ランチェーンのGTMエージェント構築方法
LangChain は Deep Agents アーキテクチャを活用した GTM エージェントを構築し、営業プロセスの自動化により成約率と生産性を劇的に向上させた実例を発表しました。
キーポイント
Deep Agents による複雑な業務自動化
Salesforce、Gong、LinkedIn など複数のツールを横断し、文脈の収集から提案作成までを自律的に実行する「Deep Agents」アーキテクチャを採用しました。
劇的な営業成果の数値化
リードから商談への転換率が 250% 向上し、チーム全体で月間 1,320 時間の業務時間を節約するなどの具体的な成果を達成しました。
人間と AI の協調ワークフロー
AI が下書きと根拠(ソース)を提示し、営業担当者が最終承認を行う「Slack ドラフト」形式を採用することで、信頼性と実用性を両立させました。
影響分析・編集コメントを表示
影響分析
この記事は、LLM アプリケーションが単なる実験段階から、企業の収益に直結する重要な業務プロセスを自律的に実行できる成熟した段階へ移行したことを示す決定的な事例です。特に、複雑なツール連携とデータ整合性を保ちながら「Deep Agents」のような高度なアーキテクチャを実装し、具体的な KPI 改善をもたらした点は、業界全体における AI エージェントの実践的価値を再定義するものです。
編集コメント
LangChain が自社の営業プロセスを AI エージェントで再構築し、劇的な成果を出した事例は、他社が模倣できる非常に強力なケーススタディです。特に「Deep Agents」の活用と人間による承認フローの設計は、実務導入における重要な指針となります。

Vishnu SureshとJess Ouによる寄稿
LangChainにおけるすべてのアウトバウンド(外部営業)は、かつて同じ手順から始まっていました。セールスレップがタブを切り替えながら作業を行います。アカウント情報の確認にはSalesforce、通話履歴の参照にはGong、連絡先情報の取得にはLinkedIn、そして会社概要の確認には企業ウェブサイトを使用します。たった1文を書くためにも15分間のリサーチが必要であり、チームメイトが昨日すでに連絡を取っていたかどうかを簡単に確認する方法はありませんでした。インバウンド(受注)のフォローアップも、新しい連絡先ごとに同じメッセージをApolloに手動で入力するという作業でした。
私たちは、このプロセスをエンドツーエンドで実行するGTM(Go-To-Market)エージェントを開発しました。このエージェントは、新しいSalesforceのリードをトリガーとして検知し、 outreach(営業アプローチ)を行うべきかどうかを判断し、コンテキスト情報(ミーティング履歴を含む)を集約し、レップが承認するためのSlackのドラフト(推論プロセスと出典情報付き)を送信します。私たちはこれをDeep Agents上で構築しました。これは、複数のツールと大量のデータを確実にオーケストレーションする必要がある、長時間実行されるマルチステップのプロセスであるためです。
主要な成果
- 2025年12月から2026年3月の期間で、リードから合格見込み商談へのコンバージョン率が250%向上し、同じ期間のパイプライン金額が3倍に増加
- 12月以降、営業担当者は低意図のリードへのフォローアップを97%、高意図のリードへのフォローアップを18%増加させた
- 営業担当者は月間40時間ずつ、チーム全体で合計1,320時間の時間を節約
- 営業チームメンバーのデイリーアクティブユーザー(DAU)比率は50%、ウィークリーアクティブユーザー(WAU)比率は86%
チームからの高い評価
GTMエージェントは当初SDR(セールス開発担当者)向けに設計され、その後より広範なGTMチームによって活用されるようになった。






制約条件と成功基準
コードを書く前に、エージェントが実際に何を行うべきかを定義しました。
私たちの目標は2つありました。リード(見込み客)あたりの営業担当者の調査とドラフト作成に要する時間を削減すること、そしてマーケティング由来のインバウンド(受注)におけるコンバージョン率を向上させることです。アウトバウンド(能動的な営業)の調査とドラフト作成は、システムが安全で監査可能であり、使用することで改善されるという条件が満たされれば自動化するのに十分なほど体系的な作業です。
譲れない要件
- ヒューマン・イン・ザ・ループ(人間による監視):営業担当者の明示的なレビューと承認がない限り、何も送信されません。タイミングを誤った1通のメールが、数か月にわたる関係構築の成果を台無しにする可能性があります。
- 連絡履歴の知識:エージェントは何らかのドラフトを作成する前に、担当営業担当者やチームメイトがすでに連絡を取っていたかどうかを確認する必要がありました。
中核機能
- 関係性を考慮したパーソナライズ:ドラフトは、アカウントの現在の状態(既存顧客か、温かい見込み客か、冷たい見込み客か)を反映し、すべてのリードを同様に扱うべきではありません。
- 説明可能性:営業担当者は主要な入力内容を確認し、エージェントが特定の角度を選んだ理由を理解できる必要があります。これにより、営業担当者はドラフトを調整し、フィードバックを提供できます。
- 学習ループ:エージェントは営業担当者の編集履歴から時間とともに学習し、プロンプトを手動で更新することなくドラフトが改善されるようにします。
測定
すべての営業担当者のアクション(送信、編集、キャンセル)は LangSmith にログとして記録され、基盤となるトレース(追跡情報)に付加されます。これにより、品質の評価、回帰テストの検出、および何が機能しているかの定量化が可能になります。
スコープの拡大:アカウントインテリジェンス
単発の下書き作成だけでなく、私たちはエージェントがdealのリスク、拡大の可能性、競合他社の動きといったアカウントレベルのシグナルを能動的に提示することを望んでいました。これにより、営業担当者は毎週どこに注力すべきかを把握できます。
私たちが構築したもの
GTMエージェントは2つの役割を果たします。(1)リードの調査とパーソナライズされたメールの下書き作成、(2)ウェブアクティビティ、開発者エコシステム、製品使用状況、マーケティングの接点にわたるアカウントレベルのシグナルを集約し、営業担当者が注力すべき場所を示すことです。この意図データ(intent data)を営業担当者のアカウントに紐付けることで、意味のあるアクティビティを浮き彫りにし、dealのリスクや競合他社の動きにフラグを立て、次に誰に連絡するのが最適かを明確にします。
私たちはエージェントを以下のデータソースに接続しました:

受信リードの処理
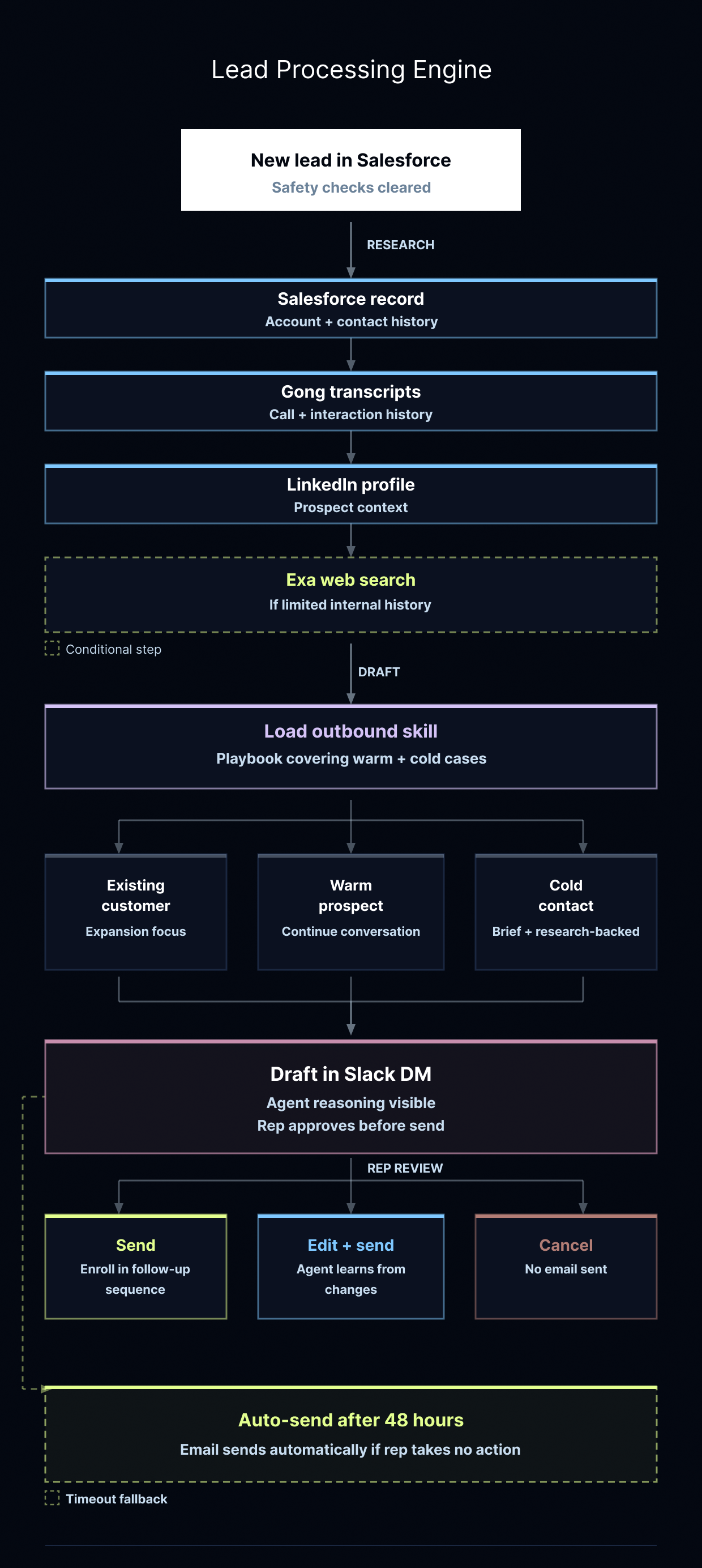
Salesforceに新しいリードが表示されると、エージェントは直ちに作業を開始します。まず初めに、何も送信しない理由がないかを確認します。サポートチケットが提出されたばかりの場合や、チームメイトがその週のはじめにすでに連絡を取っている場合など、自動化されたメールを送信するのは誤りとなります。エージェントは慎重に動作するようにプログラムされています。

これらのチェックをクリアすると、エージェントはかつて営業担当者が手動で行っていたのと同じ調査を行います。Salesforce のレコード全体を取得し、Gong の会話録音を精読し、見込み客の LinkedIn プロフィールを確認します。社内の履歴が少ない場合は、Exa を使ってウェブを検索し、同社が現在 AI に対してどのような取り組みをしているかを把握します。
メール草案の作成方法は、関係性の状態によって異なります。エージェントは定義されたアウトバウンド スキル に従い、草案作成前にロードされるプレイブックを使用します。このスキルは、温かいケースと冷たいケースの両方をカバーするように設計されています。既存顧客には異なる内容が提供され、温かい見込み客にはまた別の内容が、冷たいコンタクトにはさらに異なる内容が提供されます。コールドアウトリーチの場合、エージェントは定義されたプレイブックに従い、簡潔かつ調査に基づいた内容に留めます。
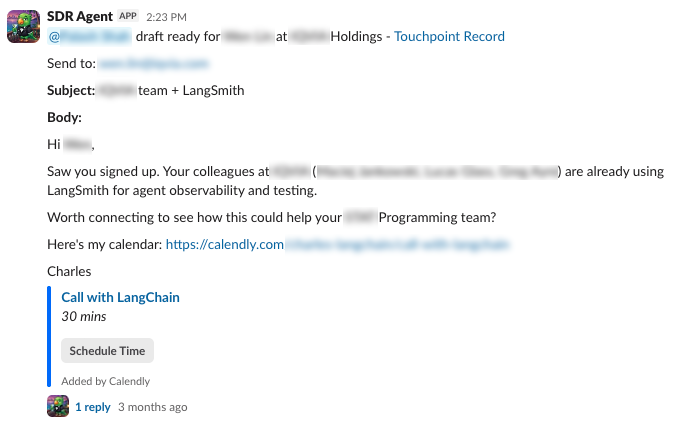
営業担当者は、送信、編集、またはキャンセルのボタン付きの Slack DM で完成した草案を確認できます。また、エージェントの推論プロセスも見えるため、特定の角度からアプローチした理由が明確になります。送信すると、エージェントはフォローアップメールのセットをキューに入れ、見込み客を任意でそのシークエンスに登録できるようにします。
エージェントの改良を進める中で、シルバーリードに対して48時間以内のSLA(サービスレベルアグリーメント)を導入しました。このルールにより、担当者がドラフトの承認または却下を行わない場合、48時間経過すると自動的に送信されるようになります。これにより、それまで返信なしで放置されていたリードへのフォローアップ率が有意に向上しました。
アカウントインテリジェンス
チームの規模拡大に伴い、各担当者が管理するアカウント数は50から100以上へと増加しました。この規模になると、コミュニケーションが途切れたり、拡大の機会を見逃したりしやすい状況になります。
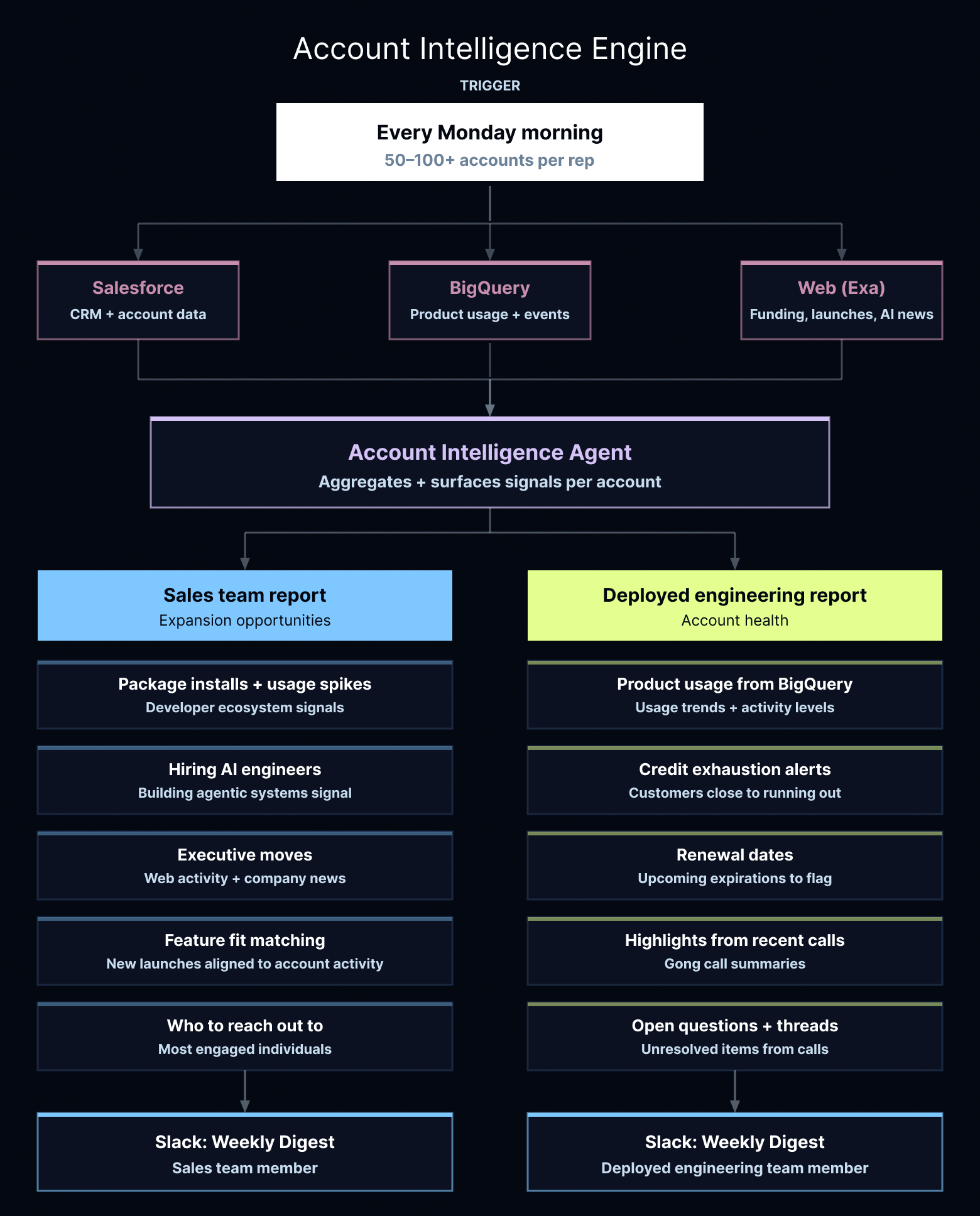
毎週月曜日の朝、エージェントはSalesforceとBigQueryからデータを取得します。その後、外部の世界で資金調達ラウンド、製品発売、新しいAIイニシアチブなどの情報を検索します。レポートは、異なるデータポイントに関心を持つ販売チームと展開エンジニアリングチームの2つの対象者に合わせてカスタマイズしています。
営業担当の場合、エージェントは製品の使用状況、開発者エコシステム、ウェブアクティビティ、採用動向、企業ニュースにわたるシグナルを統合し、拡大の機会を浮き彫りにします。執行部の異動、パッケージインストール数の急増、そして企業がAIエンジニアを積極的に採用しているか、あるいはエージェントシステムを構築中かどうかといったシグナルを特定します。これらは企業が拡大の準備ができていることを示す強力な指標です。また、新機能のローンチ時に、直近のアクティビティが新機能とよく一致するアカウントを特定し、潜在的な適合性を示します。さらに、アカウントがアクティブであることだけでは不十分であるため、最も関与度の高い個人を浮き彫りにし、次に誰に連絡すべきかの提案も行います。
デプロイされたエンジニアの場合の焦点はアカウントヘルス(状態)に移ります。エージェントはBigQueryから製品使用データを取得し、最近の顧客コールからのハイライト、今後の更新日、顧客がクレジットを使い果たす寸前であるケースを強調表示します。また、最近のコールからの未解決の質問やスレッドも浮き彫りにします。この目標は、実際に人間の介入が必要な事項を特定し、チームが日曜日の夜にダッシュボードを掘り下げる作業に時間を費やさないようにすることです。
構築方法
このエージェントは複数のソースからデータを取得し、それらに対して推論を行い、パーソナライズされた出力を生成する必要がありました。これは、単なるLLM(大規模言語モデル)の呼び出しでは確実に処理できる範囲を超えています。
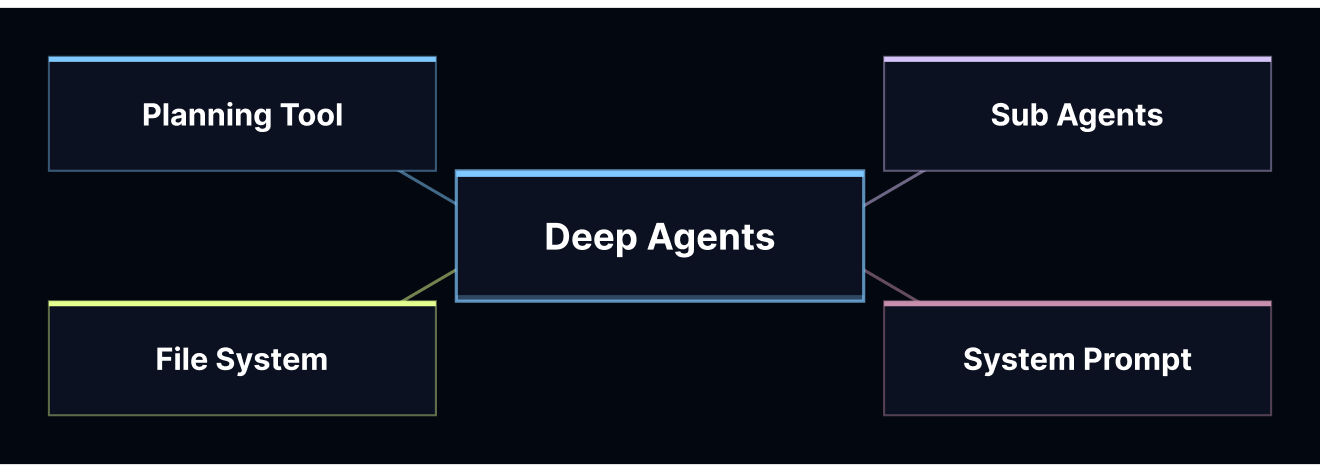
マルチステップのオーケストレーションには Deep Agents を選択しました。その理由は、入力データが本質的に偏りがあるためです。ミーティングのデータ、CRM の履歴、Web 調査は、サイズや構造が大きく異なります。Deep Agents を使用することで、大きなツールの結果が自動的に仮想ファイルシステムにオフロードされるため、独自の切り捨ておよび検索レイヤーを構築する必要がありませんでした。また、ハarness のネイティブな計画ツールを使用して、一貫したチェックリスト(送信不可チェック → 調査 → 下書き作成 → 根拠の提示 → フォローアップ)を適用しました。これにより、実行のデバッグが容易になり、エージェントの逸脱(wandering)を減らすことができました。
エージェントを LangSmith に接続し、営業担当者が実際にどのように使用しているかを把握し、エージェントが時間とともに改善されているかどうかを測定できるようにしました。つまり、後から追加するのではなく、初期段階から評価(evaluations)を設定する必要がありましたが、これはプロンプトの反復やモデルバージョンの交換時に回帰(regressions)を検出するために極めて重要でした。
エージェントパターン
GTM エージェントを本番環境に移行する際、解決すべき2つの問題が浮上しました。それは、エージェントが利用者から学習する方法と、大規模な運用において実行を効率的に維持する方法です。
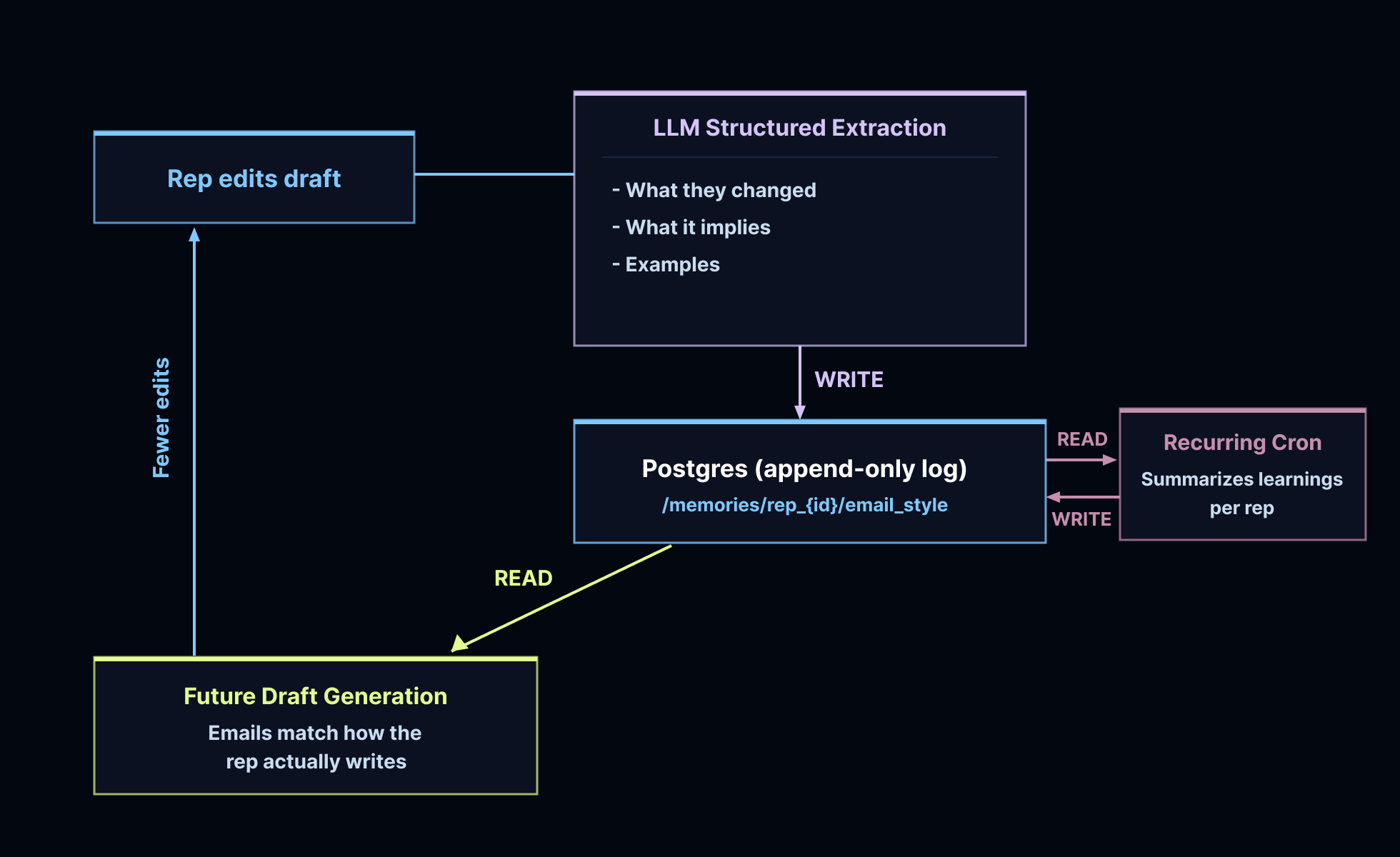
メモリ
営業担当者が Slack 上でドラフトを編集すると、システムは元の文書と改訂版を比較します。変更が実質的なものである場合、LLM(大規模言語モデル)は差分を分析し、構造化されたスタイルの観察結果を抽出します。具体的には、「何が変わったか」「それが担当者の好意について何を意味するか」、そして任意の引用例です。これらの観察結果は PostgreSQL に保存され、担当者ごとにキーが設定されます。その後、ドラフト作成のたびに過去のすべての実行結果からこれらを読み取ります。
各営業担当者は、トーンや簡潔さに関する独自のスタイル上の好みを持っています。フィードバックループは自動化されています。編集のたびにエージェントが学習し、次のドラフトにそれが反映されます。週次 cron ジョブにより、これらのメモリが圧縮され、時間が経つにつれて肥大化するのを防いでいます。
サブエージェントへの委任
アカウントインテリジェンスは、コンパイルされたサブエージェントを通じて実行されます。これらは限られたツールセットと構造化された出力スキーマを持つ軽量なエージェントであり、メインのエージェントとの契約として機能します。営業調査用サブエージェントは Apollo、Exa、BigQuery にアクセスでき、構造化された見込み顧客および市場のコンテキストを返します。デプロイ済みエンジニア用サブエージェントは Salesforce、Gong、サポートツールを使用し、使用状況のトレンド、オープンなチケット、および拡大のシグナルを返します。
親エージェントはアカウントごとに1つのサブエージェントを生成し、ツールを分離して出力を予測可能に保ちます。サブエージェントは独立して実行されるため、並列実行が可能です。LangSmith デプロイメント が水平スケーリングと耐久性のある実行を処理するため、ボリュームが増大してもシステムは信頼性を維持します。

評価とフィードバック
新しいワークフローの生産コードを書く前に、LangSmith において成功の基準を定義します。私たちは、営業担当者が実際に直面する状況に基づいた代表的なシナリオの小さなライブラリから始め、それらを使用して初期エージェントや機能を作成し、基本機能が動作することを確認してから拡張を行いました。
機能が実装された後、LangSmith での評価セットを拡大し、より困難なケースをカバーしました。これには、エージェント型 AI や自然言語処理(NLP)に精通した研究者、再エンゲージメントを試みる既存顧客、以前の Gong 会話録があるアカウント、医療業界のように専門用語が豊富な垂直市場などが含まれます。すべてのケースは外部 API をモックするテストハーネスを通じて実行され、実際のデータに触れる前に制御された環境で動作を観察できます。
評価は2つのレベルで行います。まず、ルールベースのチェックで基本事項を確認します:適切なツールが使用されているか、順序が正しいか、重複したドラフトがないかです。次に、LLM ジャッジを用いて、トーン、文字数、フォーマットをスコアリングします。これらはCI(継続的インテグレーション)内の完全な評価スイートの一部として実行され、エージェントの挙動に説明できない変化が生じた場合は調査対象のバグとして扱います。
しかし、評価結果は物語の一部しか語ってくれません。実際に重要なのは、営業担当者がドラフトを日常でどのように使用するかです。すべてのSlackアクション(送信、編集、キャンセル)を追跡し、LangSmithのトレースに直接関連付けます。これにより、時間とともにライティングパターンと実際の成果(どのスタイルがオープン率を高め、どの件名が返信を得るか)を相関させることができます。十分な数の営業担当者にわたって一貫して効果的なパターンが見られた場合、それをエージェントのデフォルト動作として定義します。
LangSmithの評価スイートと営業担当者のフィードバックループは互いに補完し合います。一方は回帰テスト(既存機能の再確認)で問題を捕捉し、他方は改善を牽引します。
営業チームを超えた採用
GTMエージェントは、バックグラウンドプロセスとして動作するアンビエントエージェントとして始まりました。Salesforceにリードが表示されると、エージェントが実行され、ドラフトが営業担当者のSlackに届きます。トリガーも手動作業も不要です。
その後、SDR(営業担当)がエージェントと直接やり取りできる手段を提供することを主な目的として、会話型の Slack インターフェースをサイドプロジェクトとして構築しました。私たちが予想していなかったのは、それが社内の他の部門へどれほど急速に広がったかです。エージェントはすでに Salesforce、Gong、BigQuery、Gmail に接続されていたため、人々は私々が設計していなかった用途を見出しました。エンジニアは SQL を記述することなく製品利用状況を確認し、カスタマーサクセス担当者は契約更新の電話前にサポート履歴を参照しました。アカウントエグゼクティブは会議の前に Gong の会話録音の要約を作成しました。
これらのワークフローを意図的に構築したわけではありません。エージェントにはアクセス権があり、人々は最も抵抗の少ない道(=手間のかからない方法)を見つけました。ボットと話す方が、6 つもの異なるタブを開くよりも簡単だったのです。
他のチームが GTM エージェントをどのように活用しているかについては、追って別の記事で解説します。
学んだ教訓
ゼロから始めようとする人に伝えたい、いくつかの重要なポイントがあります:
- コードを書く前に、成功の定義から始めます。新しいワークフローのための本番環境コードを作成する前に、どのような状態が「良い」のかを定義し、それに基づいた小さなシナリオライブラリを構築します。このセットはエージェントが成熟するにつれて拡大していきます。何かがリリースされる頃には、回帰テストをキャッチし、ドリフト(性能の低下や偏り)を検出し、CI 内で自動的に実行される評価テストスイートが用意されています。
- ヒューマン・イン・ザ・ループは安全性を超えたものです。それはデータ収集のメカニズムであることがわかりました。すべての営業担当者のアクション(送信、編集、キャンセル)は、私たちが学習できるシグナルとなりました。営業担当者が業務フローの中にいるからこそ、メモリシステムとフィードバックループが機能しています。
- 最初から記録系システム(systems of record)にエージェントを接続します。社全体での有機的な普及は、エージェントが人々がすでに必要としていたデータにアクセス可能だったためです。エンジニアやカスタマーサクセスチームがそれを使用する計画はありませんでしたが、アクセス権限がすでに存在していたため、その利用は広がっていきました。
- 長時間実行されるワークフローには適切なインフラストラクチャが必要です。このエージェントは、ツールを一つ二つ持つ単純な LLM(大規模言語モデル)呼び出し以上のものを必要としました。複数のソースからデータを取得し、それら間で推論を行い、サブエージェントを並列で実行し、会話間を通じて状態を維持する必要がありました。そのようなオーケストレーションのために構築されたエージェントハーネス「Deep Agents」を採用したことで、ゼロからインフラストラクチャを再構築する手間を省くことができました。
- 私たちはまだ初期段階にあります。GTM エージェントは現在、実際のワークフローを処理していますが、私たちが構築したフィードバックループ――メモリ、評価(evals)、トレースに紐づく営業担当者のアクションなどを含むもの――が、今後 6 か月でそれを意味のあるものへと改善していく鍵となります。
Slack においてもアクティブなメンバーです!
関連コンテンツ

ディープエージェント(Deep Agents)
エージェントアーキテクチャ(Agent Architecture)
チュートリアルとハウツー
ディープエージェントの評価:私たちの学び

LangChain チーム
2025 年 12 月 3 日
7 分

会社のお知らせ
チュートリアルとハウツー
LangChain のチャットボットを再構築した理由、そして得られた教訓
LangChain チーム
2025 年 11 月 5 日
13 分

ディープエージェント(Deep Agents)
チュートリアルとハウツー
認証と認可によるエージェントのセキュリティ強化
LangChain チーム
2025年10月13日
6分

エージェントの実際の動作を確認する
LangSmith(エージェントエンジニアリングプラットフォーム)は、開発者がすべてのエージェントの意思決定をデバッグし、評価の変更を確認し、ワンクリックでデプロイできるように支援します。
原文を表示
*By Vishnu Suresh and Jess Ou*
Every outbound at LangChain used to start the same way: a rep toggling between tabs. Salesforce for the account record, Gong for call history, LinkedIn for the contact, the company website for context. Fifteen minutes of research before a single word was written, and no easy way to know if a teammate had already reached out yesterday. Inbound follow-up used to mean manually dropping the same message into Apollo for every new contact.
We built a GTM agent that runs the process end-to-end. It triggers on new Salesforce leads, checks whether we should reach out, gathers context (including meeting history), and sends a Slack draft (with reasoning + sources) for the rep to approve. We built it on Deep Agents because this is a long-running, multi-step process that has to orchestrate multiple tools and large amounts of data reliably.
Key results
- Lead-to-qualified-opportunity conversion rate up 250% from December 2025 to March 2026, driving 3x more pipeline dollars in the same period
- Since December, reps have increased their follow up with lower intent leads by 97% and higher intent leads by 18%
- Sales reps reclaimed 40 hours per month each, totaling 1,320 hours across the team
- 50% daily and 86% weekly active usage for sales team members
Team love
The GTM agent started as an SDR agent and then became used by the broader GTM team.
Constraints & success criteria
Before writing any code, we defined what the agent actually needed to do.
We had two goals: reduce the time reps spend researching and drafting per lead, and improve conversion on marketing-generated inbound. Outbound research and drafting is systematic enough to automate, but only if the system is safe, auditable, and improves with use.
Non-negotiables
- Human-in-the-loop: Nothing is sent without an explicit rep review and approval. A single poorly timed email can undo months of relationship-building.
- Contact history knowledge: The agent needed to check whether a rep or teammate had already reached out before drafting anything.
Core capabilities
- Relationship-aware personalization: The draft should reflect the current state of the account (customer vs. warm prospect vs. cold), and not treat every lead the same way.
- Explainability: Reps should be able to see key inputs and understand why the agent chose a particular angle so they could refine it and provide feedback.
- Learning loop: The agent should learn from rep edits over time so drafts improve without anyone manually updating prompts.
Measurement
Every rep action (send, edit, cancel) is logged to LangSmith and attached to the underlying trace so we can evaluate quality, catch regressions, and quantify what’s working.
Scope expansion: account intelligence
Beyond one-off drafts, we also wanted the agent to proactively surface account-level signals like deal risks, expansion opportunities, and competitive moves, so reps know where to focus each week.
What we built
The GTM agent does two things: (1) it researches leads and writes personalized email drafts, and (2) it aggregates account-level signals across web activity, developer ecosystems, product usage, and marketing touchpoints to show reps where to focus. By tying that intent data back to a rep’s accounts, it surfaces meaningful activity, flags deal risks and competitive moves, and clarifies who is ideal to reach out to next.
We connected the agent to the following data sources:
Inbound lead processing
When a new lead shows up in Salesforce, the agent takes over immediately. The first thing it does is look for reasons not to send anything. If someone just filed a support ticket, or if a teammate already reached out earlier in the week, sending an automated email would be a mistake. The agent is programmed to be cautious.
Once it clears those checks, it does the same research a rep used to do manually: pulls the full Salesforce record, reads through Gong transcripts, checks the prospect's LinkedIn profile. If there isn't much internal history, it goes to the web with Exa to understand what the company is doing with AI right now.
How it writes the email draft depends on the state of the relationship. The agent follows a defined outbound skill, a playbook it loads before drafting. The skill is designed to cover both warm and cold cases. An existing customer gets something different than a warm prospect, who gets something different than a cold contact. For cold outreach, the agent keeps it brief and research-backed, following a playbook we've defined in the skill.
The rep sees the finished draft in a Slack DM with buttons to send, edit, or cancel. They can also see the agent's reasoning, so it's clear why it took a particular angle. If they send it, the agent queues up a set of follow-up emails to optionally enroll the prospect in.
As we've refined the agent, we added a 48-hour SLA for silver leads: if a rep hasn't approved or declined the draft within that window, it sends automatically. This has meaningfully increased our follow-up rate for leads that would otherwise slip through without a response.
Account intelligence
As our team scaled, reps started owning anywhere from 50 to over 100 accounts each. At that volume, it's easy for things to go quiet or for expansion opportunities to slip through.
Every Monday morning, the agent pulls data from Salesforce and BigQuery. It then checks the outside world for funding rounds, product launches, and new AI initiatives. We tailored the reports for two audiences: our sales team and our deployed engineering team, since they care about different data points.
For sales, the agent aggregates signals across product usage, developer ecosystems, web activity, hiring trends, and company news to surface expansion opportunities. It flags executive moves, spikes in package installations, and whether a company is actively hiring AI engineers or building agentic systems – which is a strong signal they're ready to expand. It also identifies potential good fits when we launch new features, matching accounts whose recent activity aligns well with the new features. And because knowing an account is active isn't enough on its own, it surfaces which individuals are most engaged and suggests who to reach out to next.
For deployed engineers, the focus shifts to account health. The agent pulls product usage from BigQuery, highlights from recent customer calls, upcoming renewal dates, and cases where a customer is close to running out of credits. It also surfaces open questions and unresolved threads from recent calls. The goal is to flag what actually needs a person to step in, so the team isn't spending Sunday evenings digging through dashboards.
How we built it
The agent needed to pull from multiple sources, reason across them, and produce a personalized output. This is more than a simple LLM call can handle reliably.
We chose Deep Agents for the multi-step orchestration because the inputs are inherently spiky: meeting data, CRM history, and web research vary a lot in size and structure. With Deep Agents, large tool results get offloaded into a virtual filesystem automatically, so we didn't have to build our own truncation and retrieval layer. We also used the harness's native planning tooling to enforce a consistent checklist (do-not-send checks → research → draft → rationale → follow-ups), which made runs easier to debug and reduced agent wandering.
We connected the agent to LangSmith so we could understand how sales reps were actually using it and measure whether the agent was improving over time. That meant setting up evaluations from the start rather than retrofitting them later, which turned out to be critical for catching regressions when we iterated on prompts or swapped model versions.
Agent patterns
Moving our GTM agent to production surfaced two problems we had to solve: how to make the agent learn from the people using it, and how to keep runs efficient at scale.
Memory
When a rep edits a draft in Slack, the system compares the original against the revised version. If the changes are substantive, an LLM analyzes the diff and extracts structured style observations: what changed, what it implies about the rep's preferences, and an optional quoted example. Those observations are stored in PostgreSQL, keyed per rep, and every future run reads them before drafting.
Each rep has stylistic preferences around tone and brevity. The feedback loop is automatic. Every edit teaches the agent, and the next draft reflects it. A weekly cron compacts these memories to keep them from getting bloated over time.
Subagent delegation
Account intelligence runs through compiled subagents: lightweight agents with constrained tool sets and structured output schemas that act as contracts with the main agent. The sales research subagent has access to Apollo, Exa, and BigQuery, and returns structured prospect and market context. The deployed engineer subagent uses Salesforce, Gong, and support tools to return usage trends, open tickets, and expansion signals.
The parent agent spawns one subagent per account, keeping tools isolated and outputs predictable. Because subagents run independently, we can execute them in parallel. LangSmith Deployment handles horizontal scaling and durable execution, so the system stays reliable as volume grows.
Evals and feedback
Before writing any production code for a new workflow, we define what success looks like in LangSmith. We started with a small library of representative scenarios grounded in the situations our reps actually face, used those to build the initial agent or feature, and made sure the fundamentals work before expanding.
Once things were functional, we broadened the evaluation set in LangSmith to cover harder cases: a researcher deep in agentic AI or NLP, an existing customer we're trying to re-engage, accounts with prior Gong transcripts, verticals with heavy jargon like healthcare. Everything runs through a test harness that mocks our external APIs so we can observe behavior in a controlled environment before it touches real data.
We evaluate on two levels. First, rule-based assertions check the basics: right tools, right order, no duplicate drafts. Second, an LLM judge scores tone, word count, and formatting. Both run as part of a full eval suite in CI, and we treat any unexplained drift in agent behavior as a bug worth investigating.
But evals only tell part of the story. What actually matters is how reps use the drafts day to day. We track every Slack action (send, edit, cancel) and attach it directly to the trace in LangSmith. Over time, this lets us correlate writing patterns with real outcomes: which styles drive opens, which subject lines get replies. When something holds across enough reps, we codify it into the agent's default behavior.
The LangSmith eval suite and the rep feedback loop reinforce each other. One catches regressions, the other drives improvement.
Adoption beyond the sales team
The GTM agent started as an ambient agent, running as a background process. A lead appears in Salesforce, the agent runs, a draft lands in the rep's Slack. No trigger, no manual work.
We later built a conversational Slack interface as a side experiment, mostly to give SDRs a way to interact with the agent directly. What we didn't expect was how quickly it spread to the rest of the company. Because the agent was already connected to Salesforce, Gong, BigQuery, and Gmail, people found uses we hadn't designed for. Engineers checked product usage without writing SQL. Customer success pulled support history before renewal calls. Account executives summarized Gong transcripts before meetings.
We didn't build any of those workflows intentionally. The agent had the access, and people found the path of least resistance. Talking to the bot was easier than opening six different tabs.
We'll cover how other teams are using the GTM agent in a follow-up post.
Learnings
A few things we'd tell someone starting from scratch:
- Start with a definition of success, not code. Before we write any production code for a new workflow, we define what good looks like and build a small scenario library around it. That set expands as the agent matures. By the time something ships, we have an eval test suite that catches regressions, flags drift, and runs in CI automatically.
- Human-in-the-loop goes beyond safety. It turned out to be a data collection mechanism. Every rep action (send, edit, cancel) became a signal we could learn from. The memory system and feedback loop work because reps are in the flow.
- Connect the agent to your systems of record from the start. The organic adoption across the company happened because the agent already had access to the data people needed. We didn't plan for engineers or customer success to use it, but that usage spread because the access was already there.
- Long-running workflows need the right infrastructure. This agent required much more than a simple LLM call with a tool or two. It needed to pull from multiple sources, reason across them, run subagents in parallel, and maintain state across turns. Picking an agent harness, Deep Agents, built for that kind of orchestration saved us from rebuilding infrastructure from scratch.
- We're still early. The GTM agent handles a real workflow today, but the feedback loops we've built – including memory, evals, and rep actions tied to traces – are what will make it meaningfully better over the next six months.
And it’s an active member in Slack!
Related content
Deep Agents
Agent Architecture
Tutorials & How-Tos
Evaluating Deep Agents: Our Learnings
The LangChain Team
December 3, 2025
7
min
Company Announcements
Tutorials & How-Tos
Why We Rebuilt LangChain’s Chatbot and What We Learned
The LangChain Team
November 5, 2025
13
min
Deep Agents
Tutorials & How-Tos
Securing your agents with authentication and authorization
The LangChain Team
October 13, 2025
6
min
See what your agent is really doing
LangSmith, our agent engineering platform, helps developers debug every agent decision, eval changes, and deploy in one click.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み