAI の実用化における重要な一歩です。

一言で言うと
大規模言語モデル(LLM)ベースのモデルは、人間の脳が言語に対して示す反応を高い精度で予測できます。しかし、その性能を支えているものは本質的に解読不能です:それは誰にも読み取れる科学理論ではなく、膨大な数の学習されたパラメータの集合に過ぎません。
マイクロソフト研究所、カリフォルニア大学バークレー校、カリフォルニア大学サンフランシスコ校、コロンビア大学の共同研究によって開発された「生成因果テスト(Generative Causal Testing: GCT)」は、これらの脳予測モデルを凝縮し、大脳の各領域が何に反応するかという短い言語説明へと変換します。具体的には、「食品の調理」や「地名」といったフレーズです。
GCT はその後、ループを閉じます:LLM が特定の脳領域を活性化させるように設計された新しい物語を作成し、被験者がスキャナー内でそれらを聞きます。そして、その説明が正しい場合にのみ、対象領域が光り輝くのです。
実験において、GCT は既知の選択性を確認し、互換性があると考えられてきた隣接する場所処理領域を区別し、対話や時刻、測定値といった特定の概念に調整された前頭葉の微小な「マイクロ領域」を発見しました。
言語神経科学における説明可能性の問題
過去10年間、大規模言語モデル(LLM)は、人間の脳が言語にどのように反応するかを予測するための最も正確なツールとして確立されてきました。fMRIスキャナー内で人が聴くのと全く同じ物語をLLMに入力すると、そのモデルの内部表現は、皮質の個々の領域の活動 remarkably な忠実度で予測することができます。しかし、この成功には条件付きの落とし穴が伴います:誰もこれらのモデルを読むことができないのです。これらは数百万もの解読不能なパラメータであり、解釈に直接変換することはできません。脳活動を予測するモデルは、ある領域が言語に応答することを示すものの、実際に何を捉えているのか、つまり食物なのか場所なのか数値なのか、あるいは全く別の何かなのかについては何も教えてくれません。ブラックボックスモデルが普及するにつれ、予測と理解の間の隔たりは計算神経科学における中心的な問題の一つとなっています。
ブラックボックスをテスト可能な理論へ転換する
Nature Neuroscience に掲載された新しい論文において、Microsoft Research の科学者らがカリフォルニア大学バークレー校、サンフランシスコ校、コロンビア大学の研究者らと協力し、この説明可能性の危機を克服するための枠組み「生成因果テスト(Generative Causal Testing: GCT)」を紹介しました。GCT は脳予測モデルを要約し、大脳皮質の各領域が何に反応するかを短く読みやすい記述として抽出した上で、その主張を検証します。LLM が特定の脳領域を活性化させるように設計された新しい物語を作成し、被験者がスキャナー内でそれらを聴取します。もし説明が正しければ、標的とした領域が点灯します。この結果得られるのは、解釈不能な予測モデルを科学の通貨である「検証可能な仮説」へと変換する手法です。LLM が特定の脳領域を活性化させるように設計された新しい物語を作成し、被験者がスキャナー内でそれらを聴取します。もし説明が正しければ、標的とした領域が点灯します。この結果得られるのは、解釈不能な予測モデルを科学の通貨である「検証可能な仮説」へと変換する手法です。
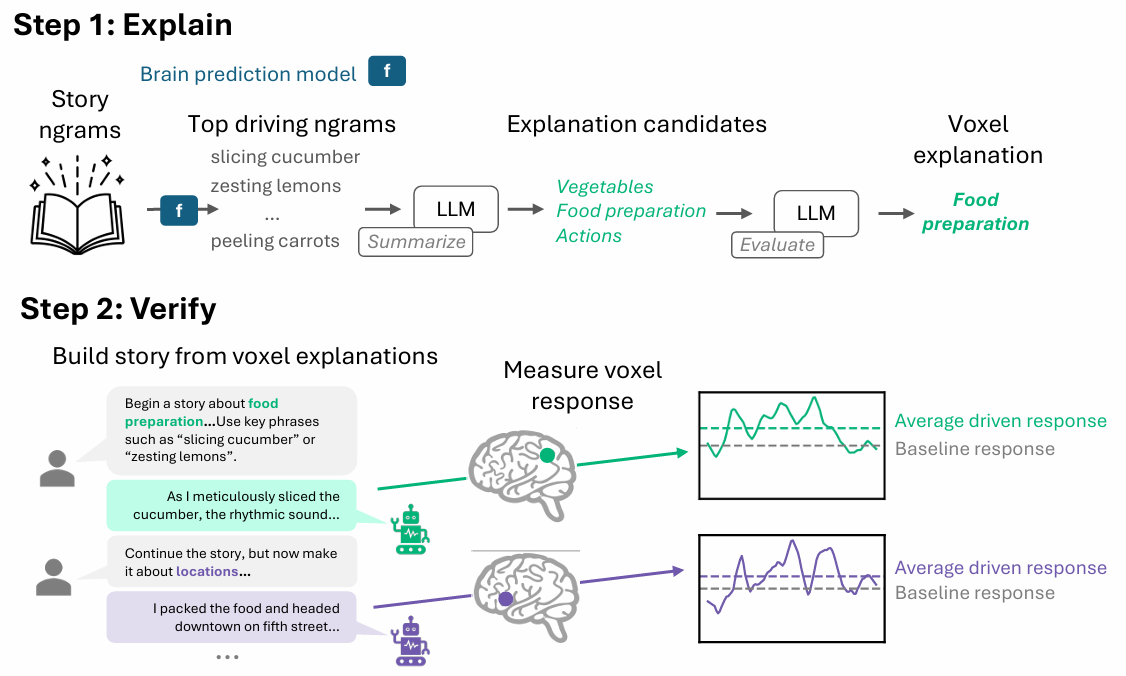 image図 1. 生成因果検証(GCT: Generative Causal Testing)の 2 つの手順。手順 1 では、脳領域の予測モデルを最も強く駆動するフレーズが LLM によって要約され、「食品調理」のような短い候補説明となる。手順 2 では、LLM がその説明に合致するように設計された新しい物語を作成し、これらの「駆動」ストーリーに対する脳領域の反応をスキャナー内で測定し、ベースラインと比較する。
image図 1. 生成因果検証(GCT: Generative Causal Testing)の 2 つの手順。手順 1 では、脳領域の予測モデルを最も強く駆動するフレーズが LLM によって要約され、「食品調理」のような短い候補説明となる。手順 2 では、LLM がその説明に合致するように設計された新しい物語を作成し、これらの「駆動」ストーリーに対する脳領域の反応をスキャナー内で測定し、ベースラインと比較する。
GCT の仕組み
GCT は 2 つの手順からなる:まず説明の生成、次に検証である。説明を生成するため、この手法は単一のボクセル(体積要素)または脳領域に対する予測モデルを出発点とし、その予測応答を最も強く駆動する短いフレーズを特定する。その後、LLM がこれらの単語を要約し、「食品調理」や「地名」といった、しばしば単一フレーズとなる簡潔な言語説明を作成する。
決定的に重要な第 2 の段階はループを閉じるものである。説明への信頼性を高めるため、GCT は LLM を用いて新しい物語を作成する。この際、各段落は脳領域の説明に従って駆動するように慎重に構成される。3 名の被験者が再びスキャナーに戻り、これらの合成されたストーリーを読み込んだ。もしある脳領域の活動が、「駆動」paragraph に対するものベースラインテキストに対して有意に大きかった場合、その説明は単なる相関関係ではなく、真の因果検証を通過したことになる。
3 人の被験者すべてにおいて、中核的なアプローチは有効でした。合成された物語は確実に標的領域をベースライン以上に引き上げ、GCT の短い説明が皮質が実際に反応する何かを捉えていることを確認しました。また、説明の信頼性は、背後にある脳予測モデルが最も強力な場所(モデルが安定しているほど、その説明がスキャナー内でより確実に検証可能である)で最も高まりました。選択性が既知の領域に対してこの手法を検証したことで、研究者たちは GCT をより困難な問いに適用しました。
 image図 2. 異なるトピックに対する GCT 物語への脳反応マップ。いくつかのマップは確立された知見を再現しています:「場所」という説明は、RSC、OPA、PPA の場所領域で強い反応を生じます。他のものは新しい仮説を独立して確認します:「食品調理」は、紡錘状顔面野(FFA)付近の腹側後頭皮質にある領域を活性化します。「誕生日」のように、既知の結果にきれいにマッピングされないものもあり、これは将来の研究に向けた方向性を示唆しています。
image図 2. 異なるトピックに対する GCT 物語への脳反応マップ。いくつかのマップは確立された知見を再現しています:「場所」という説明は、RSC、OPA、PPA の場所領域で強い反応を生じます。他のものは新しい仮説を独立して確認します:「食品調理」は、紡錘状顔面野(FFA)付近の腹側後頭皮質にある領域を活性化します。「誕生日」のように、既知の結果にきれいにマッピングされないものもあり、これは将来の研究に向けた方向性を示唆しています。
GCT はまた、長年続いていた曖昧さを解消するほど鋭いことも証明しました。場所の処理に関与する 3 つの隣接領域は、機能面が類似しているとしばしば考えられてきました:後帯状皮質(RSC)、傍海馬回りの場所野(PPA)、および後頭部場所野(OPA)です。当初は、ある領域のために書かれた物語は他の領域も活性化させました。しかし、GCT は差別的刺激(ある領域をオンにし、その隣接領域を静かに保つように設計された物語)を生成することで、これら 3 つの領域を明確に区別しました。例えば、RSC は東京やコネチカットのような固有名詞としての地名に対して、一般的な場所よりも強く反応します。これは、生来の予測モデルだけでは独自に提供できないような、微妙で領域固有な理論の一例です。
既知の領域を超えて、著者らは新しい前頭葉の「マイクロ領域」を発見しました。候補となる位置のグリッドをスキャンし、最も安定したもののみを残すことで、GCT はこれまでマッピングされていなかったこれらの領域を浮き彫りにしました。これらは驚くほど特定の概念に調整されたものであり、1 つは人々間の対話(「言った」や「伝えた」といった単語)に選択的であり、もう 1 つは時計の時刻(「1 時」など)に関する言及に、さらに別の 1 つは数値測定値(「50 フィート」など)に調整されています。これらは誰も探そうとしなかった区別ですが、この手法が仮説を提案し、即座にそれを検証できるからこそ現れたものです。
Spotlight: AI-POWERED EXPERIENCE

Microsoft のリサーチ コパイロット体験
AI を活用した体験を通じて、Microsoft における研究についてさらに詳しく知ることができます。
今すぐ始める
新しいタブで開く
示唆と今後の展望
GCT(Generalized Circuit Theory)の意義は神経科学を超えて広く及んでいます。研究者たちは現在、同じジレンマに直面することが増えています。「美しく予測できるが、説明できない」モデルです。GCT は、データ駆動型モデルが探究の終着点である必要はないことを示しています。それは読みやすく実験的に検証可能な理論へと凝縮可能であり、その理論は、必要な時に新たな実験を生成することで現実と照合することができます。
神経科学に特化して言えば、GCT は皮質マッピングのためのより迅速で仮説に富む道筋を示唆しています。そこでは AI システムが脳領域が何を符号化する可能性があるかを提案し、クローズドループ実験によってその提案が単一の研究内で確認または否定されます。この「生成と検証」の哲学は、強力な予測モデルが理解能力を凌駕している他の分野にも拡張できるでしょう。より広い教訓として希望が持てます。科学におけるブラックボックスモデルの台頭が、必ずしも人間が読みやすい理論の後退を意味するわけではないのです。適切な枠組みさえあれば、両者は共に発展していくことができます。
謝辞
本研究は、Microsoft Research、UC Berkeley(Alex Huth, Bin Yu, Sihang Guo, Aliyah Hsu)、Columbia University(RJ Antonello、共同リーダー)、および UCSF(Shailee Jain)間での協力によって成し遂げられました。また、本研究を可能にしたツールやデータセットを提供した研究参加者ならびに言語神経科学コミュニティ全体にも感謝申し上げます。
論文はこちらで読むことができます(新しいタブで開く):「Generative causal testing to bridge data-driven models and scientific theories in language neuroscience」(言語神経科学におけるデータ駆動型モデルと科学的理論を橋渡しする生成因果テスト)、Nature Neuroscience に採択済み。コードは Github で公開されています(新しいタブで開く)。
新しいタブで開きます。本記事「AI 駆動の説明と実験による脳の理解」は、Microsoft Research の投稿として最初に掲載されました。
原文を表示
At a glance
LLM-based models can predict the human brain’s responses to language with high accuracy. But what drives that performance is essentially unreadable: a vast collection of learned parameters, not scientific theories anyone can read.
Generative causal testing (GCT), developed in a collaboration between Microsoft Research, the University of California, Berkeley, the University of California, San Francisco, and Columbia University, distills these brain-prediction models into short verbal explanations of what each patch of cortex responds to: phrases like “food preparation” or “location names.”
GCT then closes the loop: an LLM writes new stories designed to activate a targeted brain area, subjects hear them in the scanner, and the region lights up only if the explanation is right.
In experiments, GCT confirmed known selectivity, teased apart neighboring place-processing regions long thought interchangeable, and revealed tiny prefrontal “micro-regions” tuned to specific concepts like dialogue, clock times, and measurements.
The explainability problem in language neuroscience
Over the past decade, LLMs have become the most accurate tools we have for predicting how the human brain responds to language. Feed an LLM the same story a person hears in an fMRI scanner, and the model’s internal representations can predict the activity of individual patches of cortex with remarkable fidelity. But this success comes with a catch: nobody can read these models. They are millions of inscrutable parameters that can’t be directly translated into interpretations. A model that predicts brain activity tells us that a region responds to language, but not what it is actually picking up on, whether it’s food, places, numbers, or something else entirely. As black-box models spread, the gap between prediction and understanding has become one of the central problems in computational neuroscience.
Turning black boxes into testable theories
In a new paper accepted in Nature Neuroscience, Microsoft Research scientists, in collaboration with scientists at the University of California, Berkeley, University of California, San Francisco, and Columbia University, introduce a framework to overcome this explainability crisis: generative causal testing (GCT). GCT distills brain-prediction models into short, readable accounts of what each patch of cortex responds to, then tests those claims. An LLM writes new stories engineered to activate a specific brain area, subjects hear them in the scanner, and if the explanation is correct, the targeted region lights up. The result is a method that translates uninterpretable predictive models back into the currency of science: concise hypotheses that can be confirmed or refuted in a follow-up experiment. An LLM writes new stories engineered to activate a specific brain area, subjects hear them in the scanner, and if the explanation is correct, the targeted region lights up. The result is a method that translates uninterpretable predictive models back into the currency of science: concise hypotheses that can be confirmed or refuted in a follow-up experiment.
imageFigure 1. The two steps of generative causal testing (GCT). In Step 1, the phrases that most strongly drive a brain region’s predictive model are summarized by an LLM into a short candidate explanation, such as “food preparation.” In Step 2, an LLM writes new stories designed to match that explanation, and the region’s response to these “driving” stories is measured in the scanner and compared against baseline.
How GCT works
GCT has two steps: explanation, then verification. To generate an explanation, the method starts from a predictive model for a single voxel or region and identifies the short phrases that most strongly drive its predicted response. An LLM then summarizes those words into a concise verbal explanation, often a single phrase such as “food preparation” or “location names.”
The crucial second stage closes the loop. To build trust in the explanation, GCT uses an LLM to write new stories in which each paragraph is carefully constructed to drive a brain region according to its explanation. Three subjects returned to the scanner to read these synthetic stories. If a region’s activity to its “driving” paragraphs was significantly greater than to baseline text, the explanation passed a genuine causal test, not just a correlational one.
Across all three subjects, the core approach held up: the synthetic stories reliably drove their target regions above baseline, confirming that GCT’s short explanations capture something the cortex genuinely responds to. The explanations were also most trustworthy where the underlying brain-prediction models were strongest (the more stable the model, the more reliably its explanation could be confirmed in the scanner). With the method validated on regions whose selectivity was already known, the researchers turned GCT on harder questions.
imageFigure 2. Brain response maps to GCT stories for different topics. Some maps recover well-established findings: the explanation “Locations” produces strong responses in the place areas RSC, OPA, and PPA. Others independently confirm newer hypotheses: “Food Preparation” activates a region in ventral occipital cortex near the fusiform face area (FFA). Some like (“Birthdays”) do not map cleanly onto any known result, pointing toward directions for future research.
GCT also proved sharp enough to settle long-standing ambiguities. Three neighboring regions involved in processing places have often been treated as functionally similar: the retrosplenial cortex (RSC), the parahippocampal place area (PPA), and the occipital place area (OPA). At first, stories written for one region also activated the others. But by generating differential stimuli (stories designed to switch one region on while keeping its neighbors quiet), GCT teased the three apart. For example, RSC responds more strongly to proper noun location names, like Tokyo or Connecticut, rather than general location. This is the kind of nuanced, region-specific theory that a raw predictive model cannot provide on its own.
Beyond known regions, the authors discovered new prefrontal “micro-regions.” By scanning a grid of candidate locations and keeping only the most stable ones, GCT surfaced these previously unmapped regions tuned to remarkably specific concepts: one selective for dialogue between people (words like “said” or “told”), one for mentions of clock times (“one o’clock”), and one for numeric measurements (“50 feet”). These are distinctions no one had gone looking for; they emerged because the method could propose a hypothesis and immediately test it.
Spotlight: AI-POWERED EXPERIENCE
image
Microsoft research copilot experience
Discover more about research at Microsoft through our AI-powered experience
Start now
Opens in a new tab
Implications and looking forward
The significance of GCT reaches well beyond neuroscience. Researchers increasingly face the same dilemma: a model that predicts beautifully but explains nothing. GCT shows that a data-driven model need not be the end of inquiry; it can be distilled into a readable, experimentally testable theory, and that theory can be checked against reality by generating new experiments on demand.
For neuroscience specifically, GCT points toward a faster, more hypothesis-rich way of mapping the cortex—one where an AI system proposes what a brain region might encode and a closed-loop experiment confirms or rejects it within a single study. The same generate-and-verify philosophy could extend to other domains where powerful predictive models have outrun our ability to understand them. The broader lesson is hopeful: the rise of black-box models in science does not necessarily mean the retreat of human-readable theory. With the right framework, the two can advance together.
Acknowledgements
This work was a collaboration across Microsoft Research, UC Berkeley (Alex Huth, Bin Yu, Sihang Guo, and Aliyah Hsu), Columbia University (RJ Antonello, co-lead), and UCSF (Shailee Jain). We also thank the study participants and the broader language-neuroscience community whose tools and datasets made this research possible.
Read the paper (opens in new tab): “Generative causal testing to bridge data-driven models and scientific theories in language neuroscience,” accepted in Nature Neuroscience and the code on Github (opens in new tab).
Opens in a new tabThe post Understanding the brain with AI-driven explanations and experiments appeared first on Microsoft Research.
関連記事
NVIDIA ACE を活用した KRAFTON の共演可能キャラクター「PUBG Ally」の構築方法
ゲーム開発会社 KRAFTON は、NVIDIA の AI 技術プラットフォーム「ACE」を活用し、プレイヤーと対話可能な共演可能キャラクター「PUBG Ally」を PUBG に実装した。
Gemini を活用して Google スプレッドシートを作成する方法
Google が提供する AI モデル「Gemini」を用いて、ユーザーが直接 Google スプレッドシートを生成・操作する機能の利用方法について解説している。
Anthropic の Claude が有料消費者層で ChatGPT を凌駕し市場を席巻
Anthropic が提供する AI チャットボット「Claude」が、従来 ChatGPT が独占していた有料顧客市場において支持を集め、シェア拡大に成功していることが示された。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み