効率的なファインチューニングのためのLoRAターゲットモジュール選択の最適化
Amazon Scienceの調査により、LLMのLoRAファインチューニングにおいて「o_proj」モジュールへのアダプター挿入が、精度と効率の最適トレードオフを実現する単一ターゲットとして最良であることが実証された。
キーポイント
LoRA適用モジュールのトレードオフ
より多くの大規模モジュールをターゲットにすると性能は向上するがコストも増加するため、最適化されたサブセットの選択が効率化の鍵となる。
o_projモジュールの最適解
アブレーション研究の結果、アテンションヘッド間の表現を統合するo_projへのアダプター挿入が、精度維持と計算コスト削減の最佳バランスを示した。
Transformer構造への適用枠組み
アテンション機構とフィードフォワードネットワークからなるTransformerブロックに対し、軽量化アダプターの挿入位置を体系化し標準構成を提案した。
実務適用におけるコスト削減効果
ベースモデルの共有、推論コストの削減、マルチアダプター並列推論などを可能にし、企業ユースケースに即した実用的なフレームワークを提供する。
モジュール組み合わせによる精度とレイテンシのトレードオフ
`qkv`単体は最小レイテンシを実現する一方、`o_proj`やFFN層(`fc1`/`fc2`)を追加することで精度が向上するが、レイテンシも比例して増加する。
用途に応じた最適なターゲットモジュールの選択
一般的なNLPタスクには`qkv + o_proj`が最適バランスを示し、複雑な生成や事実知識の取得にはFFN層の追加が不可欠である。
全モジュール適用は実用性に欠ける
全モジュールをLoRA対象とすると精度は最大になるが、レイテンシが大幅に増加し、実運用ではほぼ正当化されない。
影響分析・編集コメントを表示
影響分析
この研究は、LoRAファインチューニングにおける「どこにアダプターを挿入するか」という実務上の長年の課題に対し、データ駆動型のアブレーション研究で明確な回答を示した。o_projへの最適化は、企業レベルのLLMカスタマイズコストを大幅に削減しつつ性能を維持する道筋を開き、業界全体のファインチューニング標準化と実装普及に寄与すると期待される。
編集コメント
LoRAの適用位置を「o_proj」に限定する知見は、リソース制約のある現場にとって即戦力となる実用的な成果だ。今後は他のアーキテクチャやマルチモーダルモデルへの適用検証も期待される。
タイトル: 効率的なファインチューニングのためのLoRAターゲットモジュール選択の最適化
低ランク適応 (Low-Rank Adaptation, LoRA) を用いてAIモデルをファインチューニングする際の精度と効率性のトレードオフについて、アブレーション研究が明らかにした。
機械学習
Rushil Anirudh Anjie Fang Bhoomit Vasani March 19, 10:39 AM March 19, 10:39 AM
特定のタスクに対して大規模言語モデル (LLM) をファインチューニングするには、数兆トークンにわたって数十億のパラメータを更新する必要があり、それに伴うGPUリソースと時間のコストがかかる。
低ランク適応 (LoRA) は、元のモデルの重みを凍結したまま、特定のモデルサブレイヤー(モジュール)に軽量な行列を導入する、より効率的な手法である。これらの行列(一般にアダプターと呼ばれる)はモジュールの重みを修正し、効率的なファインチューニングだけでなく、オンデマンドでのモデル提供も可能にする。これにより、推論コストが劇的に削減される。また、GPU間でのベースモデルの共有によりメモリ要件が削減され、ダウンロードのオーバーヘッドが低減し、複数のアダプターにわたる並列推論が実現する。
問題は、モデル全体のどこにこれらのアダプターを挿入するかである。経験的に、より多く、より大きなモジュールをターゲットにすると、カスタマイズの柔軟性が高まるため、性能が向上する傾向がある。しかし、それは同時に学習と推論のコストを増加させる。より小さく適切に選択されたサブセットを使用することで、大幅に優れた効率性を保ちつつ、ほとんどの性能向上を維持できる。
ベースモデルとしてAmazonのNova 2.0 Liteマルチモーダル推論LLMを使用し、大多数の顧客ユースケースで効果的に機能する標準化されたターゲットモジュール構成のサブセットを特定することを目標とした。アブレーション研究を通じて、o_projとして知られるモジュールを、アダプターを追加することで効率性と精度の間で最適なトレードオフを達成する単一のモジュールとして特定した(o_projは、アテンションヘッド間の表現を混合し、モデルの残りの部分が理解できる単一のまとまった形式に変換する線形変換である)。
トランスフォーマーアーキテクチャ
トランスフォーマーモデル——AIの最近の顕著な進歩のすべてを担っているモデル——は、主に複数回繰り返されるブロックで構成されている。各ブロックには、さらに2つの主要なコンポーネントがある:以前に見たトークンが現在処理されているトークンに対してどれだけ関連性があるかを決定するアテンションメカニズムと、アテンションメカニズムの出力に対して追加の処理を行う従来のニューラルネットワークであるフィードフォワードネットワークである。
アテンションメカニズムには、データベース設計に由来する名前を持つ3つの異なる行列が関与する:クエリ行列は、現在のトークンが入力シーケンス内の他のトークンに対してどれだけ関連性があるかを表す;キー行列は、他のトークン同士がどれだけ関連性があるかを表す;そしてバリュー行列は、それらの他のトークンの生の内容を表す。これら3つの行列を乗算することで、本質的に、トランスフォーマーの次の出力のための「レシピ」が作成される。
計算の複雑さを軽減するために、これらの乗算は次元が削減された空間で行われる。行列自体とそれらの乗算結果は、その後、入力の元の次元に投影し戻さなければならない。
LoRAは、2つのより小さな行列の積を使用して重みの更新を近似し、学習可能なパラメータの数を劇的に削減する。この技術は通常、アテンションプロジェクションレイヤーとフィードフォワードネットワークレイヤーに適用される。これらのモジュールは、トランスフォーマーのパラメータの大部分を構成し、表現学習を直接支配し、低ランク近似と自然に整合するため、理想的な候補である。経験的証拠は、ファインチューニング中のこれらのレイヤーの重み変化が、しばしば低次元部分空間内にあることを示している。
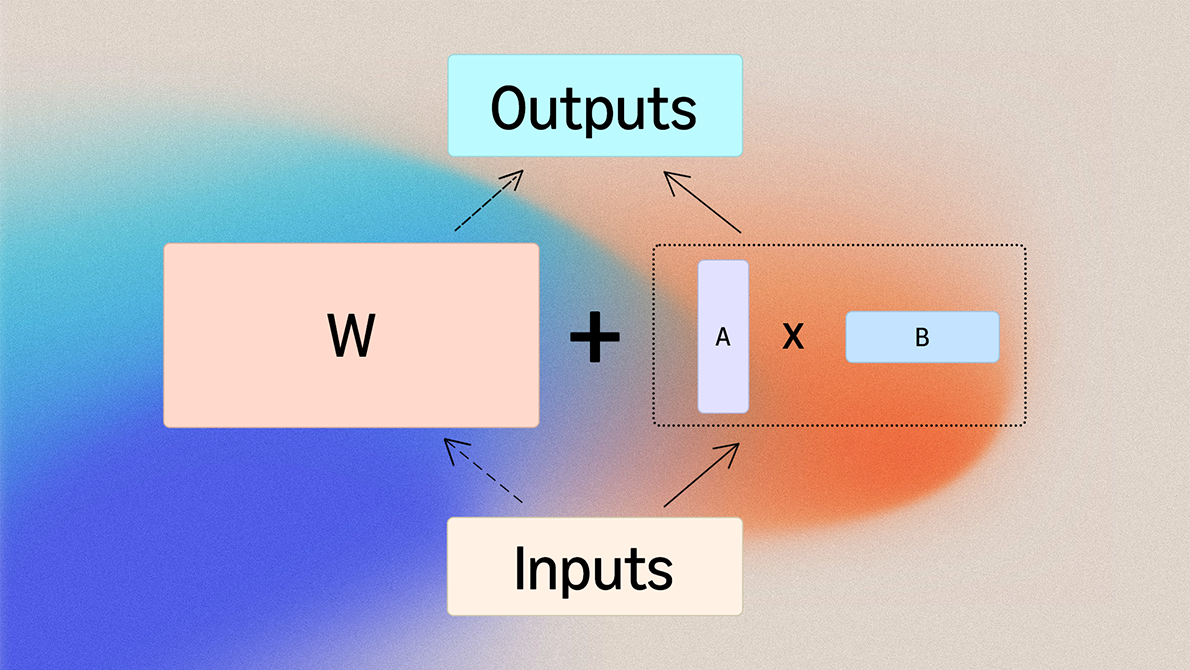 image 一般的なレイヤー重み行列 (
image 一般的なレイヤー重み行列 (W) に対するLoRA。重みは、2つのより小さな行列 (A と B) の積によって修正され、それらのより低い次元により学習可能なパラメータの数が劇的に削減される。
ターゲットモジュールの選択
適切なターゲットモジュールを選択することは、精度、レイテンシー、計算効率に直接影響する。ターゲットモジュールの最適な選択は、主に (a) ファインチューニングされるベースモデル(つまり、そのアーキテクチャ、事前トレーニングおよび事後トレーニングデータ分布など)と (b) カスタマイズドメイン/モダリティの関数である。
Nova 2.0 Liteをファインチューニングする際、我々は2つの相反する目標のバランスを取った:
- 多様なタスクとモダリティにわたる精度の最大化、および
- LoRAの効率性の利点を維持するためのレイテンシーの最小化。
我々は、各トランスフォーマーブロック内の4つの異なるモジュールへのLoRAの適用を調査した:クエリ、キー、バリュープロジェクションレイヤー (qkv);o_projレイヤー;そしてフィードフォワードネットワーク内の2つの異なる全結合層、gate_up_projとgate_down_proj (fc1およびfc2と呼ばれる)。以下は、文献および経験的研究に基づく、これらのモジュールの単体および組み合わせでのトレードオフである。
実験手法
我々は包括的なアブレーションスタディを実施し、推論(すなわち、トレーニングデータセット自体が推論コンテンツを含む)タスクと非推論タスクの両方にわたる、テキストデータと視覚データをカバーする7つのデータセットにおいて、複数の教師ありファインチューニング (SFT) LoRAバリアントを学習した。データセットは、単純な質問応答から長文要約、構造化JSON抽出まで、多様な課題を網羅した。
Dataset
原文を表示
Optimizing LoRA target module selection for efficient fine tuning
Ablation study clarifies trade-offs between accuracy and efficiency when using low-rank adaptation (LoRA) to fine-tune AI models.
Machine learning
Rushil Anirudh Anjie Fang Bhoomit Vasani March 19, 10:39 AM March 19, 10:39 AM Fine-tuning a large language model (LLM) on a specific task requires updates to billions of parameters across trillions of tokens, with the attendant costs in GPU resources and time.
Low-rank adaptation (LoRA) is a more efficient alternative that freezes the original model weights but introduces lightweight matrices into specific model sublayers, or modules. These matrices (commonly referred to as adapters) modify the modules weights, enabling not only efficient fine tuning but also on-demand model serving, which dramatically lowers inference costs; base-model sharing across GPUs, which cuts memory requirements; lower download overhead; and parallel inference across multiple adapters.
The question is where to insert these adapters across the model. Empirically, targeting more and larger modules tends to boost performance, because it allows more flexibility in customization; but it also increases training and inference costs. Using a smaller, well-chosen subset preserves most gains with significantly better efficiency.
Using Amazons Nova 2.0 Lite multimodal reasoning LLM as our base model, we set ourselves the goal of identifying a subset of standardized target-module configurations that works effectively across the vast majority of customer use cases. Through an ablation study, we identified a module known as o_proj, as the single module where adding an adapter achieves the best trade-off between efficiency and accuracy (o_proj is a linear transformation that mixes representations across attention heads into a single, cohesive form for the rest of the model to understand).
The Transformer architecture
Transformer models the models responsible for all of AIs remarkable recent gains consist largely of blocks that are repeated multiple times. Each block in turn has two main components: an attention mechanism, which determines the relevance of previously seen tokens to the token currently being processed, and a feed-forward network, a conventional neural network that does additional processing on the outputs of the attention mechanism.
The attention mechanism involves three different matrices, which take their names from database design: the query matrix represents how relevant the current token is to the other tokens in the input sequence; the key matrix represents how relevant other tokens are to one another; and the value matrix represents the raw content of those other tokens. Multiplying the three matrices together creates, essentially, a recipe for the Transformer's next output.
To reduce computational complexity, these multiplications take place in a space with reduced dimensions. The matrices themselves and the results of their multiplication then have to be projected back up to the original dimensions of the input.
LoRA approximates weight updates using a product of two smaller matrices, drastically reducing the number of trainable parameters. The technique is typically applied to attention projection layers and feed-forward network layers. These modules are ideal candidates because they constitute the bulk of Transformer parameters, directly govern representation learning, and exhibit natural alignment with low-rank approximations. Empirical evidence shows weight changes in these layers often lie within a low-dimensional subspace during fine tuning.
image LoRA for a generic layer-weight matrix (*W*). The weights are modified by the product of two smaller matrices (*A *and* B*), whose lower dimensions drastically reduce the number of trainable parameters. Target module selection
Selecting the right target modules directly affects accuracy, latency, and computational efficiency. The optimal choice of target modules is primarily a function of (a) the base model being fine-tuned (i.e., its architecture, pre- and post-training data distributions, etc.) and (b) customization domain/modality.
When fine-tuning Nova 2.0 Lite, we balanced two competing objectives:
Maximizing accuracy across diverse tasks and modalities and
Minimizing latency to preserve LoRA's efficiency benefits.
We investigated the application of LoRA to four different modules in each Transformer block: the query, key, and value projection layers ( qkv); the o_proj layer; and two different fully connected layers in the feed-forward network, gate_up_proj and gate_down_proj (referred to as fc1 and fc2). Below are the trade-offs for these modules, both singly and in combination, based on results published in literature and empirical studies.
CombinationExpected accuracyExpected latencyUse case
*qkv* onlyGood (baseline)Lowest- Resource-constrained environments
- Tasks where attention mechanisms are critical (e.g., classification, lightweight generation)
- Prioritizes speed over maximum accuracy
*o_proj* onlyModerateLowest- Ultralow-latency scenarios
- Tasks where refining attention outputs is sufficient (e.g., simple sentiment analysis). Plays an important role in reasoning
- Less effective than qkv, but very efficient
*qkv* + *o_proj*HighLow to moderate (+510%)- Attention-focused tasks (e.g., machine translation, summarization)
- Balances refinement of both attention context ( o_proj) and query/key/value projections ( qkv)
- Best accuracy-to-latency ratio for most NLP tasks
*qkv* + *fc1* / *fc2*Very high (close to full fine tuning)Moderate (+1015%)- Complex generation tasks (e.g., translation, long-form summarization)
- When feed-forward layers ( fc1/ fc2) significantly influence output quality as they store and retrieve factual knowledge
- Prioritizes accuracy over speed
*o_proj* + *fc1* / *fc2*Good to highModerate (+510%)- Tasks requiring adaptation of both attention output ( o_proj) and feed-forward layers (e.g., text classification, sentiment analysis)
- Suitable when qkv adaptation is unnecessary
*qkv* + *o_proj* +* fc1* / *fc2*Highest (near-full fine tuning)High (+1520%)- Maximum accuracy for critical tasks (e.g., research benchmarks, high-stakes generation)
- When all components of the Transformer block need adaptation
- Avoid for production if latency matters
All modules( *qkv*, *o_proj*, *fc1*, *fc2*)MaximumHighest (+2025%)- Prototyping/research with no latency constraints
- Rarely justified in practice; marginal gains over qkv + o_proj + fc1/ fc2
Trade-offs of accuracy and latency across target modules, based on literature review and empirical evidence.
Experimental methodology
We conducted a comprehensive ablation study, training multiple supervised-fine-tuning (SFT) LoRA variants on seven datasets spanning both text and visual data, across reasoning (i.e., the training datasets themselves include reasoning content) and non-reasoning tasks. The datasets covered diverse challenges from simple question answering to long-context summarization and structured JSON extraction.
Dataset<td colspan="1" rowspan="1" width="44" valign="top" style="width:32.7pt;border:solid windowtext 1.0pt; border-left:none;mso-border-left-alt:solid windowte
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み