効果的な人間とエージェントのチーム構築について
Anthropic は、人間と AI エージェントが効果的に協働するための具体的な原則や設計手法を提示し、実用化に向けた重要な指針を示した。
キーポイント
人間-AI コラボレーションの原則定義
単なる自動化ではなく、人間の判断と AI の処理能力を補完し合う「チーム」として設計するべきという基本理念を提唱している。
信頼性と透明性の確保手法
エージェントの意思決定プロセスを人間が理解・検証可能な状態に保つための仕組みや、過信を防ぐ設計アプローチについて言及している。
役割分担と制御の最適化
どのタスクを AI に委譲し、どの判断を人間が最終的に下すかという境界線を明確にし、シームレスな連携を実現する具体的なフレームワークを示している。
影響分析・編集コメントを表示
影響分析
この記事は、AI エージェントの実用化において「技術的完成度」から「人的協働の質」へと焦点をシフトさせる重要な転換点を示唆しています。企業や開発者がエージェントを導入する際、単なる効率化ツールとしてではなく、人間の意思決定を補完するパートナーとしてどう設計すべきかという具体的な指針を提供しており、今後の AI 導入戦略に大きな影響を与える可能性があります。
編集コメント
技術的な機能紹介に留まらず、人間と AI の関係性を再定義する本質的な議論が含まれており、実務家にとって非常に示唆に富む内容です。
AI との協働はかつて、一人の人が単一のチャットウィンドウと対話することを意味していました。時を経て、AI はコーディング、リサーチ、財務分析といった複雑で長期間にわたる作業を処理する能力が飛躍的に向上しました。これに伴い、ターミナルや IDE からスプレッドシート、プレゼンテーション資料に至るまで、AI を活用する新たな方法が数多く生まれましたが、作業自体は依然として「シングルプレイヤー」型の体験であり、一人の人間が一人のエージェントと協力して個々のタスクを完了させるという形でした。
しかし、Claude Tag といったツールのリリースにより、この状況に変化が生じています。今や人間とエージェントは同じワークスペースで共に働き、チーム全体が共有する目標達成のために協業することが可能になりました。現在の作業様式は、チームの人間が戦略を策定し、Claude が実行を担当するという*マルチプレイヤーゲーム*のようなものへと大きく変化しています。
これには新たな働き方が伴います。Anthropic では、人間とエージェントによるチームを成功させるために必要な技術について、過去数ヶ月にわたりテストを重ねてきました。本記事では、マルチプレイヤー型エージェントとは何か、そしてそれらを活用して構築する際に得た教訓について解説します。
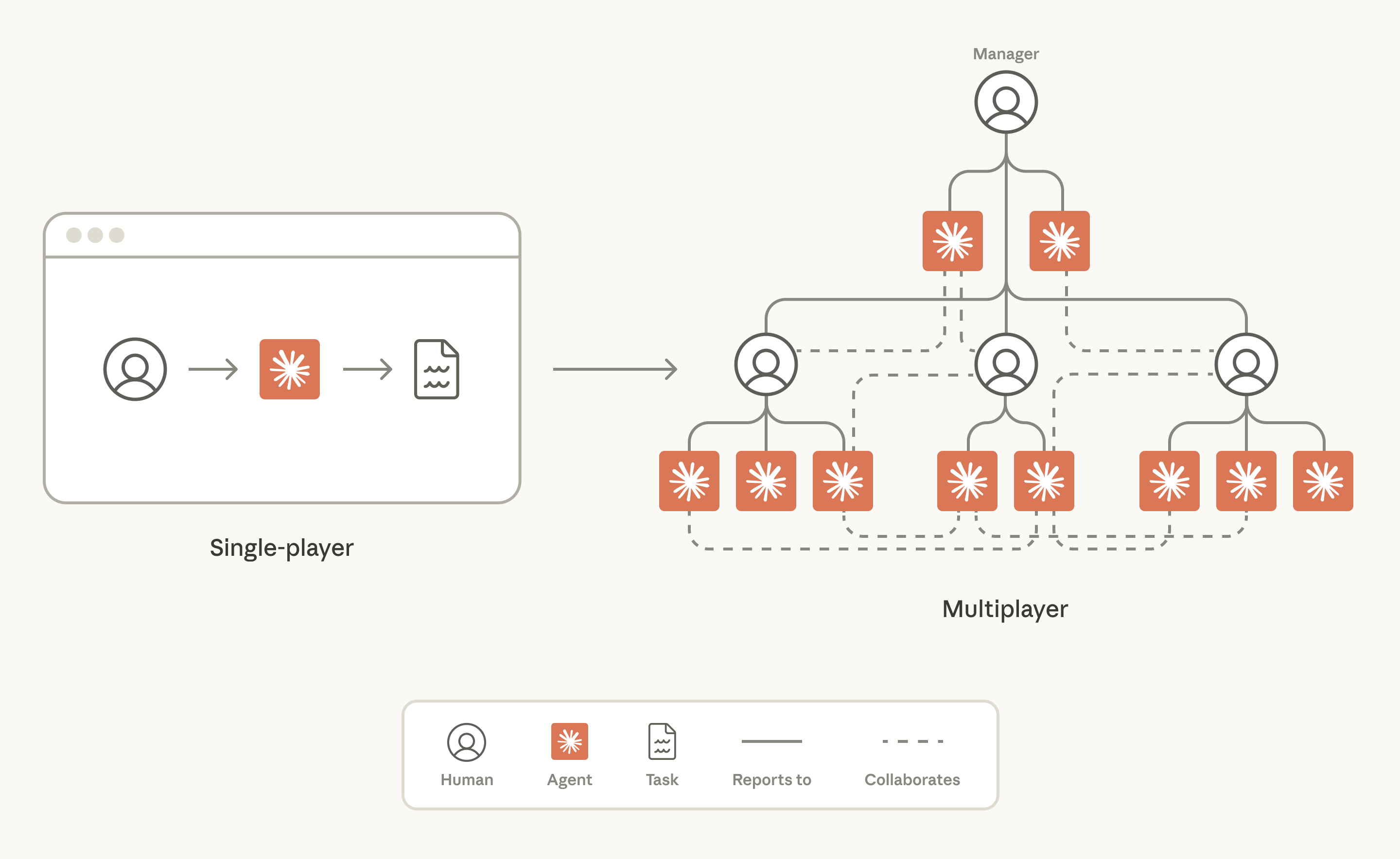
マルチプレイヤーエージェントとは何ですか?
「マルチプレイヤーエージェント」とは、ここでは同時に多くの異なる人間と連携して動作する AI モデルを指す用語です。通常のエージェントと同様に、独自の メモリ と スキル を持っていますが、それ以外の点ではかなり異なります。彼らには独自の 資格情報 があり、業務が行われる場所に存在します。Anthropic では、それは Slack などのチームコラボレーションツールの内部です。
Slack で人間とエージェントが共同してデータセットを分析する例を示します:
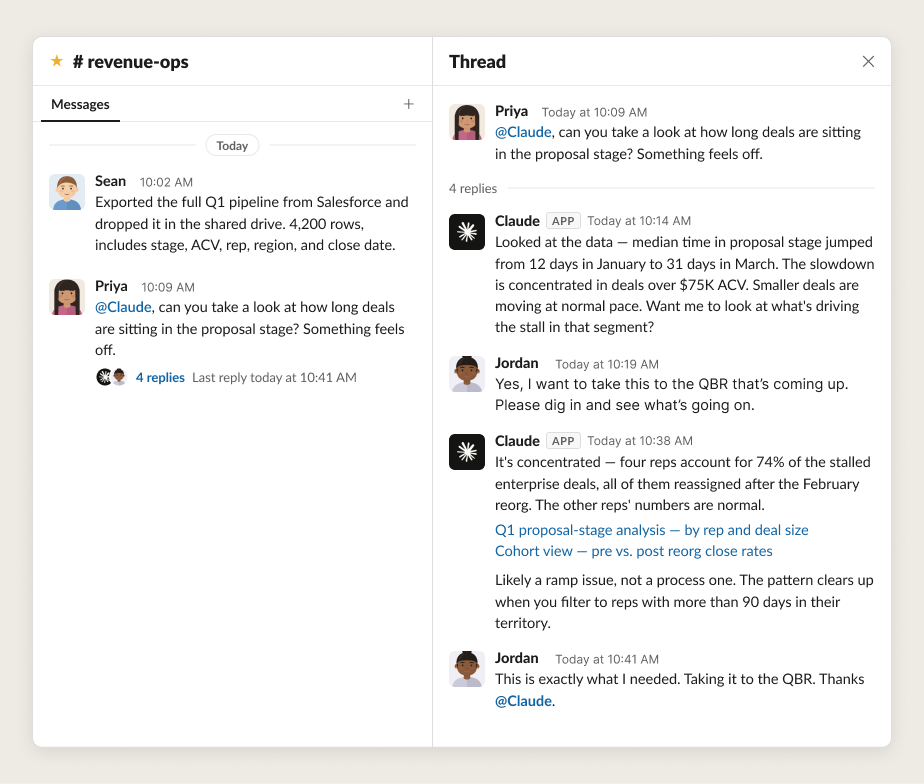
エージェントがチームチャンネルで生産的に参加するためには、特定の機能が必要です:
- 永続的なメモリ。これにより目標を記憶し、実行をそれらに向けて調整できます。
- 人間に紐付かない資格情報。これにより、安全で予測可能なガードレール内で動作できます。
- 継続的な広範な情報へのアクセス。これにより組織の仕組みを理解し、チームの目標達成のためにタスクを実行する行動を起こせます。
これらの機能は、多数の人間からなるチーム全体で生産的に参加するためのエージェントに必要な技術的基盤を構成します。しかし、人間とエージェントのチームを*成功*させるには、これだけでは不十分です。チームには特定の働き方と共有された規範も必要となります。
レッスン 1:公開で作業し、エージェントに広範な文脈を提供する
Anthropic のチームは情報を積極的に、かつオープンに共有します。これは特にエージェントがチームの一員である場合に顕著です。なぜなら、エージェントの理解はチームが検索可能にするテキスト(Slack、コード、ドキュメント、会議議事録)のみから構築されるからです。プライベートメッセージ、廊下での会話、制限されたドキュメントでは、エージェントに文脈を提供することはできません。エージェントにとって、書かれておらずアクセスできない情報は存在しないのと同じです。
ドキュメントや Slack チャンネルごとにエージェントが利用可能な情報を決定するのではなく、Slack ワークスペース全体、会議議事録、ドキュメントライブラリ全体に適用される明確に定義されたセキュリティ境界(security boundaries)を使用しています。このセキュリティ境界内では、文脈はすべてのチームメンバー(人間か AI かを問わず)に流れます。これにより、エージェントと人間の両方がアクセスできる情報量が増えるだけでなく、「何を誰と共有できるのか」という混乱も減少します。人間もエージェントも、アイテムごとの共有という曖昧な境界をナビゲートするのは困難です:*このチャンネルは公開すべきか非公開すべきか?このドキュメントをその人に共有してもよいのか?このエージェントはそのスレッドを見てもよいのか?* 少数の明確でワークスペースレベルの境界を設定することで、日常業務における意思決定疲れ(decision fatigue)を排除できます。
高い透明性は報酬をもたらします。例えば、チーム会議の決定を読み取れるエージェントは、優先度が下げられたタスクやプロジェクトを提案しません。自チームを超えた製品仕様書にアクセスできるエージェントは、他者で成功したパターンを推奨できます。また、エージェントは人間よりもはるかに高速に膨大な量のテキストを読み込むことができるため、人間が見過ごす可能性のある関連する作業を日常的に浮き彫りにします。私たちは忙しい、急速に変化する業界において情報を共有し調整を保つために、エージェントに大きく依存しています。
Anthropic におけるパブリックでの活動は以下の通りです:
- 社内のセキュリティ境界のいくつかを選択し、各セキュリティ境界に一致するワークスペースとドキュメント共有設定を作成すること
- 組織内での新しいコミュニケーションチャネルをデフォルトで公開とし、決定が毎回チャネル、ドキュメント、会議議事録に記録されるようにすること
- エージェントがそれらを見つけられるように成果物や会議議事録を作成すること。なぜなら、エージェントは現在チーム文書の主要な消費者となっているからです
- AI が業務を遂行するために必要な適切なツールと情報へのアクセス権限を確保すること
情報をデフォルトで社内公開にすることは、文化的変革を必要とする場合があります。しかし、コンテキストを持つ人間とエージェントのチームと持たないチームとの違いはあまりにも鮮明であり、無視することはできません。
もちろん、一部の対話は機密性が高く、単一の人間と AI の間で非公開で行われる必要があります。そのような場合、Claude Tag を使用して @Claude にダイレクトメッセージを送信するか、既存の Claude.ai や Claude Cowork アプリケーションを利用できます。これらのツールにより、Claude はあなたの個人用 MCP コネクタを通じて機密情報にアクセスできるようになりますが、会話内容やエージェントに共有する情報は非公開のまま保たれることが保証されています。
レッスン 2: すべての人間とエージェントは、適切な業務遂行のための定義された役割とツールを持つ
人間とエージェントのチームは、1 つのメンバー名簿、1 つのアートifactセット、そして 1 つの作業スペースを共有します。エージェントには独自の 資格情報、スキル、およびツールアクセス権限があります。また、異なるエージェントは異なる役割を担います。例えば、あるエージェントがプロジェクトのデータ分析を担当する一方で、別のエージェントは設計基準を保持・適用し、さらに別の一員が研究合成を実行します。
プロジェクトが始動すると、人間はエージェントとチャットを行い、どの役割を割り当てるか、そして人間とエージェントがどのように連携して作業するかを決定します。
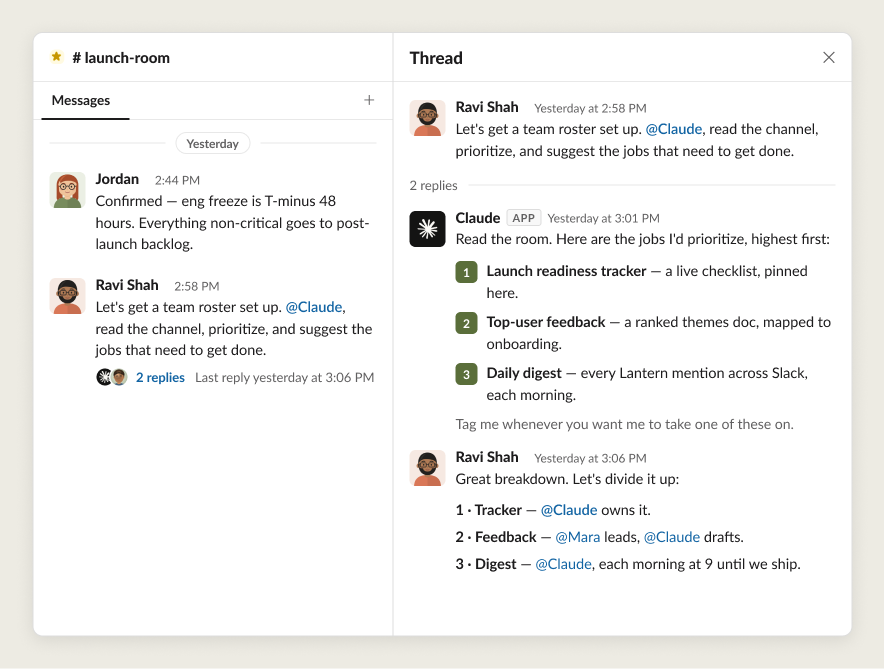
人間とエージェントの役割が明確になった後、エージェントは特定のタスクを適切な記憶とアクセス権限を持つ他のエージェントに任せるために、さらに他のエージェントを起動することがあります。重要なのは、職務を遂行するために必要なすべてのツールへのアクセス権を持っていることです。データ分析を担当するエージェントには BigQuery へのアクセスが必要になるかもしれませんし、QA(品質保証)を行うエージェントには Playwright MCP へのアクセスが必要になるかもしれません。
明確に定義された役割と責任は、人間とエージェントのチームが成功するための基盤となります。人間は多くの場合、エージェントと同じスレッドで作業しますが、人間にしか持てない役割を担っています。これにより、すべての要素が連携し、最も重要な意思決定には人間の判断が適用されます。役割が明確でない場合、人々は各自でパーソナル AI の群れを運用することになり、業務の重複やチームの文脈の分断を招きます。メトリクスの追跡は典型的なケースです:マルチプレイヤーのエージェントは一度作業を行い、全員に同じ数値を見せることができます。
Anthropic において、人間とエージェントのチームで明確に定義された役割とは以下のようなものです:
- 合意されたタスクセット:チームの人間とエージェントが誰が何を行うかを合意する
- 同じ共有スレッドで作業する人間とエージェント:誰でも誰かが残した場所から引き継げるようにする
- 各自の職務を遂行するために必要なツールへのアクセス権を持つ人間とエージェント
- エージェントの役割と範囲の説明

*Claude エージェントは、コードベースの日常メンテナンス、フィードバックの選別、計画策定、コード記述、変更レビュー、ステータス報告を分担します。各エージェントは明確なタスクを持ち、独自のスケジュールで作業を行い、人間が目標を設定し成果物をレビューします。*Anthropic のエンジニアリングチームは、人間とエージェントの役割を形式化して業務をより容易かつ具体的に進めるためにローテーション表の作成を開始しました。彼らが早期に気づいたいくつかのポイント:
- 具体的な役割を定義することで、人間はタスクの責任所在(個別タスクか、チーム全体の責任範囲か)を容易に追跡できます
- 特定のエージェントの役割を定義するスキルファイルを作成することは専門化を容易にし、社内の他のメンバーが同種のエージェントを迅速に立ち上げられるようにします
- プロジェクトが複雑化するにつれて、新領域に焦点を当てるために新しいエージェントを追加します。例えば、新たなソフトウェアリリースに対応するためにリリースマネージャーエージェントを追加しました。
これらの手法により、人間はエージェント数が増加しても、人間とエージェントのチームに関するメンタルモデルを拡張できます。
レッスン 3: エージェントをより主体的にするための「北極星」を設定する
Anthropic の一部のエージェントは割り当てられたタスクを完了するだけですが、最も重要な役割を持つエージェントは、新しいプロジェクトや作業ストリームを主体的に提案します。これは通常、すでに豊富なコンテキストと明確な役割を与えたチームが、もう一つの指針である「北極星」を追加した際に起こります。
北極星とは、チームがどのタスクや作業ストリームが適切かを判断するために役立つ、野心的かつ広範な目標のことです。Anthropic では、人間が常に北極星を設定し、それを企業のミッションと目標に基づいて具体化します。
一度、北極星が明確に文章で記述されれば、人間はチームのエージェントたちに共有します。そして何より重要なのは、人間がどのエージェントが長期的な目標達成のために新しい作業ストリームを自発的に提案すべきかを決定することです。(チーム内のすべてのエージェントが、成功裏に作業ストリームを自発的に提案するための前提となるスキルや信頼関係を備えているとは限りません。)
例えば、「製品オンボーディングをより有益なものにする」という北極星を持つ内部ツールチームでは、あるエージェントがオンボーディングフローのエラーメッセージの文章修正を自発的に提案しました。これらの変更により、翌週のオンボーディング成功率は計測可能な形で向上しました。
Anthropic における北極星の設定とは、以下のようなプロセスです:
- 人間が、企業ミッションとビジネス目標に根ざした、野心的な北極星目標を議論し、論じ合い、文書化すること。これは人間とエージェントのチーム向けのものであること。
- チームのエージェントたちに北極星を共有し、どのエージェントが自発的に新しい作業ストリームを提案できるかを明示的に指定すること。
- カレンダー上で高品質な人間の時間を確保し、会議は最も重要な業務に集中させること。
明確な北極星は、エージェントに一貫した方向性を示し、チームの業務を自発的に支援する有意義な機会を提供します。
レッスン4:信頼は時間をかけて築く
Anthropic のチームでは、エージェントに与える自律性は、その実証された信頼性に応じて段階的に付与され、その後意図的に拡大されます。エンジニアたちは、チームのエージェントを独立して 500 件のバグ修正を処理させることに成功しましたが、もちろん当初からそのような状態だったわけではありません。
新しい人間の同僚がチームに加わった場合、その能力を評価し、強力な作業ルーチンを確立するには時間がかかります。タスクをどのように遂行するのが最善かという暗黙の情報をすべて外部化するには、通常、複数のフィードバックサイクルが必要です。これはエージェントについても同様です。ユーザーは、エージェントにさまざまなタスクを与えて実験することで、そのエージェントが何ができるのか、目標を明確にどう記述すべきか、必要なスキルファイルは何か、そして望ましい行動を引き出すためにどのプロンプトが最も効果的かを学ぶ必要があります。また、モデルが変化して改善されるにつれてタスクを再テストすることも重要です。プロンプトの文言を書き換える必要がある場合や、以前は有益だったガードレールが、より賢いモデルがより創造的な解決策を追求するのを妨げる要因となる可能性があります。
特筆すべきは、我々が発見したところでは、長く稼働するエージェントの中で最も優れたものは、人間が確認する前に作業を検証するための多様な方法を備えているということです。もちろんコードにはテストがありますが、他のほとんどの作業も同様に検証可能です。例えば、技術文書には評価基準やスタイルガイドを適用することができます。人間が高水準の基準を設定し、エージェントに割り当てられたすべての作業が審査可能であることを保証すれば、品質は高水準で維持され、当初の意図から逸れることはありません。また、人間の場合と同様に、タスクを実行する役割を一つのエージェントに、最初のエージェントの作業をチェックする役割を別のエージェントに与えることがよく役立ちます。これは通常、「Doer-Verifier」エージェントハネス 「Doer-Verifier」agent harness と呼ばれています。
Anthropic において、時間とともにエージェントとの信頼関係を築くことは以下のようになります:
- 初期段階ではエージェントの作業を手動でレビューして品質を検証し、フィードバックを提供し、タスク検証チェックリストを設計する
- エージェントに対して、タスクの一部として「検証者」エージェントを使用して自身の作業をチェックさせる
- サイクルに反省を組み込み、エージェント自身が見落としをレビューすることで、時間とともに作業が改善されるようにする
- 各エージェントが自律性を獲得したタスクの種類を追跡し、繰り返し成功した後にタスクタイプごとに範囲を拡大する
Anthropic のあるエンジニアリングリーダーは、大きなバックログを抱えた新しいチームを引き受けました。その状況を把握するために、彼は数人の人間と数人のエージェントを招いてバックログの整理を手伝わせ、最も重要なものを優先順位付けさせました。チーム内の一つのエージェントセットはバックログのすべての項目を読み込み、誰かがその項目に取り組んでいるかを確認し、所有されていないものには複雑度スコアを割り当てました。もう一つのセットはリストから読み上げ、中程度および低複雑度の項目に絞り込み、コード変更を作成しました。初期段階では、人間がエージェントが行ったすべての決定をレビューし、人間の介入が必要なものをマークしました。その後、人間はエージェントに対して、そのような決定を直接人間に提示するよう教え、難しいトレードオフを伴う決定には必ず人間が関与するように確保しました。

毎週、リーダーとそのチームはエージェントに「教訓と失敗」を含む週次レポートの作成を依頼し、エージェントがミスを追跡して将来同じ過ちを繰り返さないようにしていました。時間が経つにつれ、リーダーはより複雑なコード変更をエージェントに任せるようになり、日々のタスクに対する指導に費やす時間を減らすことができました。
そして、エージェントがある程度独立した段階になると、リーダーは彼らをコーチングし、人間の注意という希少資源をどのように扱うべきかを教えました。具体的には、回答が必要な質問を一度にまとめて処理すること、重要な文脈を繰り返して人間がすぐに状況を把握できるようにすること、そして各人間が同時に目にする項目の数を制限することです。
エージェントが効果的にコミュニケーションをとれるように支援することは、彼らが引き続き有用で効果的であり続けるために不可欠です。チーム内に、バッチ処理の方法を決定し、人間メンバーにとって最も重要なコミュニケーションのみを優先する役割を専任とするエージェントを持つ人もいます。また、人間が作業に意味のある形で関与できるようにするために、1 日にエージェントが行うべき作業量の制限(ガードレール)を設定する人もいます。こうしたガードレールは、人間が自分にとって重要なスキルを維持し、人間のレビューが必要な項目の数が持続可能な範囲にとどまることを保証します。
質問すべきこと
人間とエージェントのチームの基盤を構築する際、以下の問いを検討してください:
- エージェントと人間が必要とするすべての情報やアクセス権限は、公開されており広く検索可能でしょうか?
- チームのメンバーリスト(人間とエージェント)を記述し、各メンバーが何を担当しているかを明確にできますか?
- チーム内のすべての人間とエージェントは、職務を遂行するために必要なツールへのアクセス権を持っていますか?
- 主要な作業成果物を検証するための評価基準やテストは用意されていますか?
- チームには、全員が参照できる明確な「北の星(指針)」がありますか?
今後に向けて
これらのパターンは新しいものではありません—少なくとも人間にとってはそうではありません。強力な指針、明確な役割、充実したドキュメント、共通の品質基準、そして失敗から学ぶ余地——これらは私たちが何十年も前から知っている健全なチームの習慣です。エージェントが導入されたことで、これらを省略してはいけないという重要性はさらに高まっています。
エージェントから最大の効果を発揮できているのは、これらの基本原則を意図的に適用することに最も注力しているチームです。
謝辞
本記事は、Anthropic の教育チームの一員であるクリステン・スワンソンによって執筆されました。彼女は、この稿への貢献に対して、マット・ベル、エリック・オレスン、ハスナイン・ラカニ、シェール・クレイグ、ノラン・コディル、マイク・シラルディ、アレクサンドラ・トドロバ、およびモリー・ヴォーバーックに感謝の意を表します。
*Claude Code における エージェントチーム の使用や、Claude Tag の活用を通じて、マルチプレイヤー型エージェントの構築を開始しましょう。*
原文を表示
Working with AI used to mean one person interfacing with a single chat window. Over time, AI has become increasingly capable at handling complex, long-running work, like coding, research, and financial analysis. With this, we’ve seen many new ways to use AI—from the terminal and IDE to spreadsheets and decks—but the work has still very much been a “single-player” experience: one human worked with one agent to accomplish individual tasks.
This is changing with the release of tools like Claude Tag. Now, humans and agents can work together in the same workspace, collaborating in service of goals shared by a team. Work now looks a lot more like a *multiplayer game*, with teams of humans setting the strategy, and Claude executing the work.
This involves some new ways of working. At Anthropic, we’ve been testing the technology required to make human-agent teams successful for the last several months. In this article, we explain what multiplayer agents are, and the lessons we’ve learned for building with them.
What are multiplayer agents?
“Multiplayer agents” is how we refer here to AI models that work with many different humans at the same time. Much like regular agents, they have their own memory and skills. But in other respects they're quite different. They have their own credentials and they live in places where work happens. At Anthropic, that's inside team collaboration tools like Slack.
Here’s an example of a human-agent team analyzing a dataset together in Slack:
For agents to productively participate in a team channel, they need specific capabilities:
- Persistent memory, so they can remember goals and tune their execution towards them
- Credentials not tied to humans, so they can operate within safe, predictable guardrails
- Ongoing broad access to information, so they can learn how the organization works and take action to execute tasks in service of the team’s goals
These capabilities amount to the technical foundation required for an agent to participate productively across a team of many humans. However, making human-agent teams *successful* requires more than this: teams need specific ways of working and shared norms, too.
Lesson 1: Work in public and give agents broad context
Teams at Anthropic share information proactively and openly. This is especially true when agents are on the team, because agents build their understanding entirely from the text a team makes searchable: Slack, code, docs, and meeting notes. Private messages, hallway conversations, and restricted documents can’t provide agents with context. For an agent, if it’s not written down and accessible, it doesn’t exist.
Instead of deciding what information should be available to agents one doc or Slack channel at a time, we use clearly defined security boundaries that apply to entire Slack workspaces, as well as to meeting transcripts and doc libraries. Within the security boundary, context flows to every teammate—whether human or AI. Not only does this increase what agents and humans get access to, it also reduces confusion about what can be shared and with whom. Humans and agents alike find it difficult to navigate the soft boundaries of per-item sharing: *should this channel be public or private? Can I share this doc with that person? Is this agent allowed to see that thread?* A small number of clear, workspace-level boundaries removes decision fatigue from day-to-day work.
A high degree of transparency has a reward. For instance, agents that can read decisions from team meetings won't suggest tasks or projects that were deprioritized. Agents with access to product specs beyond their own team can recommend patterns that have succeeded for others. And because agents can read enormous volumes of text far faster than humans do, they routinely surface relevant work that humans would otherwise have missed. We lean on our agents heavily to stay informed and coordinated in a busy, fast-moving industry.
At Anthropic, working in public looks like:
- Choosing a handful of security boundaries at the company and creating workspaces and document sharing settings that match each security boundary
- Defaulting new communication channels to public within the organization, and ensuring decisions land in channels, docs, and meeting notes every time
- Writing artifacts and meeting notes so that agents can find them, since agents are now a primary consumer of team documentation
- Making sure AI has access to the right tools and information needed to get their job done
Defaulting information to be internally public can require cultural shifts. However, the difference between human-agent teams with context and those without is too stark to ignore.
Of course, some interactions are sensitive and will need to be private between a single human and AI. For those, with Claude Tag you can send @Claude a direct message, or you can use the existing Claude.ai and Claude Cowork applications. These tools give Claude access to private information via your personal MCP connectors, with the knowledge that your conversation and what you share with the agent will remain private.
Lesson 2: Every human and agent get a defined role with the right tools for the job
Human-agent teams share one roster, one set of artifacts, and one working space. Agents have their own credentials, skills, and tool access. Different agents also hold different roles: for instance, while one might own the data analysis for a project, another will hold and enforce the design standard, and a third will run research synthesis.
When a project kicks off, humans chat with the agents to figure out which roles to assign, and how the humans and agents will work together.
Once the jobs for humans and agents are clear, an agent might spin up other agents to make sure that specific tasks are handled by the agents with the right memory and appropriate access. Importantly, they need access to all the tools required to accomplish the job: one that handles data analysis might need access to BigQuery, and one that performs QA might need access to the Playwright MCP.
Clearly defined roles and responsibilities set human-agent teams up for success. Humans often work in the same threads the agents do, but they hold the roles only humans can hold. This ensures everything works together and human judgment is applied to the most important decisions. Without clear roles, people end up running fleets of personal AIs on the side, duplicating work and fracturing the team's context. Metrics tracking is a common case: a multiplayer agent can do the job once and let everyone see the same numbers.
At Anthropic, having clearly defined roles on human-agent teams looks like:
- An agreed-upon task set: the team's humans and its agents agree on who does what
- Humans and agents working in the same shared threads, so anyone can pick up where anyone left off
- Humans and agents that have access to the right tools to accomplish their respective jobs
- Descriptions of agents’ roles and scopes
An engineering team at Anthropic started creating rosters to help codify human and agent roles because it made driving their work much easier and more concrete. Some things that clicked for them early on:
- Specific roles also help humans easily track where responsibility for a task lies, whether that’s in individual tasks or an entire team’s set of responsibilities
- Writing skill files to define specific agents’ roles helps to make specialization easy, and allows people across the company to quickly stand up other agents of the same type
- The team adds new agents to focus on new areas when projects get more complex. For example, they added a release manager agent to deal with new software releases.
These methods let humans' mental model of a human-agent team scale as the number of agents grows.
Lesson 3: Set a north star to make agents more proactive
Although some agents at Anthropic simply complete assigned tasks, the most important ones proactively suggest new projects and workstreams. This often happens when a team that has already given its agents rich context and clear roles adds another guide: a north star.
North stars are ambitious, wide-reaching goals that help teams decide which tasks and workstreams are the right ones. At Anthropic, humans always set the north star, grounding it in the mission and goals of the business.
Once a north star is clearly articulated in writing, humans share it with the agents on their team. Then, importantly, humans choose which agents should proactively suggest new workstreams to help achieve this long-term goal. (It’s unlikely that every agent on the team will have the prerequisite skills and trust to proactively suggest work successfully.)
For example, an internal tools team with a north star to “make product onboarding more helpful” saw an agent proactively recommended copy revisions to the onboarding flow error messages. These changes measurably increased onboarding success the following week.
At Anthropic, setting a north star looks like:
- Having humans discuss, debate, and document an ambitious north star goal for their human-agent team—one that’s rooted in the company’s mission and business goals
- Sharing the north star with agents on the team and explicitly naming which agents can proactively recommend new workstreams
- Keeping high-fidelity human time protected on the calendar, with meetings now focused on the most important work
A clear north star gives agents a consistent direction to work toward and meaningful opportunities to proactively support a team’s work.
Lesson 4: Build trust over time
Teams at Anthropic grant agents autonomy in proportion to demonstrated reliability, then expand it deliberately. Engineers have successfully dispatched agents on their team to handle 500 bug fixes independently, but things certainly didn’t start off that way.
When a new human colleague joins the team, it takes time to assess their capabilities and develop strong working routines. It usually takes multiple feedback cycles to externalize all the tacit information about how tasks are best completed. The same is true for agents. Users have to experiment with giving agents many different tasks so they can learn what the agent is capable of, how to clearly describe the goal, what skill files it needs, and what prompts work best to elicit a desired behavior. It’s also important to retest tasks as models change and improve. Prompts may need re-wording and guardrails that used to be helpful may constrain a smarter model from pursuing more creative solutions.
Notably, we’ve found that the best long-running agents have many different ways to verify their work before a human looks at it. Code has tests, of course, but most other work can be verified as well. For example, technical docs can have rubrics and style guides applied to them. When humans set the bar and ensure all work assigned to an agent can be vetted, quality stays high and doesn’t drift from the original intention. Separately, as with humans, it often helps to give one agent the job of doing the task and another agent the job of checking the first agent’s work. This is often called the “Doer-Verifier” agent harness.
At Anthropic, building trust with agents over time looks like:
- Reviewing agent work manually in the beginning to vet quality, provide feedback, and design task verification checklists
- Telling the agent to use a “verifier” agent to check its work as part of the task
- Building reflection into the cycle and asking agents to review their own misses so work improves over time
- Tracking which kinds of tasks each agent has earned autonomy on and expanding scope per task type after repeated successes
One engineering leader at Anthropic took on a new team with a big backlog. To get a handle on it, he invited a few humans and a few agents to help him sort through the backlog and prioritize what was most important. One set of agents on the team read through all of the items in the backlog, figured out if anyone was working on the items, and assigned a complexity score to anything that was unowned. The other set read from the list, filtered to the medium and low complexity items, and created code changes. At the beginning, humans reviewed every decision made by an agent and marked any that required human input. Then the humans taught the agents to surface those decisions to humans directly, ensuring that decisions with hard tradeoffs always had a human in the loop.
Every week, the leader and his team asked the agents to compile a weekly report that included “lessons & missteps” so the agents would keep track of mistakes and avoid making them again in the future. Over time, the leader was able to give more and more complex code changes to his agents and spend less time guiding the agents’ day to day tasks.
And once the agents were more independent, the leader coached them to treat human attention as the scarce resource it is: to batch questions to be answered in a single pass, repeat key context to get a human up to speed quickly, and limit how many things each human sees at once.
Helping agents communicate well ensures that they remain helpful and effective. Some people have agents in their team with the sole role of deciding how to batch and elevate only the most important communication for human team members. Others set guardrails around how much work agents should do per day, so that humans are able to meaningfully engage with the work. Such guardrails ensure that humans maintain skills that are important to them, and that the number of items requiring human review stays sustainable.
Questions to ask
As you’re laying the foundation for your human-agent teams, consider the following questions:
- Is all the information and access that agents and humans need both public and broadly searchable?
- Can you write down your team's roster (humans and agents), and say what each member owns?
- Does every human and agent on the team have access to the right tools to perform their job?
- Do you have rubrics or tests for humans and agents to verify key work products?
- Does your team have a clear north star that everyone can reference?
Moving forward
None of these patterns are new—at least not for humans. A strong north star, clear roles, strong documentation, a shared bar for quality, and room to learn from mistakes are the healthy team habits we’ve known for decades. Agents just make it even more important not to skip them.
The teams getting the most from their agents are the ones who are most intentional about applying these fundamentals.
Acknowledgements
This article was written by Kristen Swanson, a member of the Education team at Anthropic. She’d like to thank Matt Bell, Erik Olesund, Hasnain Lakhani, Shale Craig, Nolan Caudill, Mike Schiraldi, Aleks Todorova, and Molly Vorwerck for their contributions to this piece.
*Start building multiplayer agents using *agent teams* in Claude Code or by using *Claude Tag*. *
関連記事
Anthropic と OpenAI の 2700 万ドルの政治代理戦争が引き分けに終わる
ニューヨーク州議会議員のアレックス・ボレス氏を巡り、Anthropic と OpenAI が 2700 万ドル規模で争った政治的代理戦争は、ボレス氏が民主党予備選で僅差で敗れたことで引き分けに終わった。
Anthropic、Slack 内に「職場用 AI エージェント」を直接導入
Anthropic は Slack の共有チャンネルにチャットモデルを統合する新機能「Claude Tag」のベータ版をリリースした。これにより、ユーザーは@Claudeと入力して AI をグループスレッドに呼び出し、タスクの委任や出力の確認が可能になる。
[AINews] クロードタグ:Slack におけるマルチプレイヤー、能動的、永続型エージェント
Anthropic は Slack で動作する「Claude Tag」を発表し、複数のエージェントが協調して作業を行う機能や、能動的・永続的なエージェントの実現を可能にする新世代の技術を提供した。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み