Amazon Bedrock AgentCoreとAmazon Bedrock Knowledge Basesを使用したインテリジェントイベントエージェントの構築
Amazon Bedrock AgentCoreを用いて、参加者の好みを記憶し、時間とともにパーソナライズされた体験を構築する生産準備完了のイベントアシスタントを迅速にデプロイする方法を紹介。
キーポイント
Amazon Bedrock AgentCoreを使用して、大規模イベント向けのインテリジェントなAIアシスタントを迅速に構築・デプロイする方法を解説
AgentCoreのMemory、Identity、Runtimeコンポーネントにより、カスタムストレージ不要の会話コンテキスト保持、セキュアな認証、サーバーレススケーリングを実現
Amazon Bedrock Knowledge Basesを活用した管理型RAGにより、イベントデータの効率的な検索とパーソナライズされた体験を提供
数千人の同時ユーザーに対応するエンタープライズグレードのセキュリティと信頼性をインフラ管理なしで実現可能
影響分析・編集コメントを表示
影響分析
この記事は、AIアシスタントのプロトタイプ段階から本番環境への移行における主要な課題(セキュリティ、スケーラビリティ、信頼性)を解決する実用的なソリューションを提供しています。AWSのマネージドサービスを組み合わせることで、複雑なイベント管理におけるパーソナライズされたAI体験を迅速に実装できる道筋を示しており、企業のAI導入加速に貢献する可能性があります。
編集コメント
AWSが提供する包括的なAIエージェントプラットフォームの実践的な応用例として、技術的な詳細とビジネス価値の両方を明確に示した良質な技術記事です。
Amazon Bedrock AgentCore と Amazon Bedrock Knowledge Bases を活用したインテリジェントなイベントエージェントの構築
大規模な会議やイベントでは、数百セッションやワークショップ、スピーカーのプロフィール、会場マップ、そして常に変化するスケジュールなど、膨大な量の情報が生成されます。基本的な AI アシスタントはイベントの物流に関する単純な質問には答えることができますが、参加者が複雑で数日間にわたる会議を効果的にナビゲートするために必要とするパーソナライズされたガイダンスや文脈認識を提供できないケースがほとんどです。さらに重要なのは、これらのプロトタイプを実証から本番環境へ移行する際、エンタープライズセキュリティ、数千名の同時ユーザーへのスケーラビリティ、そして信頼性の高いパフォーマンスを実現するには、通常、インフラストラクチャの開発に数ヶ月を要することです。
この記事では、Amazon Bedrock AgentCore のコンポーネントを活用して、すぐに本番環境で利用可能なイベントアシスタントを迅速にデプロイする方法を示します。参加者の好みを記憶し、時間をかけてパーソナライズされた体験を構築するインテリジェントなコンパニオンを作成しますが、本番環境へのデプロイにおける重労働は Amazon Bedrock AgentCore が担当します。具体的には、カスタムストレージソリューションなしで会話の文脈と長期的な好みを維持するための「Amazon Bedrock AgentCore Memory」、セキュアなマルチ IDP 認証のための「Amazon Bedrock AgentCore Identity」、サーバーレススケーリングとセッション分離のための「Amazon Bedrock AgentCore Runtime」です。また、管理された RAG(Retrieval-Augmented Generation)およびイベントデータの検索には Amazon Bedrock Knowledge Bases を使用します。
最終的には、あらゆる対話を通じてより有益になっていくアシスタントのデプロイ方法を学びます。これは、参加者が最も価値のあるセッションを見つけられるようにする能動的なガイドであり、インフラ管理を一切行わずに、エンタープライズグレードのセキュリティと信頼性をもって、数千名の同時開催の会議参加者に対応できる準備が整います。
Amazon Bedrock AgentCore が初めての方は、この実装に取り組む前に、以下のブログ記事を確認して基礎概念を理解することをお勧めします:
Amazon Bedrock AgentCore Runtime(ランタイム)
Amazon Bedrock AgentCore Memory(メモリ)
Amazon Bedrock AgentCore Identity(アイデンティティ)
ソリューションアーキテクチャ
それでは、インテリジェントイベントエージェントのアーキテクチャとワークフローを見ていきましょう。完全な実装は、この GitHub リポジトリで公開されており、ご自身の AWS アカウントでこのソリューションをデプロイするためのガイド付きノートブックが用意されています。
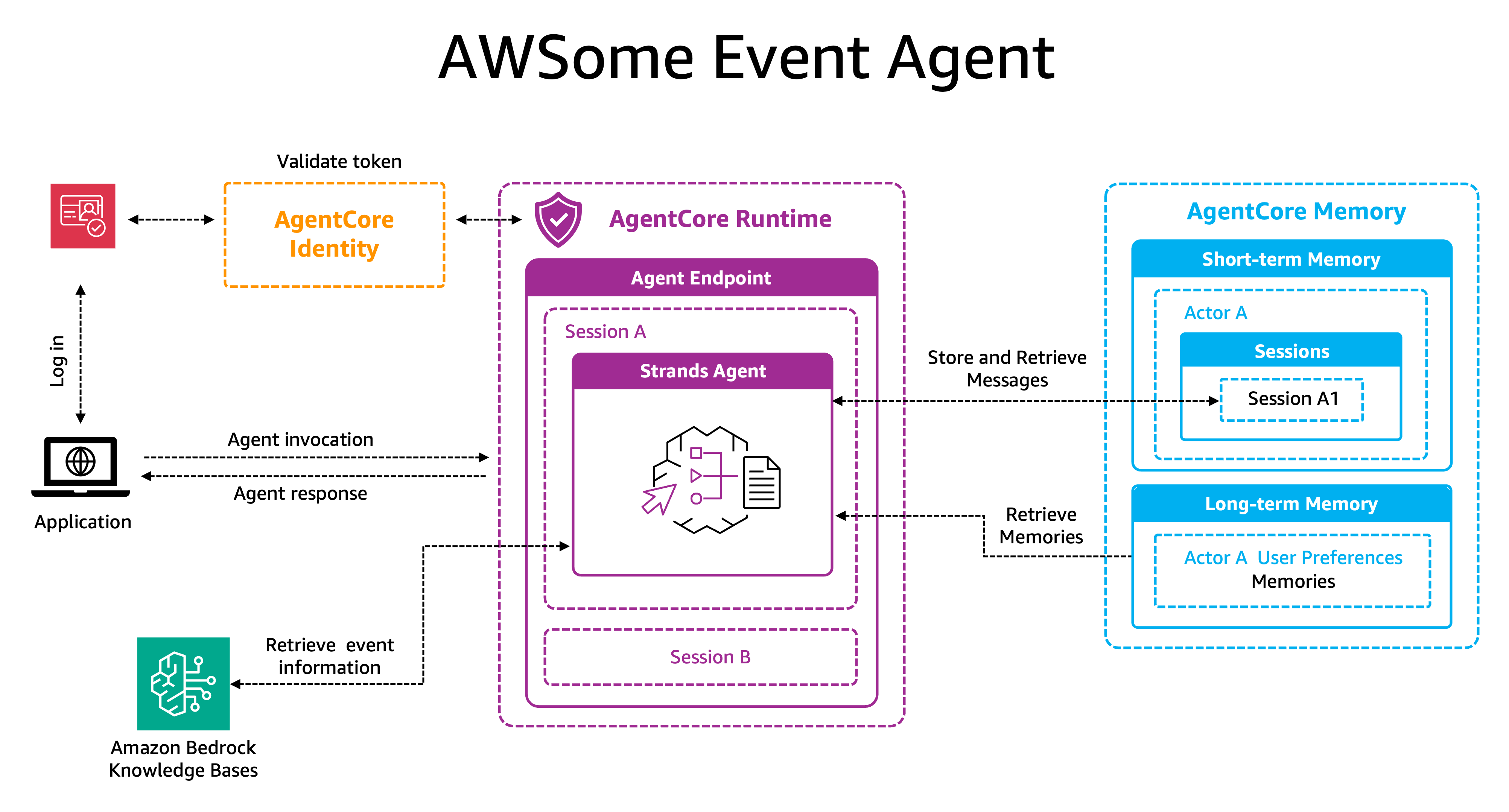
ソリューションの動作原理
それでは、異なるセクションを詳しく見ていきましょう:
- ユーザーログインとアイデンティティ取得
ユーザーは Amazon Cognito(AgentCore Identity は Okta、Auth0、OIDC 準拠 IDP など他のアイデンティティプロバイダーもサポート)を使用してアプリケーションにログインし、認証が成功するとベアートークンが発行されます。このトークンにはユーザーに関する情報が含まれており、ワークフロー全体を通じて認証およびユーザー固有データの取得に使用されます。
- エージェントの呼び出しと初期化
ユーザーがアプリケーションと対話してクエリを送信すると、アプリケーションは Amazon Bedrock AgentCore Runtime を呼び出し、3 つの主要パラメータを渡します:ユーザーのクエリ、セッション ID(例:SessionA
最初の対話において、Strands Agent は Amazon Bedrock AgentCore Runtime 内で初期化され、Amazon Bedrock AgentCore Memory の長期ストレージから利用可能なすべてのユーザー設定を取得し、パーソナライズされたコンテキストで自身を準備します。同じセッション内のその後の対話では、エージェントはすでに確立したコンテキストを用いて会話を継続します。
- メッセージ処理
エージェントは、Amazon Bedrock AgentCore Memory の短期ストレージにユーザーとアシスタントの両方のメッセージを保存し、actor_id を含みます。
各メモリ戦略は、パターン認識と自然言語理解(Natural Language Understanding)を用いて生会話データを分析し、ユーザー設定などの特定の種類の価値ある情報を特定し、長期保持に値する意味のある洞察を抽出します。その後、システムはこの抽出された情報を標準化されたメモリレコードとして構造化し、関連メタデータでタグ付けして、長期メモリの専用名前空間に保存します。これにより、エージェントは複数のセッションにわたってユーザーに対する理解を徐々に洗練させていくことができます。
- 知識とメモリの検索
ユーザーの要求に応えるために、エージェントは専門的なツールをトリガーする可能性があります。Amazon Bedrock のナレッジベースを呼び出して、セッションの説明、スケジュール、スピーカーの経歴など、最新のイベント詳細を取得できます。
- レスポンス生成
エージェントは、長期記憶(パーソナライズされた参加者履歴)からの洞察、短期記憶(セッション内の直近のメッセージ)からのコンテキスト、およびナレッジベースからの現在のイベントデータという 3 つの層で強化されたクエリを処理します。その後、文脈に即したパーソナライズされたレスポンスを生成します。このアーキテクチャにより、「明日どのセッションに参加すべきか」といった単純なクエリが、パーソナライズされた体験へと変換されます。エージェントはユーザーが昨日気に入ったトピックを思い出し、現在の会話を考慮し、ユーザーの興味や履歴に合わせた具体的な推奨事項で応答します。
ソリューションコンポーネント
次に、ソリューションの各コンポーネントの役割について理解しましょう。
エージェント(AgentCore Runtime およびアイデンティティ統合)
イベントアシスタントソリューションの中核を担うのは、Amazon Bedrock AgentCore Runtime です。これはエージェントをホストするための安全なサーバーレス環境を提供するコンポーネントです。Runtime は、独立したマイクロ VM で実行され、それぞれが専用の CPU、メモリ、ファイルシステムリソースを持つセッションを通じて、ユーザーとのインタラクションの完全なライフサイクルを管理します。このセッションの分離により、数千名の会議参加者が同時にパーソナライズされたエージェントインスタンスと対話しても、セッション間のデータ汚染が生じることはありません。
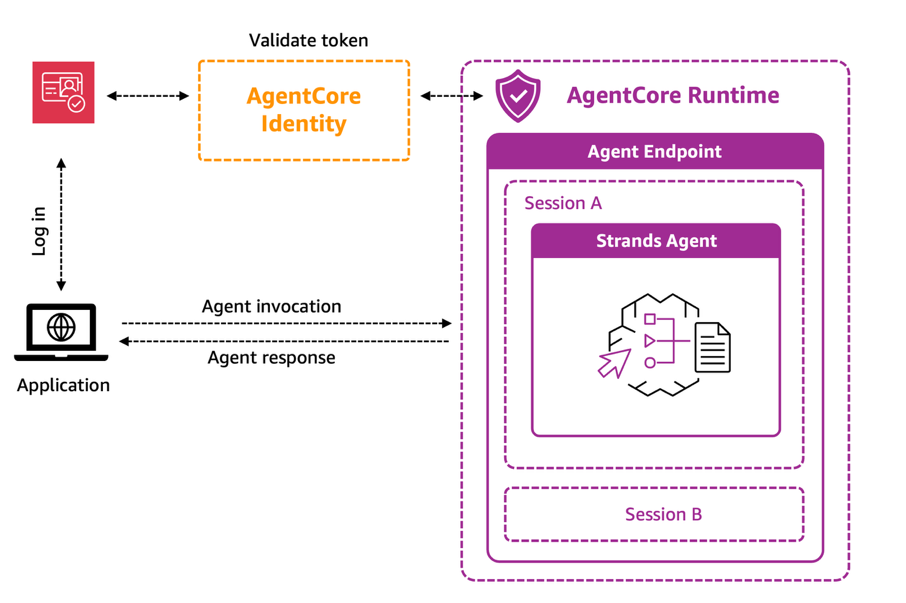
セキュリティと認証は、Amazon Bedrock AgentCore Identity によって処理され、これは Amazon Cognito(および他の IDP)とシームレスに統合されます。参加者がイベントアシスタントへクエリを送信すると、Amazon Bedrock AgentCore Identity は、インタラクションを続行する前に Amazon Cognito からのベアラートークンを検証します。このベアラートークンはヘッダーを通じて伝播され、エージェントはこのトークンを取得して Amazon Cognito のディスカバリーサーバーを呼び出し、ユーザーの sub およびその他の関連ユーザー情報を抽出します。本ユースケースでは、ユーザーの sub を actor_id として使用します。
Runtime のスケーラブルなホスティングインフラストラクチャと Identity の認証フレームワークを組み合わせることで、イベントアシスタントはより安全に大規模会議に対応しつつ、各参加者に対して一貫してパーソナライズされたガイダンスを提供することができます。
Amazon Bedrock AgentCore Memory は、単なる Q&A ツールから真にパーソナライズされたガイドへと変えるための重要な文脈認識機能を提供します。このサービスは短期記憶と長期記憶で構成されており、両者が連携することで、参加者とイベントアシスタントの間で継続的かつ進化し続ける関係性を可能にします。
短期記憶:会話の捕捉
短期記憶は、インタラクションが始まる場所です。会話が進行するにつれて、エージェントは各メッセージ交換を不変のイベントとして短期記憶に同期して保存します。これらのイベントは actor_id によって階層的に整理されます。
この組織構造には2つの重要な目的があります。第一に、各会話の時系列ナラティブを維持し、対話の自然な流れを保つことです。第二に、厳密な分離を提供することです。セッション A1 におけるアクター A の会話は、セッション B や他のアクターのセッションとは完全に独立しています。これによりプライバシーが確保され、エージェントは関連しないデータをロードすることなく、正確に必要な会話文脈を即座に取得できます。エージェントは短期記憶から直近のメッセージを素早く取得して会話の連続性を維持します。参加者が「そのセッションは何時ですか?」といったフォローアップ質問をした場合、エージェントは直前の会話履歴に即座アクセスできるため、どのセッションについて話されたかを把握しています。
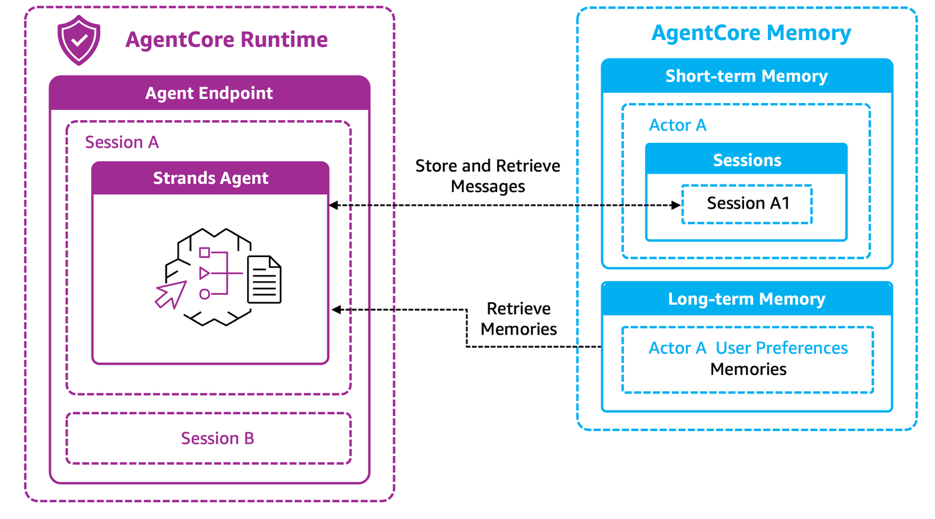
長期記憶:永続的な知性の構築
短期記憶は発言された内容を捉えるのに対し、長期記憶は重要な要素を抽出します。会話が行われる間、AgentCore Memory サービスはこれらの対話を自動的に処理し、セッションを超えて持続する意味のある洞察を特定して保存します。当社のイベントエージェントは、セッション形式、トピック、またはプレゼンテーションスタイルに関する明示的な嗜好を捉えるために「ユーザーの好み(User Preferences)」戦略を使用しています。例えば、「講義よりも実践的なワークショップを好む」や「サーバーレスおよび機械学習のトピックに興味がある」といった内容です。
これらの好みは、長期記憶内の専用名前空間(例:/event-agent/actor-A/preferences)に保存されます。
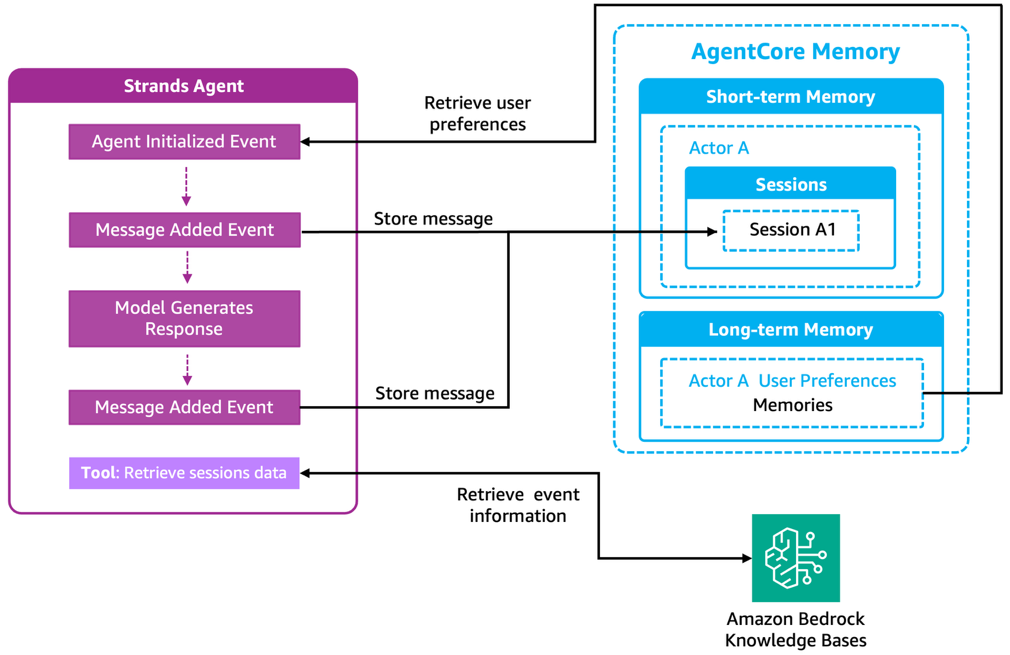
エージェントとメモリのオーケストレーション
Strands エージェントと AgentCore Memory の間のシームレスな統合は、エージェントフックによってサポートされています。これは、エージェントのライフサイクル全体を通じて自動的にメモリ操作をトリガーするイベント駆動型の接点です。以下の図に示す通り:
「Agent Initialized Event」フックは、セッション開始時に長期記憶からユーザーの好みを取得し、参加者の興味や好みのセッションタイプを読み込んで、最初のクエリからパーソナライズされた推奨を提供できるようにします。
「Message Added Event」フックは、各ユーザーメッセージとアシスタントメッセージを捕捉し、会話履歴を維持するために同期して短期記憶に保存します。
注:AgentCore は自動的にメモリツールを実装する自動メモリマネージャーを提供していますが、このソリューションではフックを使用し、イベントアシスタントの特定のワークフローに対してメモリオペレーションがいつどのように呼び出されるかを精密に制御することで、微調整された最適化を実現しています。
これらの自動操作に加え、情報が不足している場合は、エージェントは「セッションデータの取得」ツールを使用して、Amazon Bedrock のナレッジベースから現在のイベント詳細を照会します。
このデュアルアプローチ—起動時に必要なコンテキストをプリロードし、必要に応じて詳細を選択的に取得する—は、不要な情報でセッションコンテキストを肥大化させることなく、速度と精度の両方を提供します。
Amazon Bedrock ナレッジベース
AgentCore Memory はパーソナライズされたコンテキストと会話履歴を維持しますが、大規模なカンファレンスでは数百のセッション詳細、スピーカープロフィール、会場マップ、スケジュール更新など、効率的な整理と検索が必要な構造化情報が膨大に生成されます。
Amazon Bedrock Knowledge Bases は、ファウンデーションモデルをデータソースに接続することで、検索拡張生成(RAG)をサポートする完全管理型サービスです。ドキュメントの取り込み、処理、インデックス化を自動的に処理し、ベクトルデータベースに保存されるベクトル埋め込みに変換します。これにより、エージェントは意味や文脈に基づいて情報を取得するセマンティック検索を実行できるようになります。
このアーキテクチャでは、知識ベースが Strands フレームワーク内の専用ツールとして実装されています。参加者がセッション、スピーカー、会場運営に関する具体的な質問をした際、エージェントはこのツールを呼び出して、正確で最新の情報を取得します。メモリと知識ベースの統合は強力な組み合わせを生み出します。例えば、「どの AI セッションに参加すべきか」という質問に対し、エージェントは知識ベースからセッション詳細を取得すると同時に、参加者が以前に表明した興味に基づいて推奨事項をフィルタリングし優先順位をつけるためにメモリを活用します。これにより、事実に基づく完全性と個人的な関連性の両方を備えた回答が可能となり、大規模カンファレンスの圧倒的な複雑さを管理可能で個別化されたガイダンスへと変換するのを支援します。
本稿では、Amazon Bedrock AgentCore コンポーネントを活用してイベントアシスタントを迅速にプロダクション環境へ展開する方法について探求しました。
原文を表示
Building intelligent event agents using Amazon Bedrock AgentCore and Amazon Bedrock Knowledge Bases
Large conferences and events generate overwhelming amounts of information—from hundreds of sessions and workshops to speaker profiles, venue maps, and constantly updating schedules. While basic AI assistants can answer simple questions about event logistics, most fail to deliver the personalized guidance and contextual awareness that attendees need to navigate complex, multi-day conferences effectively. More importantly, moving these prototypes from demo to production—with enterprise security, scalability for thousands of concurrent users, and reliable performance—typically requires months of infrastructure development.
This post demonstrates how to quickly deploy a production-ready event assistant using the components of Amazon Bedrock AgentCore. We’ll build an intelligent companion that remembers attendee preferences and builds personalized experiences over time, while Amazon Bedrock AgentCore handles the heavy lifting of production deployment: Amazon Bedrock AgentCore Memory for maintaining both conversation context and long-term preferences without custom storage solutions, Amazon Bedrock AgentCore Identity for secure multi-IDP authentication, and Amazon Bedrock AgentCore Runtime for serverless scaling and session isolation. We will also use Amazon Bedrock Knowledge Bases for managed RAG and event data retrieval.
By the end, you’ll learn how to deploy an assistant that grows more helpful with every interaction – a proactive guide that makes sure attendees can discover their most valuable sessions – ready to serve thousands of concurrent conference attendees with enterprise-grade security and reliability, all without managing infrastructure.
If you are new to Amazon Bedrock AgentCore, feel free to review the following blog posts to understand the foundational concepts before diving into this implementation:
Amazon Bedrock AgentCore Runtime
Amazon Bedrock AgentCore Memory
Amazon Bedrock AgentCore Identity
Solution architecture
Let’s walk through the architecture and workflow of our intelligent event agent. The complete implementation is available in this GitHub repository which provides a guided notebook you can follow to deploy this solution in your own AWS account.
How the solution works
Let’s explore the different sections:
- User login and identity retrieval
The user logs in to the application using Amazon Cognito (AgentCore Identity also supports other identity providers such as Okta, Auth0, and OIDC-compliant IDPs), which generates a bearer token upon successful authentication. This token contains information about the user and will be used throughout the workflow for authentication and retrieving user-specific data.
- Agent invocation and initialization
When the user interacts with the application and submits a query, the application calls Amazon Bedrock AgentCore Runtime with three key parameters: the user’s query, a session ID (for example, SessionA
On the first interaction, the Strands Agent initializes within Amazon Bedrock AgentCore Runtime and retrieves any available user preferences from the long-term storage of Amazon Bedrock AgentCore Memory, priming itself with personalized context. For subsequent interactions within the same session, the agent continues with the conversation using the context it has already established.
- Message processing
The agent stores both user and assistant messages in the short-term storage of Amazon Bedrock AgentCore Memory, containing both actor_id
Each memory strategy uses pattern recognition and natural language understanding to analyze the raw conversation data, identifying specific types of valuable information—such as user preferences—and extracting meaningful insights that warrant long-term retention. The system then structures this extracted information into standardized memory records, tags them with relevant metadata, and stores them in dedicated namespaces within long-term memory, for the agent to use to build an increasingly refined understanding of users across multiple sessions.
- Knowledge and memory retrieval
To fulfill the user’s request, the agent may trigger specialized tools. It can call an Amazon Bedrock knowledge base to fetch up-to-date event details such as session descriptions, schedules or speaker biographies.
- Response generation
The agent processes the query enriched with three layers of context: insights from long-term memory (personalized attendee history), context from short-term memory (recent messages in the session), and current event data from the knowledge base. It then generates a contextualized and personalized response.This architecture transforms a simple query like “What sessions should I attend tomorrow?” into a personalized experience—the agent recalls topics the user liked yesterday, considers the current conversation and responds with specific recommendations tailored to the user’s interests and history.
Solution components
Let’s now understand the role of each component of the solution.
The agent (AgentCore Runtime and identity integration)
At the core of our event assistant solution is the Amazon Bedrock AgentCore Runtime, a component which provides a secure, serverless environment for hosting our agent. Runtime manages the complete lifecycle of user interactions through isolated sessions—each running in dedicated microVMs with separate CPU, memory, and filesystem resources. This session isolation makes sure that thousands of conference attendees can simultaneously interact with personalized instances of the agent without cross-session data contamination.
Security and authentication are handled through Amazon Bedrock AgentCore Identity, which integrates seamlessly with Amazon Cognito (and other IDPs). When an attendee sends a query to the event assistant, Amazon Bedrock AgentCore Identity validates the bearer token from Amazon Cognito before allowing the interaction to proceed. The bearer token is propagated through headers, and the agent retrieves this token to call the Amazon Cognito discovery server, extracting the user’s sub and other related user information. For this use case, we use the user sub as the actor_id
By combining the scalable hosting infrastructure of Runtime with the authentication framework of Identity, our event assistant can serve massive conferences more securely while delivering consistently personalized guidance to each individual attendee.
Amazon Bedrock AgentCore Memory provides the critical context awareness that transforms our event assistant from a simple Q&A tool into a truly personalized guide. The service is composed of short-term and long-term memory, which work together to enable continuous, evolving relationships between attendees and the event assistant.
Short-term memory: Capturing the conversation
Short-term memory is where interactions begin. As conversations unfold, the agent synchronously stores each message exchange as an immutable event in short-term memory. These events are organized hierarchically by actor_id
This organizational structure serves two critical purposes. First, it maintains the chronological narrative of each conversation, preserving the natural flow of the dialogue. Second, it provides precise isolation—Actor A’s conversation in Session A1 remains separate from Session B or from another actor’s sessions. This facilitates privacy and enables the agent to retrieve exactly the right conversation context without loading unrelated data. The agent can quickly retrieve recent messages from short-term memory to maintain conversation continuity. When an attendee asks a follow-up question like “What time is that session?” the agent knows which session was just discussed because it has immediate access to the conversation history.
Long-term memory: Building persistent intelligence
While short-term memory captures what was said, long-term memory extracts what matters. As conversations occur, the AgentCore Memory service automatically processes these interactions to identify and store meaningful insights that persist across sessions. Our event agent uses a User Preferences strategy to capture explicit preferences about session formats, topics, or presentation styles. For example, “Prefers hands-on workshops over lectures” or “Interested in serverless and machine learning topics.”
These preferences are stored in a dedicated namespace within long-term memory (for example, /event-agent/actor-A/preferences
Agent and memory orchestration
The seamless integration between the Strands Agent and AgentCore Memory is supported through agent hooks—event-driven touchpoints that automatically trigger memory operations throughout the agent’s lifecycle. As shown in the following diagram:
The Agent Initialized Event hook retrieves user preferences from long-term memory when a session begins, loading the attendee’s interests and preferred session types to enable personalized recommendations from the first query.
The Message Added Event hooks capture each user and assistant message, synchronously storing them in short-term memory to maintain conversation history.
Note: While AgentCore provides an automated memory manager that implements memory tools automatically, this solution uses hooks for precise control over when and how memory operations are invoked—for fine-tuned optimization for the event assistant’s specific workflow.
Beyond these automatic operations, if there isn’t enough information, the agent then uses the Retrieve sessions data tool to query the Amazon Bedrock knowledge base for current event details.
This dual approach—preloading essential context at startup and selectively retrieving details on-demand—delivers both speed and precision without bloating the session context with unnecessary information.
Amazon Bedrock Knowledge Bases
While AgentCore Memory maintains personalized context and conversation history, large conferences generate vast amounts of structured information—hundreds of session details, speaker profiles, venue maps, and schedule updates—that require efficient organization and retrieval.
Amazon Bedrock Knowledge Bases is a fully managed service that supports Retrieval-Augmented Generation (RAG) by connecting foundation models to your data sources. It automatically handles the ingestion, processing, and indexing of documents, converting them into vector embeddings stored in a vector database. This allows agents to perform semantic searches—retrieving information based on meaning and context rather than exact keyword matches.
The architecture implements the knowledge base as a specialized tool within the Strands framework. When attendees ask specific questions about sessions, speakers, or venue logistics, the agent invokes this tool to retrieve precise, up-to-date information. The integration between memory and knowledge base creates a powerful combination. When an attendee asks, “Which AI sessions should I attend?”, the agent retrieves session details from the knowledge base while using memory to filter and prioritize recommendations based on the attendee’s previously expressed interests. This facilitates responses that are both factually complete and personally relevant, helping transform the overwhelming complexity of large conferences into manageable, tailored guidance.
In this post, we’ve explored how you can use Amazon Bedrock AgentCore components to rapidly productionize an event assistant—taking it from pro
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み