DoorDash、大規模LLM会話シミュレーターを構築しカスタマーサポートチャットボットをテスト
DoorDashは、過去の会話記録とバックエンドモックを用いて多ターン合成会話を生成し、LLM-as-judgeで評価するシミュレータを構築し、カスタマーサポートチャットボットの開発・テストを大規模かつ迅速に実施可能にした。
キーポイント
シミュレーションと評価のフィードループ構築
過去のトランスクリプトとバックエンドモックを活用し、多ターンの合成会話を自動生成するシステムを開発した。
LLM-as-judgeによる自動評価
生成された会話の結果をLLM自体が判定基準として用い、客観的な品質評価と改善サイクルを実現している。
本番環境投入前の迅速な反復
プロンプト、コンテキスト、システム設計の調整を本番デプロイ前に高速で反復可能にし、チャットボットの品質保証を効率化した。
影響分析・編集コメントを表示
影響分析
本取り組みは、LLM搭載チャットボットの品質保証における実務的なベストプラクティスを提示している。合成データ生成とLLM評価の組み合わせにより、開発コストを大幅に削減しながらテストのカバレッジを拡大できるため、業界全体のAIエンジニアリングプロセスの標準化に寄与する可能性が高い。
編集コメント
実運用データを基にしたシミュレーションとLLM評価の組み合わせは、AIチャットボットの品質保証コストを劇的に下げられる実用的な手法だ。今後はこの「シミュレータ」のベンチマーク結果が業界標準として普及するか注目したい。
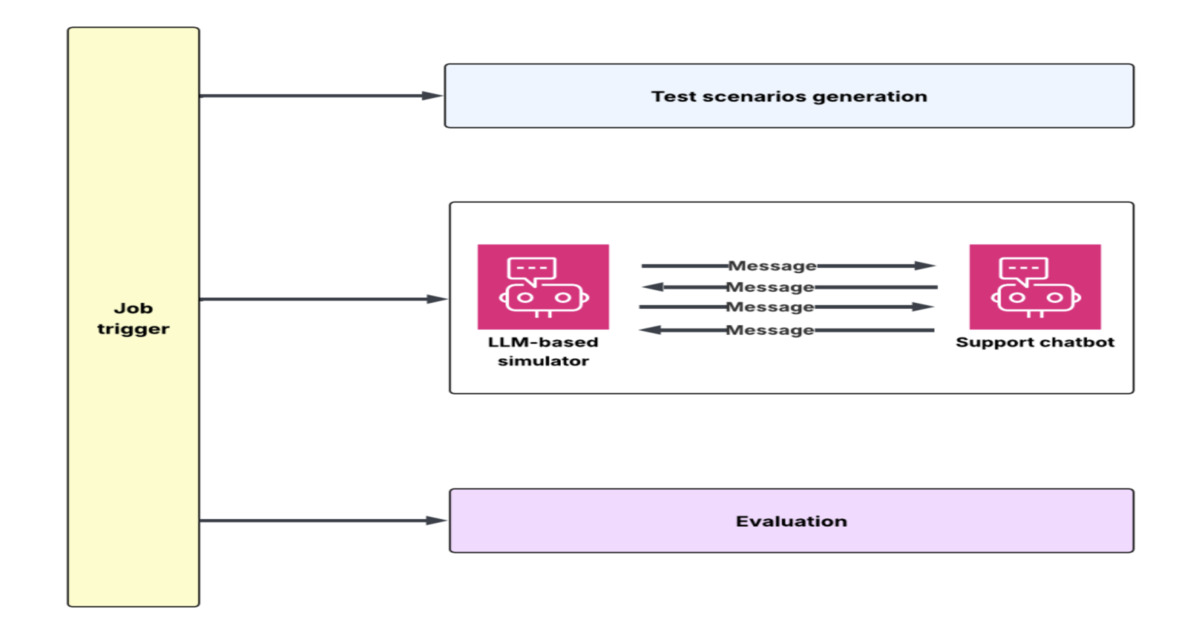 imageDoorDash のエンジニアたちは、大規模な言語モデル(LLM)によるカスタマーサポートチャットボットをスケールしてテストするためのシミュレーションと評価のフライホイールを構築しました。このシステムは、過去のトランスクリプトとバックエンドのモックを用いて多段階の合成会話を生成し、LLM-as-judge(LLM を判事として用いる)フレームワークによって結果を評価します。これにより、本番環境への展開前にプロンプト、コンテキスト、システム設計に関する迅速な反復が可能になります。
imageDoorDash のエンジニアたちは、大規模な言語モデル(LLM)によるカスタマーサポートチャットボットをスケールしてテストするためのシミュレーションと評価のフライホイールを構築しました。このシステムは、過去のトランスクリプトとバックエンドのモックを用いて多段階の合成会話を生成し、LLM-as-judge(LLM を判事として用いる)フレームワークによって結果を評価します。これにより、本番環境への展開前にプロンプト、コンテキスト、システム設計に関する迅速な反復が可能になります。
*By Leela Kumili*
原文を表示
DoorDash engineers built a simulation and evaluation flywheel to test large language model customer support chatbots at scale. The system generates multi-turn synthetic conversations using historical transcripts and backend mocks, evaluates outcomes with an LLM-as-judge framework, and enables rapid iteration on prompts, context, and system design before production deployment.
*By Leela Kumili*
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み