Amazon Nova MicroとAmazon Bedrockオンデマンド推論を用いたコスト効率の良いカスタムText-to-SQL
AWSはAmazon Bedrockのオンデマンド推論とLoRA微調整を組み合わせ、カスタムSQL方言向けに「Amazon Nova Micro」を活用したコスト効率の高いtext-to-SQLソリューションの実装例と運用コストを公開している。
キーポイント
永続ホスティングの課題とオンデマンド推論による解決
カスタムSQL方言への対応にはモデル微調整が不可欠だが、永続インフラの維持はアイドル時に固定コストを発生させるため、サーバーレスのオンデマンド推論が実用的な代替手段となる。
LoRAとペイ・パー・トークン方式の技術的融合
低ランク適応(LoRA)による効率的な微調整とAmazon Bedrockの従量課金モデルを組み合わせ、利用量に応じたスケーラブルなコスト構造とインタラクティブアプリケーションに耐えうるレイテンシを実現する。
実証された運用コストとスケーラビリティ
月2万2000クエリのサンプルトラフィックで月額0.80ドルを維持し、永続ホスティングと比較して明確なコスト節約効果を確認した。
影響分析・編集コメントを表示
影響分析
AWSのこのアプローチは、エンタープライズAI開発における「モデルホスティングコスト」と「カスタムドメイン対応」のトレードオフを解消する実用的なパターンを示している。特にオンデマンド推論とLoRAの組み合わせは、リソース制約のあるチームや特定のDBスキーマを持つ組織にとって、大規模言語モデルの現場導入ハードルを大幅に下げる可能性がある。
編集コメント
技術ブログ特有のベンダー宣伝色が強いものの、具体的な数値(月額0.80ドル/2.2万クエリ)と技術トレードオフ(LoRAアダプタのレイテンシ vs コスト削減)を明示している点は評価できる。実装ガイドとして活用すれば、中小規模のAIプロジェクトにおける運用コスト管理の参考になるだろう。
Cost-efficient custom text-to-SQL using Amazon Nova Micro and Amazon Bedrock on-demand inference
Text-to-SQLの生成は、特にカスタムSQL方言やドメイン固有のデータベーススキーマを扱う場合、エンタープライズAIアプリケーションにおいて長年の課題となっています。基盤モデル(Foundation Models: FMs)は標準SQLで優れたパフォーマンスを示しますが、専門的な方言に対して本番環境レベルの精度を達成するにはファインチューニングが必要です。ただし、ファインチューニングは運用上のトレードオフをもたらします。カスタムモデルを永続的なインフラストラクチャでホストする場合、利用率がゼロの期間でも継続的なコストが発生します。
Amazon Bedrockのオンデマンド推論とファインチューニング済みAmazon Nova Microモデルを組み合わせることで、代替案が提供されます。LoRA(Low-Rank Adaptation)ファインチューニングの効率性と、サーバーレスかつトークン単位の課金方式(pay-per-token)の推論を組み合わせることで、組織は永続的なモデルホスティングに伴うオーバーヘッドコストなしに、カスタムText-to-SQLの機能を実現できます。LoRAアダプターの適用に伴う追加の推論時間オーバーヘッドがあるものの、テストではインタラクティブなText-to-SQLアプリケーションに適したレイテンシが確認され、コストはプロビジョニングされた容量ではなく実際の使用量に応じてスケールします。
本稿では、コスト効率性と本番環境対応の性能の両方を提供するため、カスタムSQL方言の生成用にAmazon Nova Microをファインチューニングする2つのアプローチを実演します。サンプルワークロード(workload)として月間22,000件のクエリを処理する当社の例では、月次コストが$0.80に抑えられ、永続的にホストされたモデルインフラストラクチャと比較してコスト削減を実現しました。
Prerequisites
これらのソリューションを展開するには、以下の準備が必要です。
- ビリングが有効化されたAWSアカウント(AWS account)
- アクセス用に設定された標準的なIAM権限とロール:
Amazon Bedrock Nova Microモデル
- Amazon SageMaker AI
- Amazon Bedrock Model customization(モデルカスタマイズ)
- Amazon SageMaker AIのトレーニング用ml.g5.48xlインスタンスのクォータ。
Solution overview
このソリューションは、以下の高レベルのステップで構成されます。
- 組織固有のSQL方言(SQL dialect)およびビジネス要件に特化した入出力ペア(I/O pairs)を用いて、カスタムSQLトレーニングデータセットを準備します。
- 準備したデータセットと選択したファインチューニング手法を用いて、Amazon Nova Microモデルのファインチューニングプロセスを開始します。
Amazon Bedrock model customization for streamlined deployment
- 詳細なトレーニングのカスタマイズと制御のためのAmazon SageMaker AI
- カスタムモデルをAmazon Bedrockにデプロイしてオンデマンド推論(on-demand inference)を利用し、インフラストラクチャ管理を不要とし、トークン使用量のみに対して課金されるようにします。
- カスタムSQL方言およびビジネスユースケースに特化したテストクエリを用いて、モデルの性能を検証します。
実際のこのアプローチを示すため、異なる組織のニーズに対応する2つの完全な実装パスを提供します。1つ目は、シンプルさと迅速なデプロイメントを優先するチーム向けに、Amazon Bedrockのマネージドモデルカスタマイズを使用します。2つ目は、ハイパーパラメータとトレーニングインフラストラクチャに対するより細かな制御を必要とする組織向けに、Amazon SageMaker AIのトレーニングジョブを使用します。両方の実装は同じデータ準備パイプラインを共有し、オンデマンド推論のためにAmazon Bedrockにデプロイされます。以下は各GitHubコードサンプルへのリンクです:
- Bedrockのマネージドモデルカスタマイズ
- Amazon SageMaker AIのトレーニングジョブ
以下のアーキテクチャ図は、データ準備、両方のファインチューニング手法、およびサーバーレス推論(serverless inference)を可能にするBedrockデプロイパスを含むエンドツーエンドのワークフローを示しています。
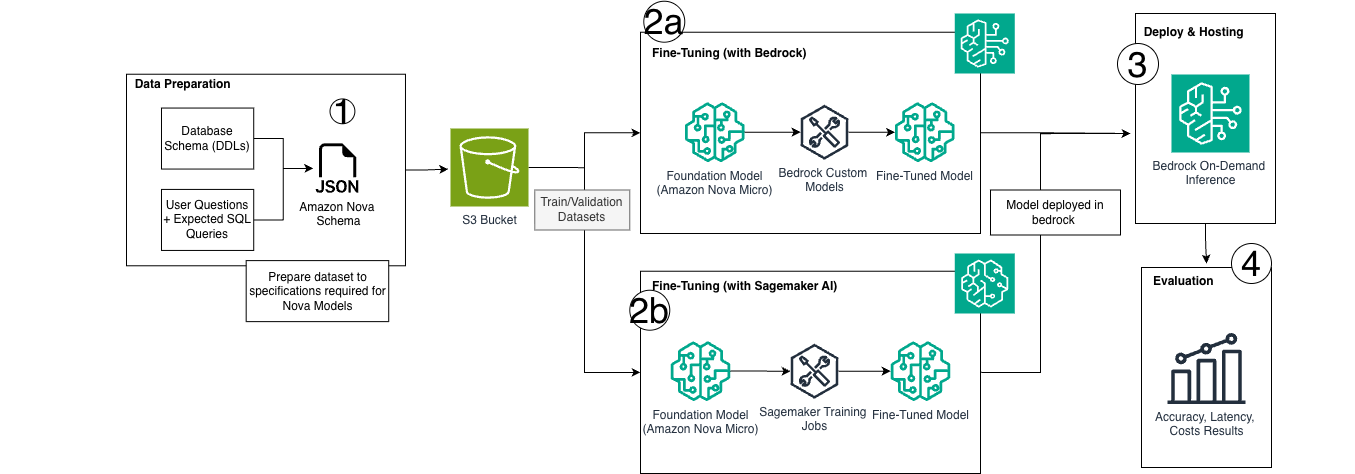
1. データセットの準備
当デモンストレーションでは、sql-create-contextデータセットを使用します。このデータセットは、WikiSQLとSpider datasetsを編集・統合したもので、多様なデータベーススキーマにわたる自然言語の質問とSQLクエリを組み合わせた78,000例以上のサンプルを含んでいます。単純なSELECT文から集計を伴う複雑なマルチテーブルジョインまで、クエリ複雑度の多様性により、このデータセットはtext-to-SQLファインチューニングの理想的な基盤を提供します。
データのフォーマットと構造
トレーニングデータは、ドキュメントで概説されているように構造化されています。これには、システムプロンプト(system prompt)の指示と、複雑さが異なるユーザークエリおよび対応するSQL応答を含むJSONLファイルの作成が含まれます。フォーマットされたトレーニングデータセットはその後、トレーニングセットと検証セット(validation sets)に分割され、JSONLファイルとして保存されてファインチューニングプロセスのためにAmazon Simple Storage Service(Amazon S3)にアップロードされます。
サンプル変換レコード
{
"schemaVersion": "bedrock-conversation-2024",
"system": [
{
"text": "You are a powerful text-to-SQL model. Your job is to answer questions about a database. You can use the following table schema for context: CREATE TABLE head (age INTEGER)"
}
],
"messages": [
{
"role": "user",
"content": [
{
"text": "Return the SQL query that answers the following question: How many heads of the departments are older than 56 ?"
}
]
},
{
"role": "assistant",
"content": [
{
"text": "SELECT COUNT(*) FROM head WHERE age > 56"
}
]
}
]
}
Amazon Bedrockファインチューニングのアプローチ
Amazon Bedrockのモデルカスタマイズ機能は、トレーニングインフラストラクチャのプロビジョニングや管理を不要とする、簡素化されたフルマネージド型のAmazon Novaモデルファインチューニングアプローチを提供します。この方法は、text-to-SQLユースケースに特化したカスタムモデルの性能を実現しつつ、迅速な反復と最小限の運用オーバーヘッドを追求するチームに最適です。
Amazon Bedrockのカスタマイズ機能を使用すると、トレーニングデータをAmazon S3にアップロードし、AWSコンソールまたはAPIを通じてファインチューニングジョブを設定できます。その後、AWSが基盤となるトレーニングインフラストラクチャを処理します。生成されたカスタムモデルはオンデマンド推論でデプロイでき、基本のNova Microモデルと同じトークンベースの価格を維持し、追加のマージンなしで提供されるため、可変ワークロードにとってコスト効果の高いソリューションとなります。このアプローチは、MLインフラストラクチャを管理せずにカスタムSQL方言用にモデルを迅速にカスタマイズする必要がある場合、運用の複雑さを最小限に抑えたい場合、または自動スケーリング付きのサーバーレス推論が必要な場合に適しています。
2a. Amazon Bedrockを使用したファインチューニングジョブの作成
Amazon Bedrockは、AWSコンソールとAWS SDK for Python(Boto3)の両方を使用してファインチューニングをサポートしています。AWSドキュメントには、両方のアプローチでトレーニングジョブを提出する方法に関する一般的なガイダンスが含まれています。当社の実装では、AWS SDK for Python(Boto3)を使用しました。GitHubサンプルリポジトリのサンプルノートブックを参照して、段階的な実装をご覧ください。
ハイパーパラメータの設定
ファインチューニングするモデルを選択した後、ユースケースに合わせてハイパーパラメータを設定します。Amazon Bedrock上でのAmazon Nova Microファインチューニングの場合、以下のハイパーパラメータをカスタマイズして、text-to-SQLモデルを最適化できます:
パラメータ 範囲/制約 目的 当社が使用した値
エポック 1~5 トレーニングデータセットを完全に通過する回数 5エポック
バッチサイズ(Batch Size)
Fixed at 1
Number of samples processed before updating model weights
1 (fixed for Nova Micro)
学習率(Learning Rate)
0.000001–0.0001
Step size for gradient descent optimization
0.00001 for stable convergence
学習率ウォームアップステップ(Learning Rate Warmup Steps)
0–100
Number of steps to gradually increase learning rate
10
注:これらのハイパーパラメータ(Hyperparameters)は、特定のデータセットとユースケースに合わせて最適化されています。最適な値はデータセットのサイズや複雑さによって異なる場合があります。サンプルデータセットでは、この構成によりモデルの精度とトレーニング時間(Training Time)のバランスが改善され、約2〜3時間で完了しました。
トレーニングメトリクス(Training Metrics)の分析
Amazon Bedrockはトレーニングおよび検証メトリクス(Training and Validation Metrics)を自動的に生成し、指定したS3出力先に保存します。これらのメトリクスには以下が含まれます:
- トレーニングロス(Training Loss):モデルがトレーニングデータにどれだけ適合しているかを測定
- 検証ロス(Validation Loss):未見のデータに対する汎化性能を示す
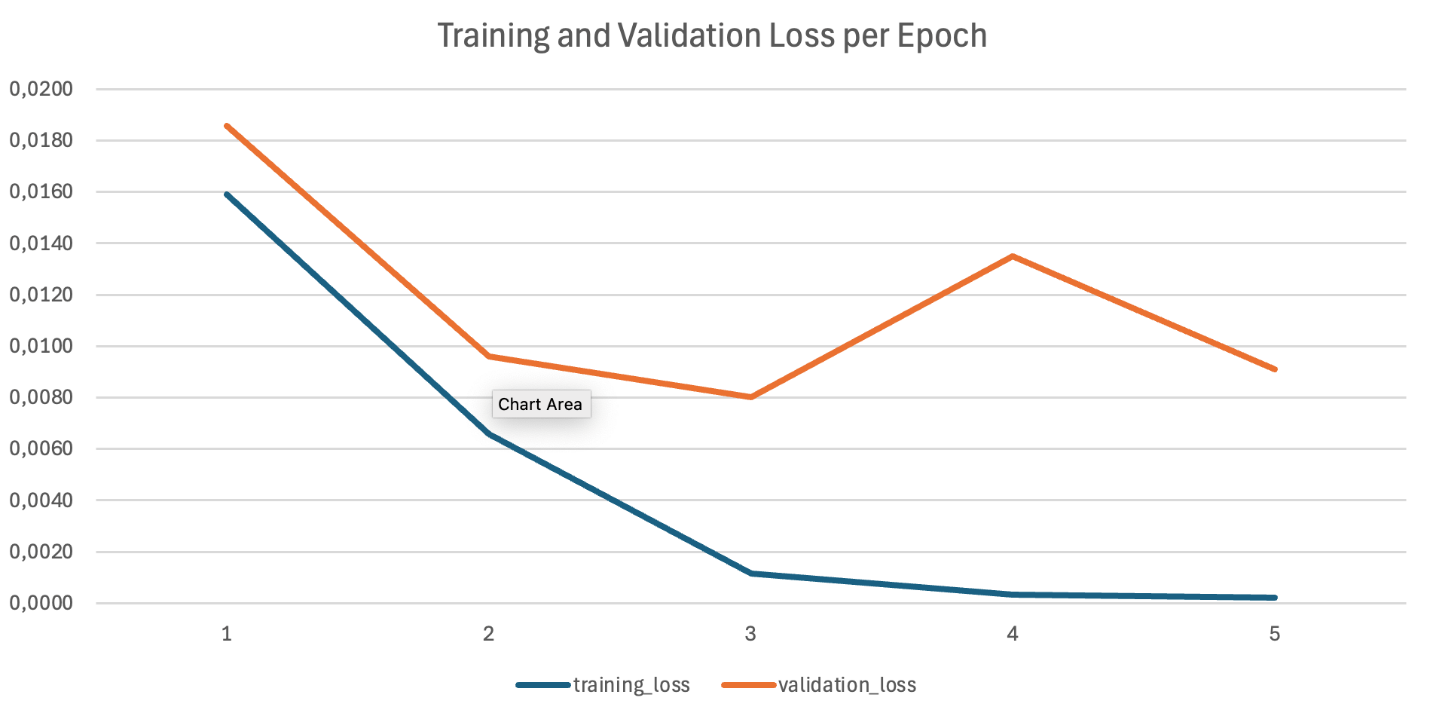
トレーニングロスと検証ロスの曲線は、成功したトレーニングを示しています。両方とも一貫して減少し、類似のパターンに従い、同等の最終値に収束しています。
3a. オンデマンド推論(On-Demand Inference)を使用したデプロイ
ファインチューニングジョブ(Fine-tuning Job)が正常に完了した後、オンデマンド推論を使用してカスタムNova Microモデルをデプロイできます。このデプロイオプションは自動スケーリング(Automatic Scaling)とトークン単位の従量課金制を提供するため、専用コンピューティングリソース(Compute Resources)のプロビジョニングなしで可変ワークロードに最適です。
カスタムNova Microモデルの呼び出し
デプロイ後、Amazon Bedrock Converse APIにおいてデプロイARNをモデルID(Model ID)として使用することで、カスタムテキストからSQLへのモデルを呼び出すことができます。
# デプロイARNをモデルIDとして使用
deployment_arn = "arn:aws:bedrock:us-east-1::deployment/"
# 推論リクエストの準備
response = bedrock_runtime.converse(
modelId=deployment_arn,
messages=[
{
"role": "user",
"content": [
{
"text": """データベーススキーマ:
CREATE TABLE sales (
id INT,
product_name VARCHAR(100),
category VARCHAR(50),
revenue DECIMAL(10,2),
sale_date DATE
);
質問:Electronicsカテゴリで収益が最も高い上位5つの製品は何ですか?"""
}
]
}
],
inferenceConfig={
"maxTokens": 512,
"temperature": 0.1, # 決定論的なSQL生成のための低温度
"topP": 0.9
}
)
# 生成されたSQLクエリを抽出
sql_query = response['output']['message']['content']['text']
print(f"生成されたSQL:\n{sql_query}")Amazon SageMaker AI fine-tuning approach
Amazon Bedrockのアプローチはマネージドトレーニング体験を通じてモデルのカスタマイズを簡素化しますが、より深い最適化制御を求める組織には、SageMaker AIのアプローチが有益となる場合があります。SageMaker AIは、効率性とモデルパフォーマンスに大きな影響を与える可能性のあるトレーニングパラメータに対して広範な制御を提供します。速度とメモリ最適化のためにバッチサイズ(batch size)を調整し、過学習を防ぐために層全体にわたってドロップアウト設定(dropout settings)を微調整し、トレーニングの安定性のために学習率スケジュール(learning rate schedules)を設定できます。特にLoRAファインチューニング(LoRA fine-tuning)の場合、マルチモーダルデータセットとテキストのみのデータセット用に最適化された異なる設定で、スケーリングファクターや正則化パラメータをカスタマイズするためにSageMaker AIを使用できます。さらに、特定のユースケース要件に合わせてコンテキストウィンドウサイズ(context window size)とオプティマイザー設定(optimizer settings)を調整することも可能です。完全なコードサンプルについては、以下のnotebookをご覧ください。
1b. Data preparation and upload
SageMaker AIファインチューニングアプローチにおけるデータの準備とアップロードプロセスは、Amazon Bedrockの実装と同じです。両方のアプローチとも、SQLデータセットをbedrock-conversation-2024スキーマ形式に変換し、データをトレーニングセットとテストセットに分割して、JSONLファイルをS3に直接アップロードします。
S3 prefix for training data
training_input_path = f's3://{sess.default_bucket()}/datasets/nova-sql-context'
Upload datasets to S3
train_s3_path = sess.upload_data(
path='data/train_dataset.jsonl',
bucket=bucket_name,
key_prefix=training_input_path
)
test_s3_path = sess.upload_data(
path='data/test_dataset.jsonl',
bucket=bucket_name,
key_prefix=training_input_path
)
print(f'Training data uploaded to: {train_s3_path}')
print(f'Test data uploaded to: {test_s3_path}')
2b. Creating a fine-tuning job using Amazon SageMaker AI
Select the model ID, recipe, and image URI:
Nova configuration
model_id = "nova-micro/prod"
recipe = "https://raw.githubusercontent.com/aws/sagemaker-hyperpod-recipes/refs/heads/main/recipes_collection/recipes/fine-tuning/nova/nova_1_0/nova_micro/SFT/nova_micro_1_0_g5_g6_48x_gpu_lora_sft.yaml"
instance_type = "ml.g5.48xlarge"
instance_count = 1
Nova-specific image URI
image_uri = f"708977205387.dkr.ecr.{sess.boto_region_name}.amazonaws.com/nova-fine-tune-repo:SM-TJ-SFT-latest"
print(f'Model ID: {model_id}')
print(f'Recipe: {recipe}')
print(f'Instance type: {instance_type}')
print(f'Instance count: {instance_count}')
print(f'Image URI: {image_uri}')
Configuring custom training recipes
Novaモデルのファインチューニング(fine-tuning)にAmazon SageMaker AIを使用する際の主な差別化要因は、トレーニングレシピ(training recipe)をカスタマイズできる点です。レシピとは、AWSが提供する事前設定済みのトレーニングスタックであり、トレーニングとファインチューニングを迅速に開始できるよう支援します。Amazon Bedrockの標準ハイパーパラメータ(hyperparameter)セット(エポック、バッチサイズ、学習率、ウォームアップステップ)との互換性を維持しつつ、レシピは以下の項目を通じてハイパーパラメータのオプションを拡張します:
- 正則化パラメータ(Regularization parameters):過学習(overfitting)を防ぐためのhidden_dropout、attention_dropout、ffn_dropout
- オプティマイザー設定(Optimizer settings):カスタマイズ可能なベータ係数と重み減衰(weight decay)の設定
- アーキテクチャ制御(Architecture controls):LoRAトレーニング用のアダプターランクとスケーリング係数
- 高度なスケジューリング(Advanced scheduling):カスタム学習率スケジュールとウォームアップ戦略
推奨されるアプローチは、デフォルト設定から始めてベースライン(baseline)を確立し、その後特定のニーズに基づいて最適化することです。以下は、最適化対象となる追加パラメータのリストの一部です。
パラメータ(Parameter)
範囲/制約(Range/Constraints)
目的(Purpose)
max_length(max_length)
1024~8192
入力シーケンス(input sequences)の最大コンテキストウィンドウサイズ(context window size)を制御
global_batch_size(global_batch_size)
16,32,64
モデルの重み(model weights)更新前に処理されるサンプル数
td style="padding: 10px;border: 1px so
原文を表示
Text-to-SQL generation remains a persistent challenge in enterprise AI applications, particularly when working with custom SQL dialects or domain-specific database schemas. While foundation models (FMs) demonstrate strong performance on standard SQL, achieving production-grade accuracy for specialized dialects requires fine-tuning. However, fine-tuning introduces an operational trade-off: hosting custom models on persistent infrastructure incurs continuous costs, even during periods of zero utilization.
The on-demand inference of Amazon Bedrock with fine-tuned Amazon Nova Micro models offers an alternative. By combining the efficiency of LoRA (Low-Rank Adaptation) fine-tuning with serverless and pay-per-token inference, organizations can achieve custom text-to-SQL capabilities without the overhead cost incurred by persistent model hosting. Despite the additional inference time overhead of applying LoRA adapters, testing demonstrated latency suitable for interactive text-to-SQL applications, with costs scaling by usage rather than provisioned capacity.
In this post, we demonstrate two approaches to fine-tune Amazon Nova Micro for custom SQL dialect generation to deliver both cost efficiency and production ready performance. Our example workload maintained a cost of $0.80 monthly with a sample traffic of 22,000 queries per month, which resulted in costs savings compared to a persistently hosted model infrastructure.
Prerequisites
To deploy these solutions, you will need the following:
- An AWS account with billing enabled
- Standard IAM permissions and role configured to access:
Amazon Bedrock Nova Micro model
- Amazon SageMaker AI
- Amazon Bedrock Model customization
- Quota for ml.g5.48xl instance for Amazon SageMaker AI training.
Solution overview
The solution consists of the following high-level steps:
- Prepare your custom SQL training dataset with I/O pairs specific to your organization’s SQL dialect and business requirements.
- Start the fine-tuning process on Amazon Nova Micro model using your prepared dataset and selected fine-tuning approach.
Amazon Bedrock model customization for streamlined deployment
- Amazon SageMaker AI for fine-grained training customization and control
- Deploy the custom model on Amazon Bedrock to use on-demand inference, removing infrastructure management while paying only for token usage.
- Validate model performance with test queries specific to your custom SQL dialect and business use cases.
To demonstrate this approach in practice, we provide two complete implementation paths that address different organizational needs. The first uses the managed model customization of Amazon Bedrock for teams prioritizing simplicity and rapid deployment. The second uses Amazon SageMaker AI training jobs for organizations requiring more granular control over hyperparameters and training infrastructure. Both implementations share the same data preparation pipeline and deploy to Amazon Bedrock for on-demand inference. The following are links to each GitHub code sample:
- Bedrock’s managed model customization
- Amazon SageMaker AI training jobs
The following architecture diagram illustrates the end-to-end workflow, which encompasses data preparation, both fine-tuning approaches, and the Bedrock deployment path that enables serverless inference.
1. Dataset preparation
Our demonstration uses the sql-create-context dataset. This dataset is a curated combination of WikiSQL and Spider datasets containing over 78,000 examples of natural language questions paired with SQL queries across diverse database schemas. This dataset provides an ideal foundation for text-to-SQL fine-tuning due to its variety in query complexity, from simple SELECT statements to complex multi-table joins with aggregations.
Data formatting and structure
The Training data is structured as outlined in the documentation. This involves creating JSONL files that contain system prompt instructions paired with user queries and corresponding SQL responses of varying complexity. The formatted training dataset is then split into training and validation sets, stored as JSONL files, and uploaded to Amazon Simple Storage Service (Amazon S3) for the fine-tuning process.
Sample Converted Record
{
"schemaVersion": "bedrock-conversation-2024",
"system": [
{
"text": "You are a powerful text-to-SQL model. Your job is to answer questions about a database. You can use the following table schema for context: CREATE TABLE head (age INTEGER)"
}
],
"messages": [
{
"role": "user",
"content": [
{
"text": "Return the SQL query that answers the following question: How many heads of the departments are older than 56 ?"
}
]
},
{
"role": "assistant",
"content": [
{
"text": "SELECT COUNT(*) FROM head WHERE age > 56"
}
]
}
]
}Amazon Bedrock fine-tuning approach
The model customization of Amazon Bedrock provides a streamlined, fully managed approach to fine-tuning Amazon Nova models without the need to provision or manage training infrastructure. This method is ideal for teams seeking rapid iteration and minimal operational overhead while achieving custom model performance tailored to their text-to-SQL use case.
Using the customization capabilities of Amazon Bedrock, training data is uploaded to Amazon S3, and fine-tuning jobs are configured through the AWS console or API. AWS then handles the underlying training infrastructure. The resulting custom model can be deployed using on-demand inference, maintaining the same token-based pricing as the base Nova Micro model with no additional markup making it a cost-effective solution for variable workloads.This approach is well-suited when you need to quickly customize a model for custom SQL dialects without managing ML infrastructure, want to minimal operational complexity, or need serverless inference with automatic scaling.
2a. Creating a Fine-tuning Job Using Amazon Bedrock
Amazon Bedrock supports fine-tuning using both the AWS Console and AWS SDK for Python (Boto3). The AWS documentation contains general guidance on how to submit a training job with both approaches. In our implementation, we used the AWS SDK for Python (Boto3). Refer to the sample notebook in our GitHub samples repository to view our step-by-step implementation.
Configure hyperparameters
After selecting the model to fine-tune, we then configure our hyperparameters for our use case. For Amazon Nova Micro fine-tuning on Amazon Bedrock, the following hyperparameters can be customized to optimize our text-to-SQL model:
Parameter
Range/Constraints
Purpose
What we used
Epochs
1–5
Number of complete passes through the training dataset
5 epochs
Batch Size
Fixed at 1
Number of samples processed before updating model weights
1 (fixed for Nova Micro)
Learning Rate
0.000001–0.0001
Step size for gradient descent optimization
0.00001 for stable convergence
Learning Rate Warmup Steps
0–100
Number of steps to gradually increase learning rate
10
Note: These hyperparameters were optimized for our specific dataset and use case. Optimal values may vary based on dataset size and complexity. In the sample dataset, this configuration provided improved balance between model accuracy and training time, completing in approximately 2-3 hours.
Analyzing training metrics
Amazon Bedrock automatically generates training and validation metrics, which are stored in your specified S3 output location. These metrics include:
- Training loss: Measures how well the model fits the training data
- Validation loss: Indicates generalization performance on unseen data
The training and validation loss curves show successful training: both decrease consistently, follow similar patterns, and converge to comparable final values.
3a. Deploy with on-demand inference
After your fine-tuning job completes successfully, you can deploy your custom Nova Micro model using on-demand inference. This deployment option provides automatic scaling and pay-per-token pricing, making it ideal for variable workloads without the need to provision dedicated compute resources.
Invoking the custom Nova Micro model
After deployment, you can invoke your custom text-to-SQL model by using the deployment ARN as the model ID in the Amazon Bedrock Converse API.
# Use the deployment ARN as the model ID
deployment_arn = "arn:aws:bedrock:us-east-1::deployment/"
# Prepare the inference request
response = bedrock_runtime.converse(
modelId=deployment_arn,
messages=[
{
"role": "user",
"content": [
{
"text": """Database schema:
CREATE TABLE sales (
id INT,
product_name VARCHAR(100),
category VARCHAR(50),
revenue DECIMAL(10,2),
sale_date DATE
);
Question: What are the top 5 products by revenue in the Electronics category?"""
}
]
}
],
inferenceConfig={
"maxTokens": 512,
"temperature": 0.1, # Low temperature for deterministic SQL generation
"topP": 0.9
}
)
# Extract the generated SQL query
sql_query = response['output']['message']['content']['text']
print(f"Generated SQL:
{sql_query}")Amazon SageMaker AI fine-tuning approach
While the Amazon Bedrock approach streamlines model customization through a managed training experience, organizations seeking deeper optimization control might benefit from the SageMaker AI approach. SageMaker AI provides extensive control over training parameters that can significantly impact efficiency and model performance. You can adjust batch size for speed and memory optimzation, fine-tune dropout settings across layers to prevent overfitting, and configure learning rate schedules for training stability. For LoRA fine-tuning specifically, You can use SageMaker AI to customize scaling factors and regularization parameters with different settings optimized for multimodal versus text-only datasets. Additionally, you can adjust the context window size and optimizer settings to match your specific use case requirements. See the following notebook for the complete code sample.
1b. Data preparation and upload
The data preparation and upload process for the SageMaker AI fine-tuning approach is identical to the Amazon Bedrock implementation. Both approaches convert the SQL dataset to the bedrock-conversation-2024 schema format, split the data into training and test sets, and upload the JSONL files directly to S3.
# S3 prefix for training data
training_input_path = f's3://{sess.default_bucket()}/datasets/nova-sql-context'
# Upload datasets to S3
train_s3_path = sess.upload_data(
path='data/train_dataset.jsonl',
bucket=bucket_name,
key_prefix=training_input_path
)
test_s3_path = sess.upload_data(
path='data/test_dataset.jsonl',
bucket=bucket_name,
key_prefix=training_input_path
)
print(f'Training data uploaded to: {train_s3_path}')
print(f'Test data uploaded to: {test_s3_path}')2b. Creating a fine-tuning job using Amazon SageMaker AI
Select the model ID, recipe, and image URI:
# Nova configuration
model_id = "nova-micro/prod"
recipe = "https://raw.githubusercontent.com/aws/sagemaker-hyperpod-recipes/refs/heads/main/recipes_collection/recipes/fine-tuning/nova/nova_1_0/nova_micro/SFT/nova_micro_1_0_g5_g6_48x_gpu_lora_sft.yaml"
instance_type = "ml.g5.48xlarge"
instance_count = 1
# Nova-specific image URI
image_uri = f"708977205387.dkr.ecr.{sess.boto_region_name}.amazonaws.com/nova-fine-tune-repo:SM-TJ-SFT-latest"
print(f'Model ID: {model_id}')
print(f'Recipe: {recipe}')
print(f'Instance type: {instance_type}')
print(f'Instance count: {instance_count}')
print(f'Image URI: {image_uri}')Configuring custom training recipes
A key differentiator when using Amazon SageMaker AI for Nova model fine-tuning is the ability to customize a training recipe. Recipes are pre-configured training stacks provided by AWS to help you quickly start training and fine-tuning. While maintaining compatibility with the standard hyperparameter set (epochs, batch size, learning rate, and warmup steps) of Amazon Bedrock, the recipes extend hyperparameter options through:
- Regularization parameters: hidden_dropout, attention_dropout, and ffn_dropout to prevent overfitting.
- Optimizer settings: Customizable beta coefficients and weight decay settings.
- Architecture controls: Adapter rank and scaling factors for LoRA training.
- Advanced scheduling: Custom learning rate schedules and warmup strategies.
The recommended approach is to start with the default settings to create a baseline, then optimize based on your specific needs. Here’s a list of some of the additional parameters that you can optimize for.
Parameter
Range/Constraints
Purpose
max_length
1024–8192
Control the maximum context window size for input sequences
global_batch_size
16,32,64
Number of samples processed before updating model weights
<td style="padding: 10px;border: 1px so
関連記事
AWSがS3 Filesを導入、S3バケットへのファイルシステムアクセスを実現
AWSはS3 Filesを発表し、ユーザーがAmazon S3バケットをマウントして標準ファイルシステムインターフェースでデータにアクセスできるようにした。アプリケーションは標準ファイル操作で読み書きでき、システムが自動的にS3リクエストに変換するため、コンピュートサービスがS3に保存されたデータを直接扱える。
AWSが自動インシデント調査のためのDevOpsエージェントを一般提供開始
AWSは、開発者と運用者がAWS環境での問題のトラブルシューティング、デプロイメントの分析、運用タスクの自動化を支援する生成AI搭載アシスタント「DevOps Agent」の一般提供を開始した。
Amazon Bedrockの詳細なコスト帰属機能の導入
AWSがAmazon Bedrockの推論コストをIAMプリンシパルごとに自動的に帰属する機能を発表した。これにより、コストの内訳把握、コスト最適化、財務計画が容易になる。