ロボットの終焉:英伟达のJim Fan氏がVLA時代終了を宣言し、WAM登場へ
英伟达 GEAR Lab 负责人 Jim Fan は、従来の VLA アーキテクチャの限界を指摘し、LLM の成功パターンを物理世界に適用した新パラダイム「WAM(World Action Model)」を発表して人形ロボットの未来像を提示した。
キーポイント
VLA パラダイムの終焉と WAM の登場
Jim Fan は、言語モデルに依存しすぎる現在の VLA(Vision-Language-Action)アーキテクチャが物理動作の学習において限界に達していると宣言し、代わりに「世界動作モデル(WAM)」を新標準として提唱した。
LLM 訓練パスの物理世界への転用
大規模言語モデルが辿った「事前学習→微調整→強化学習」の 3 ステップを、言語モデルの代わりに「動画世界モデル」を用いて物理世界のシミュレーションに適用する「底層同構(Great Parallel)」戦略を採用する。
遥操作データの不要化と第一人称データ
従来の人手による遥操作データ収集の非効率性を克服するため、21,000 時間分の人間第一人称動画を用いた「EgoScale」事前学習により、物理動作の神経スケーリング法則(R² = 0.998)を確立した。
物理エンジン不要なニューラルシミュレータ
Dream Dojo において、44,000 時間の人間動画から学習させた完全な「神経シミュレータ」を開発し、従来の物理計算エンジンを経由せずにロボットの動作を高精度に予測・実行可能にした。
影響分析・編集コメントを表示
影響分析
この発表は、人形ロボット開発の主流アーキテクチャが言語モデル依存から物理世界理解中心へと転換する歴史的転換点を示しており、業界全体が遥操作データ収集から大規模動画学習へのリソースシフトを迫られる可能性が高い。特に「神経シミュレータ」の実用化は、ロボットの安全な自律学習と汎用化の障壁を大幅に下げる画期的な技術であり、2040 年までの完全自律社会実現に向けた具体的なロードマップを提供している。
編集コメント
Jim Fan の「打たれぬなら加わる」という姿勢は、LLM の成功をロボット分野に単純適用するだけでなく、物理世界の複雑さをどうモデル化するかに焦点を当てた深い洞察を示しています。これは単なる技術のアップデートではなく、ロボティクス研究の根本的なパラダイムシフトを告げる重要な宣言です。
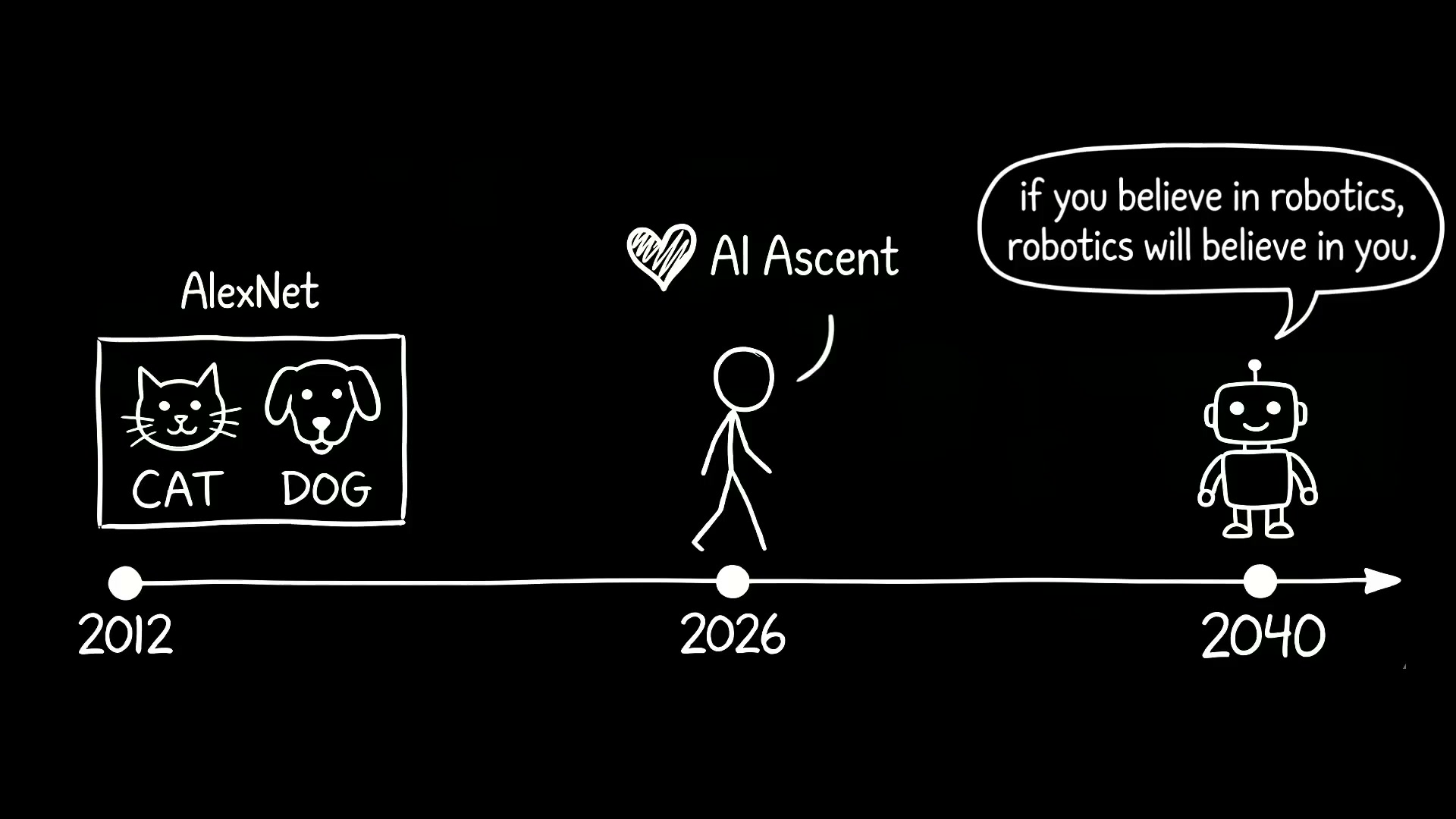
Jim Fan は英伟达のロボットおよび AI 研究グループ(GEAR Lab)の責任者であり、過去数年間は GR00T 人形ロボットの基礎モデルとして VLA(Vision-Language-Action:視覚・言語・動作)アーキテクチャを推進してきました。彼は直近の Sequoia AI Ascent 2026 で 20 分間の講演を行い、そのテーマは『Robotics' End Game』でした。そして最初の行動として、彼自身が半年前まで推進していた GR00T を含む VLA ルートが時代遅れになったと宣言しました。
これに代わる新しいパラダイムは世界動作モデル(World Action Model:WAM)と呼ばれ、その代表作は英伟达 が 2 月に発表した DreamZero です。彼はこのアプローチを「基盤の同型性」と呼びました。これは LLM(Large Language Model:大規模言語モデル)が歩んできた 3 つのステップ(事前学習→アライメント→強化学習)を模倣し、言語モデルに代わってビデオ世界モデルを使用し、遠隔操作データに代わって人間の第一人称視覚データを採用することで、最終的には 2040 年までにロボット自身が次世代の自分自身を設計・製造できるようにするというものです。彼はこの見通しに対して 95% の確信を持っています。
講演元:Sequoia Capital AI Ascent 2026、2026 年 4 月 30 日公開。原動画:https://www.youtube.com/watch?v=3Y8aq_ofEVs
ポイントサマリー
- VLA ルートの幕引き:Jim は公然と VLA ルートが時代遅れになったと宣言し、新パラダイムを世界動作モデル(WAM)と呼びました。代表作は DreamZero(140 億パラメータ)です。
- 遠隔操作データとの訣別:遠隔操作には物理的な上限があり、予測では今後 1〜2 年でほぼゼロに低下し、センサ化された人間データに置き換わるとされています。
- ニューラルスケーリング法則:EgoScale は 21,000 時間の人間の第一人称視覚データで事前学習を行い、チームは器用な操作におけるニューラルスケーリング法則(R² = 0.998)を発見しました。
- ニューラルシミュレータ:Dream Dojo は 44,000 時間の人間動画を用いて訓練され、物理エンジンを経由しない完全なニューラルシミュレータを構築しています。
- 終局へのカウントダウン:2040 年におけるロボット終局(物理的自動研究)の達成を予測し、その信頼度は 95% です。
DGX-1 の署名から「基盤の同型性」へ
Jim はある過去の出来事をもって講演を締めくくりました。2016 年の夏、当時の OpenAI のオフィスで、黄仁勲は特徴的な革ジャンを着て、大きな金属製のトレイを抱えて入ってきました。そこにはこう書かれていました。「Elon と OpenAI チームへ、計算と人類の未来へ」。それは世界初の DGX-1 でした。

当時、Jim は OpenAI の最初のインターン生であり、すぐに列に並んでその上に署名しました。「当時は自分が何に署名しているのか全く知りませんでした」。隣で一緒に署名していたのは Andrej Karpathy です。この機械は現在、Computer History Museum で収蔵されています。Jim は付け加えて、「自分も恐竜のように老いたと感じます」と語りました。

**
*注:Jim Fan(范麟熙)は英伟达のロボットおよび AI 担当ディレクター、フェローであり、GEAR Lab と GR00T 人形ロボットプロジェクトを率いています。2016 年に OpenAI でインターン生だった際のメンターは Ilya Sutskever と Andrej Karpathy で、その後 Stanford で Fei-Fei Li の元で博士号を取得しました。**
この物語は、彼の核心となるフレームワークを紹介するためにあります。彼はイリヤの「あなたが深層学習を信じれば、深層学習もあなたを信じる」という言葉を引用し、LLM はたった 3 回の段階的飛躍と 6 年の時間で今日に至ったと述べました:GPT-3 の事前トレーニング、InstructGPT における監督微調整、o1 スタイルの強化学習、そして自動研究へと至る道です。
そこで彼は一つの決断を下しました。他者の成果を踏襲し、名前を変えて「底層同構(the Great Parallel)」と呼ぶことにしたのです。「文字列の次の状態をシミュレートする」ことを「物理世界の次の状態をシミュレートする」ことに変え、動作微調整によってロボットに必要な部分に収束させ、最後に強化学習が最後の 1 キロメートルを完走させるというアプローチです。

**
勝てないなら仲間になる。
("If you can't beat them, join them.")
VLA はどうなった:パラメータが言語に偏っている
過去 3 年間、ロボット分野の主流アーキテクチャは VLA**(Vision-Language-Action、視覚 - 言語 - 動作モデル)でした。英伟达(NVIDIA)自社の GR00T や Physical Intelligence の π0 もこのカテゴリに属します。
Jim は構造的な問題を指摘しました。実はこれらのモデルは LVA と呼ぶべきであり、その理由はパラメータの大部分が言語に集中しているからです。言語が一等公民であり、視覚が次点、動作は最下位となっています。
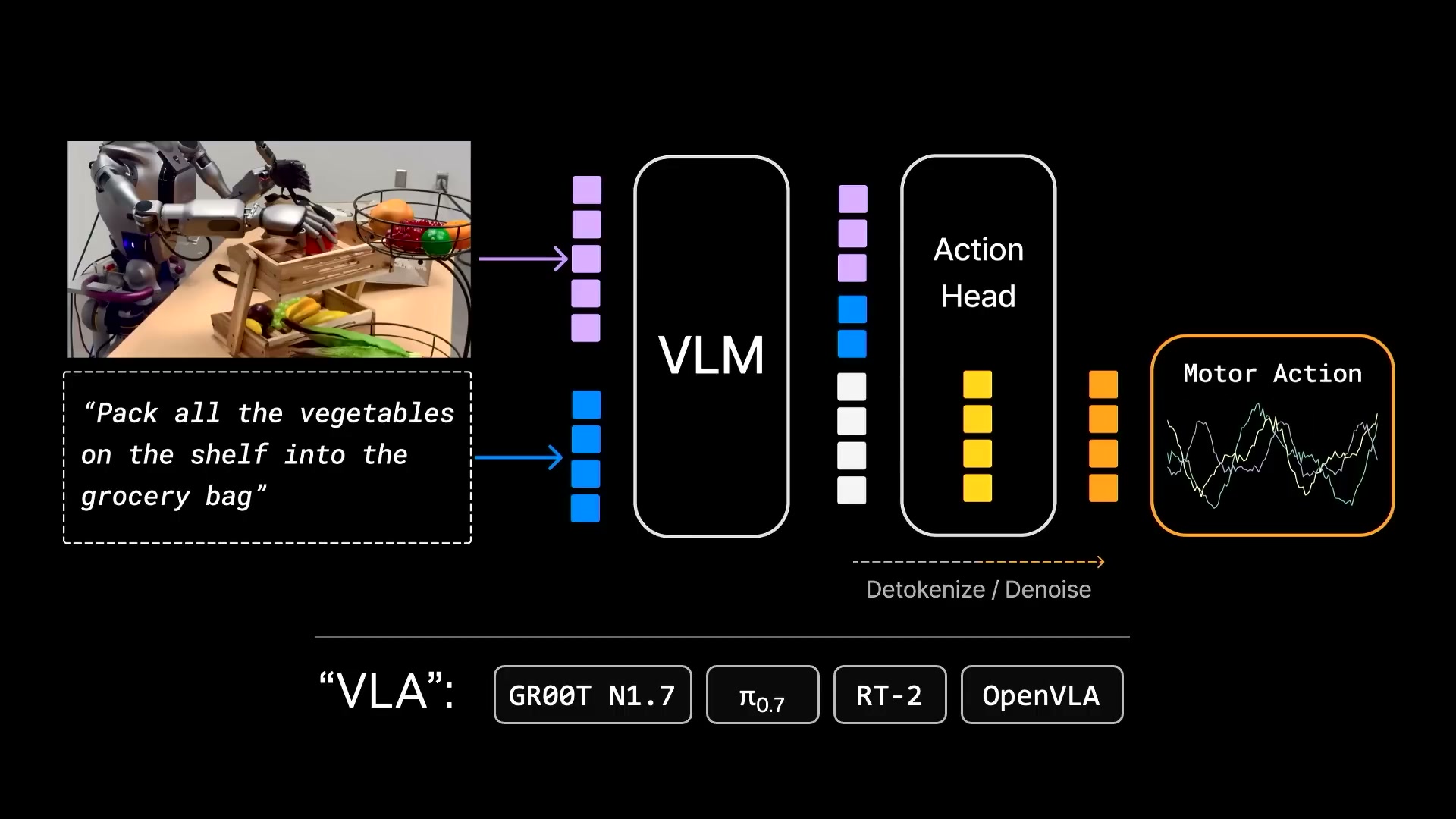
**
VLA は知識や名詞のエンコーディングには優れていますが、物理法則や動詞の扱いが苦手です。重心が誤った場所にあります。
彼は RT-2 の元論文にある古典的なデモを例に挙げました:ロボットにコカ・コーラの缶をテイラー・スウィフトの写真の隣に押すように指示するものです。モデルはテイラー・スウィフトを見たことがありませんが、それを一般化して対応できます。問題は、一般化されるのが名詞(テイラー・スウィフトを認識できる)だけであり、動詞(どのように押すか、どの角度を探すか、どれだけの力を使うべきか)ではない点です。

AI のゴミ動画から DreamZero へ
VLA が答えではないなら、次の事前トレーニングのパラダイムは何でしょうか?その結果、それは動画モデルであることが分かりました。これらのモデルは内部で物理世界の次の状態をシミュレートすることを学んでいます。

これらの世界モデルを実用的なものにするには、動作微調整を行う必要があります。「ありとあらゆる未来」の重ね合わせ状態を、実際のロボットにとって意味のある動作軌跡へと収束させるのです。
英伟达(NVIDIA)の答えは DreamZero**です。これは実行前に数秒間未来へ「夢見る」ことで、その後に行動する新しい戦略モデルです。DreamZero は次のフレーム画像と次の動作を同時にデコードします。ここで初めて視覚と動作が真に「一等公民」となったのです。

Jim は率直に、DreamZero が現在、すべてのタスクで 100% の信頼性を達成できていないことを認めています。「それは GPT-2 の段階に相当するもので、方向性は正しいのですが、まだパフォーマンスが十分に安定しておらず、信頼性に欠けます」と。彼は新しいアーキテクチャにWAM(World Action Models:世界動作モデル)という名前をつけました。
**
私たちの親愛なる VLA のために、一瞬の黙祷を捧げましょう。その歴史的な使命は完了しました。安らかに眠れ。万歳、世界動作模型よ。
*注:DreamZero の論文(arXiv 2602.15922)は 2026 年 2 月に発表され、パラメータ数は 140 億個です。Wan2.1 動画拡散モデルをベースにしています。重要な制限事項として、この 14B モデルでは、ループ制御を 7Hz に抑えるためにシステムレベルの最適化を 38 倍実施し、GB200 ハードウェアが必要となります。そのため、導入のハードルは極めて高いです。
*
データ革命:テレオペレーションから「ロボットが参加しないデータ収集」へ
過去三年間は、テレオペレーション(teleop:遠隔操作)の黄金時代でした。しかし、テレオペレーションには明確な上限があります。それは、一台のロボットが一日に 24 時間稼働できるという事実です。
「私が一日 24 時間と言ったのは、自分自身を欺くためです。実際には、一日で 3 時間もこなせれば上出来でしょう。さらに、その日の『ロボットの神様』が機嫌よく許可してくれるかどうかにもよります——なぜなら、これらの機械は毎日不機嫌になったり故障したりするからです」

この状況を打破するには、ロボットの末端実行器(エンドエフェクタ)を直接人間の手に装着し、データを収集することで、ロボット本体そのものを完全に迂回させることです。
英伟达の解決策は DexUMI**です。これは外骨格装置で、これを用いて収集したデータから学習させたロボット戦略は、テレオペレーションデータを一切含まない状態で完全自律的に動作できます。

**
ロボットたちは喜んでいます。なぜなら、ついにデータ収集に参加する必要がなくなったからです。
EgoScale:21,000 時間分の人間動画とスケーリング則
英伟达は EgoScale**をリリースしました。ここでの訓練データの 99.9% は、人間の第一人称視点動画(egocentric video)から得られています。
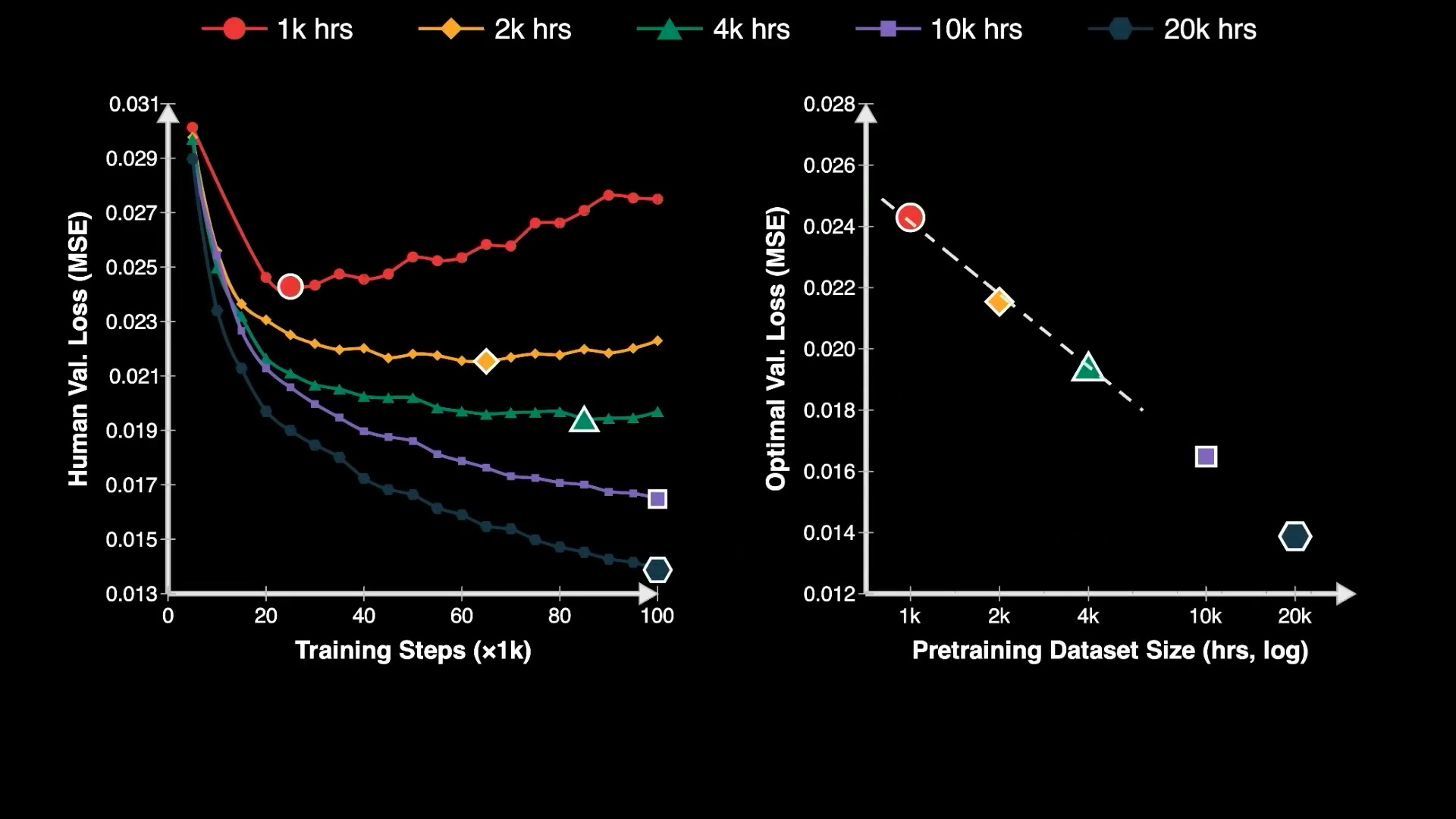
事前学習には、ロボットデータを一切含まない 21,000 時間の野外人間データが使用されました。動作微調整フェーズでは、高精度なモーションキャプチャーグローブのデータ 50 時間と、テレオペレーションデータ 4 時間のみを使用しました——これらを合計しても訓練総量の 0.1% に満たないほどです。

最も重要な発見は「器用操作におけるニューラルスケーリング則」です。事前学習に投入された計算時間(GPU 時間)と、最適な検証損失の間には、極めて明確な対数線形関係が存在し、決定係数 R² は驚異的な 0.998 に達しました。
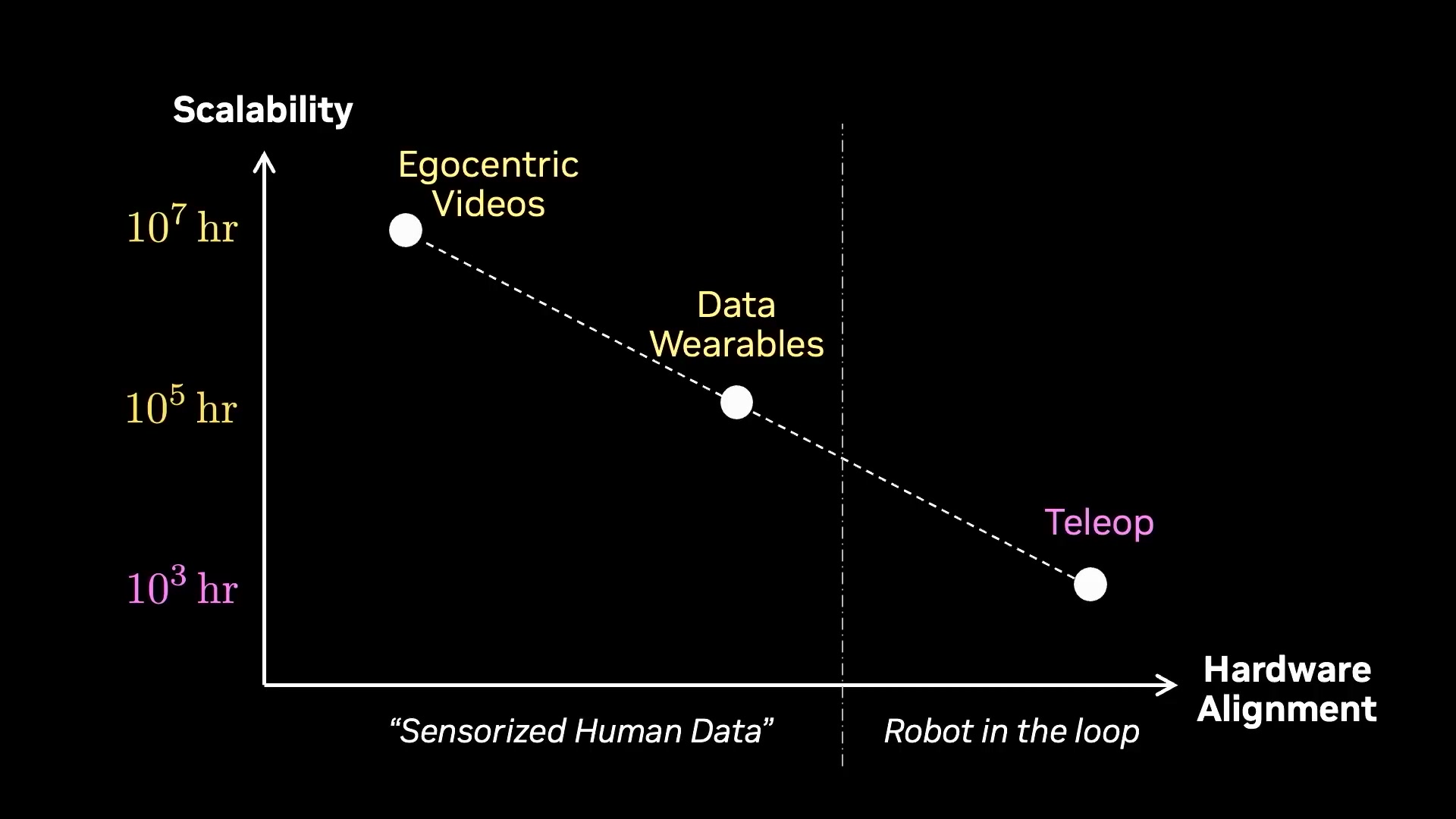
Jim は、すべてのデータ戦略の拡張性を比較しました。テレオペレーションは最も拡張性の低い領域に位置し、第一人称動画であれば、FSD(Full Self-Driving:完全自動運転)式のようなデータファインウェールを回転させることで、1 年以内に 1,000 万時間に到達できると述べています。
Dream Dojo:物理エンジンを使わない神経シミュレータ
ロボット分野でも、強化学習(RL)のために数百万のプログラミング環境を構築するために巨額の資金が必要ですが、実機での学習(real-to-sim-to-real)だけでは不十分です。
次のステップとなるのが Dream Dojo です。物理エンジンに頼るのではなく、動画世界モデルそのものを完全な神経シミュレータへと変換します。入力は連続的な動作信号で、リアルタイムに次フレームの RGB 画像とセンサー状態を出力します。物理方程式もグラフィックエンジンもなく、完全にデータ駆動型です。

**
あなたが目にする画面のピクセルの一つも、現実のものではありません。
「現在、計算資源が環境であり、データです。あるいはある賢者の言葉に借りれば、『多くを買うほど、より多くを節約できる』。このメッセージは私の上司によって承認されました。」
終焉へのロードマップ:2040 年までの三つの達成目標
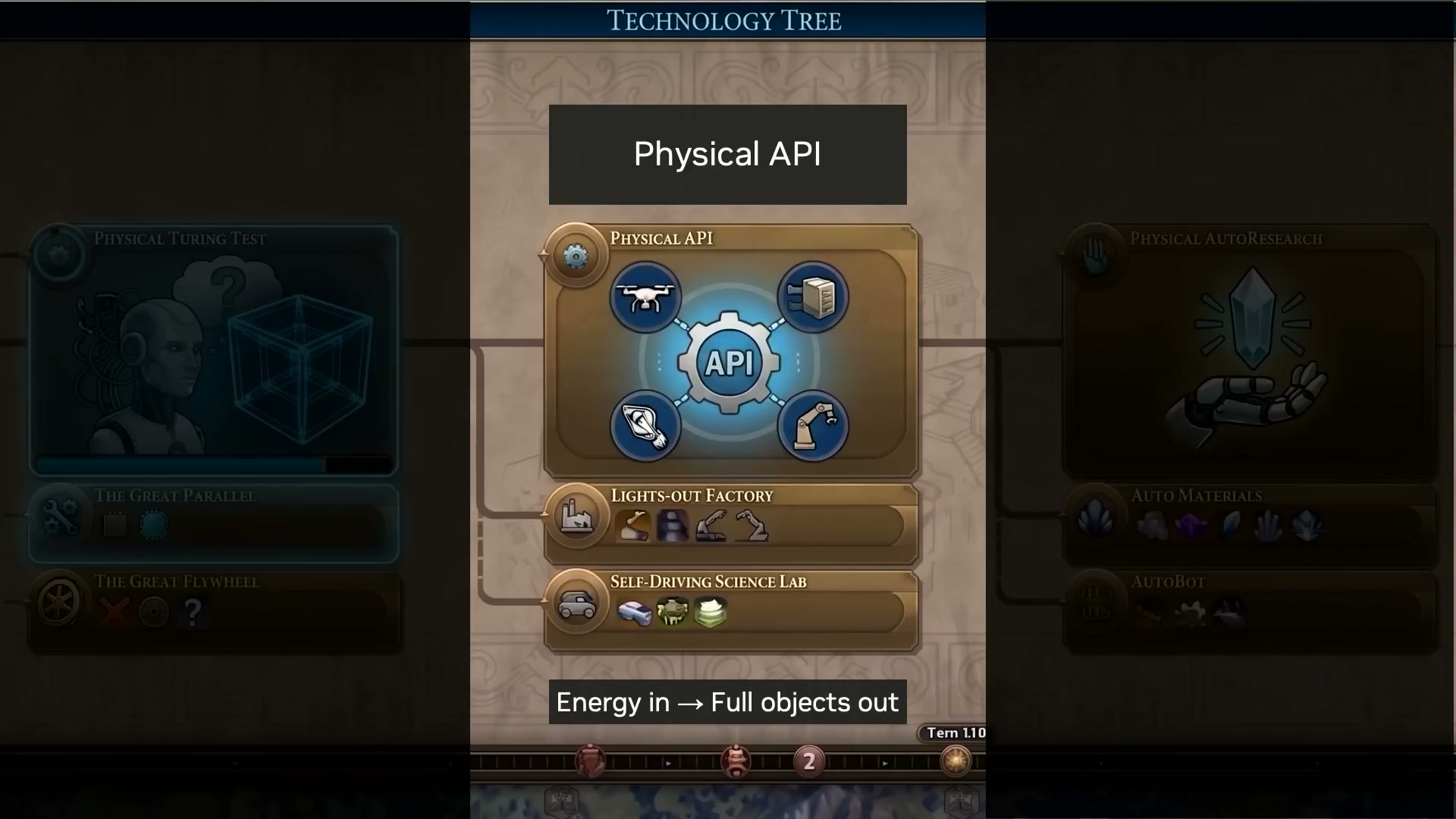
Jim はロボットの残された道程を、解くべき三つの技術ツリー(テクノロジーツリー)の達成目標に例えました。
- 物理的チューリングテスト:今後 2〜3 年で、タスクを実行しているのが人間かロボットかを区別できなくなるでしょう。
- 物理 API:ソフトウェアと大規模言語モデルを用いてロボットの構成をオーケストレーションし、「暗黙の工場(ダークファクトリー)」や自動化された科学研究所を構築します。
- 物理的自動研究:ロボットが自ら設計・改良し、次世代のロボットを製造するようになります。
タイムラインについては、AI が AlexNet(2012 年)からエージェント(2026 年)へと進化するために 14 年を要したことに例えています。さらに 14 年加算すれば、ちょうど 2040 年となります。
私たちの世代は、地球を探索する大航海時代には生きたる遅すぎたし、宇宙を探索するために星々へ到達するには生きたる早すぎました。しかし、私たちはちょうどロボットという難問に挑む時代に生まれました。
5 つの質問への即答
Q:VLA(Vision-Language-Action)モデルは本当に死んだのか?**
A:講演の文脈では死にました。しかし、英伟达(NVIDIA)自社が 2026 年 4 月に発表した最新の GR00T N1.7 の論文には依然として「VLA モデル」と明記されています。パラダイムシフトは社内でも完了していません。
Q:DreamZero は現在、生産環境で利用可能ですか?
A:いいえ。Jim 自身もこれを「おそらく GPT-2 の段階だ」と述べています。論文によると、14B パラメータのモデルでループ制御を実行しても 7Hz に過ぎず、かつ GB200 を必須としています。
Q:遠隔操作(テレオペレーション)は本当に不要になるのでしょうか?
A:Jim は今後 1〜2 年でほぼゼロになると予測しています。しかし、デバイスをつけて家事を行うことは運転のような必須要件ではなく、業界に既に大量に存在する遠隔操作インフラが一夜にして廃棄されるわけではありません。
Q:器用な操作のスケール則(スケーリング法則)は何を意味するのか?
A:もし R² = 0.998 という関係性が持続的に成立するなら、人間の動画データを追加することでロボットの器用さが予測可能に向上することを意味します。これは今回の講演における最も核心的な実証的根拠です。
Q:英伟达(NVIDIA)はこの棋譜で何を得るのか?
A:WAM(Whole-body Action Model)と神経シミュレータは計算資源を極めて多く必要とします。Jim の「多くを買うほど、より多くを節約できる」という言葉は、パラダイムシフトが本質的にチップの販売に有利に働くという商業意図を直接反映しています。
結び:注目すべき三つの懸案事項
追跡する価値がある三つの事柄は以下の通りです。
- DreamZero が「GPT-2 の段階」をどう乗り越えるか:今後 12〜18 ヶ月で極限パラメータを安定化できるかが、このパラダイムの真の威力を決めます。
- NVIDIA 内部における VLA パラダイムからの転換のタイミング:製品更新におけるアーキテクチャの実質的な進化を観察する。次世代もなお VLA であれば、本講演はより概念的なマーケティングに傾くだろう。
- 第一人称ビデオデータのフライングホイールの担い手:NVIDIA 自身にはコンシューマー向けハードウェアの入口がないため、誰(例えば Apple や Meta など)が実際にこの千万時間規模のデータを回転させることができるかを注視する必要がある。
原文を表示
Jim Fan 是英伟达机器人与 AI 研究组(GEAR Lab)负责人,过去几年主推的 GR00T 人形机器人基础模型用的是 VLA(Vision-Language-Action,视觉 - 语言 - 动作)架构。他刚在 Sequoia AI Ascent 2026 上做了一场 20 分钟的演讲,主题叫《Robotics' End Game》,第一件事就是宣布 VLA 路线过时——包括他自己半年前还在推的 GR00T。
取而代之的新范式叫世界动作模型(WAM),代表作是英伟达 2 月发布的 DreamZero。他把这套思路叫“底层同构”:复制 LLM(Large Language Model,大语言模型)走过的三步(预训练→对齐→强化学习),用视频世界模型替代语言模型,用人类第一人称视频替代遥操作数据,最终在 2040 年前让机器人自己设计和制造下一代自己。他对此有 95% 的把握。
演讲来源:Sequoia Capital AI Ascent 2026,2026 年 4 月 30 日发布。原视频:https://www.youtube.com/watch?v=3Y8aq_ofEVs
要点速览
- VLA 路线落幕:Jim 公开宣告 VLA 路线过时,新范式叫世界动作模型(WAM),代表作是 DreamZero(140 亿参数)。
- 告别遥操作数据:遥操作物理上限低,预测一两年内降到接近 0,被传感化人类数据取代。
- 神经缩放定律:EgoScale 用 21,000 小时人类第一人称视频预训练,团队发现了灵巧操作的神经缩放定律(R² = 0.998)。
- 神经仿真器:Dream Dojo 用 44,000 小时人类视频训练出一个完全绕过物理引擎的神经仿真器。
- 终局倒计时:给出 2040 年完成机器人终局的预测(物理自动研究),置信度 95%。
从 DGX-1 签名到“底层同构”
Jim 用一段往事开场。2016 年夏天,就在 OpenAI 当时的办公室,黄仁勋穿着标志性皮夹克,抱着一块大金属托盘走进来,上面写着:“致 Elon 和 OpenAI 团队,致计算和人类的未来。”那是全球第一台 DGX-1。
Jim 当时是 OpenAI 的第一个实习生,赶紧排队去上面签了名。“那时候我完全不知道自己在签什么。”旁边一起签的还有 Andrej Karpathy。这台机器现在在 Computer History Museum 收藏。Jim 补了一句,说自己感觉像恐龙一样老了。
注:Jim Fan(范麟熙)是英伟达机器人与 AI 总监、杰出科学家,领导 GEAR Lab 和 GR00T 人形机器人项目。2016 年在 OpenAI 实习时的导师是 Ilya Sutskever 和 Andrej Karpathy,后在 Stanford 跟随 Fei-Fei Li 读完博士。
这个故事是为了引出他的核心框架。他引了 Ilya 那句“你信深度学习,深度学习就信你”,然后说 LLM 只用三次阶跃、六年时间就走到今天:GPT-3 的预训练,InstructGPT 的监督微调,o1 风格的强化学习,再到自动研究。
于是他做出了一个决定:抄作业,换个名字,叫“底层同构”(the Great Parallel)。把“模拟字符串的下一个状态”换成“模拟物理世界的下一个状态”,通过动作微调收敛到机器人需要的那部分,最后让强化学习走完最后一公里。
打不过就加入。
(“If you can't beat them, join them.”)
VLA 怎么了:参数都堆在了语言上
过去三年,机器人领域的主流架构是 VLA(Vision-Language-Action,视觉 - 语言 - 动作模型)。英伟达自家的 GR00T 和 Physical Intelligence 的 π0 都属于这个类别。
Jim 指出了结构性问题:其实这些模型该叫 LVA,因为参数大头全堆在语言上了。语言是一等公民,视觉次之,动作只能垫底。
VLA 擅长编码知识和名词,不擅长物理和动词。重心放在了不对的地方。
他举了 RT-2 原始论文里那个经典 demo:让机器人把可乐罐推到 Taylor Swift 的照片旁边。模型没见过 Taylor Swift,但能泛化过去。问题是,泛化的是名词(能认出 Taylor Swift),而不是动词(该怎么推、找什么角度、用多大力)。
从 AI 垃圾视频到 DreamZero
VLA 不是答案,那下一个预训练范式是什么?结果发现是视频模型,它们在内部学会了模拟物理世界的下一个状态。
怎么把这些世界模型变有用?做动作微调。把“所有可能的未来”这种叠加态,收敛到一条对真实机器人有意义的动作轨迹上。
英伟达的答案叫 DreamZero。这是一种新型策略模型,在执行动作之前先往未来“做梦”几秒钟,然后根据梦境行动。DreamZero 同时解码下一帧画面和下一步动作。在这里,视觉和动作第一次真正成为了“一等公民”。
Jim 坦率地承认 DreamZero 目前做不到每个任务都 100% 可靠。“它大概相当于 GPT-2 的阶段,方向对了,但表现还不够稳定可靠。”他给这个新架构起名叫 WAM(World Action Models,世界动作模型)。
为我们亲爱的 VLA 默哀片刻。它已完成了历史使命。安息吧。世界动作模型万岁。
注:DreamZero 论文(arXiv 2602.15922)2026 年 2 月发布,140 亿参数,基于 Wan2.1 视频扩散模型。它有一个关键限制:14B 模型必须经过 38 倍系统级优化加 GB200 硬件,才能把闭环控制压到 7Hz,部署门槛极高。
数据革命:从遥操作到“机器人不用参与的数据采集”
过去三年是遥操作(teleop)的黄金时代。但遥操作有一个硬上限:每台机器人每天 24 小时。
“我说一天 24 小时,那是骗自己的。实际一天能干 3 小时就不错了,还得看当天的‘机器人之神’赏不赏脸——毕竟这帮机器天天闹脾气出毛病。”
怎么破局?把机器人的末端执行器直接戴在人手上,直接采集数据,完全绕过机器人本体。
英伟达方案是 DexUMI,一种外骨骼装置。用外骨骼数据训练出的机器人策略可以完全自主运行,训练数据里没有任何遥操作数据。
机器人很开心,因为它们终于不用参与数据采集了。
EgoScale:21,000 小时人类视频和缩放定律
英伟达推出了 EgoScale:99.9% 的训练数据来自人类第一人称视频(egocentric video)。
预训练用了 21,000 小时的野外人类数据,零机器人数据。动作微调阶段仅仅用了 50 小时的高精度动捕手套数据,外加 4 小时遥操作数据——加起来连训练总量的 0.1% 都不到。
最重要的发现是:灵巧操作的神经缩放定律。预训练投入的算力小时数与最优验证损失之间,存在一条极其清晰的对数线性关系,R² 达到了惊人的 0.998。
Jim 把所有数据策略的扩展性放在了一起:遥操作在最不可扩展的角落;第一人称视频如果能转动 FSD(Full Self-Driving,完全自动驾驶)式的数据飞轮,一年内能到 1000 万小时。
Dream Dojo:不用物理引擎的神经仿真器
机器人领域也需要花大钱买几百万个编程环境做强化学习(RL),但直接用真机(real-to-sim-to-real)不够。
进一步的方案是 Dream Dojo:不搞物理引擎那一套,直接把视频世界模型变成一个完整的神经仿真器。输入是连续动作信号,实时输出下一帧 RGB 画面和传感器状态。没有物理方程,没有图形引擎,完完全全是数据驱动的。
你看到的画面里没有一个像素是真实的。
“现在算力等于环境等于数据。或者用某位智者的话:买得越多,省得越多。这条消息已获得我老板批准。”
终局路线图:2040 年前的三个成就
Jim 把机器人的剩余路径类比成了必须解锁的三个科技树成就:
- 物理图灵测试:2-3 年内,你分不出执行任务的是人还是机器人。
- 物理 API:用软件和大模型编排机器人配置,建造“暗工厂”和自动化科学实验室。
- 物理自动研究:机器人开始自己设计、改进并制造出下一代机器人。
至于时间表,他类比 AI 从 AlexNet(2012)到智能体(2026)用了 14 年。再加 14 年,正好是 2040 年。
我们这一代人,生得太晚,没赶上大航海时代去探索地球;又生得太早,够不着星辰大海去探索宇宙。但我们生得刚刚好,赶上了攻克机器人难题的时代。
五个问题速答
Q:VLA 真的死了吗?
A:演讲层面是死了。但英伟达自家最新的 GR00T N1.7(2026 年 4 月)论文里还明确写“VLA 模型”。范式迁移在内部尚未完成。
Q:DreamZero 现在能用在生产环境吗?
A:不能。Jim 自己说它“大概是 GPT-2 阶段”。论文披露 14B 模型跑闭环控制只有 7Hz,且必须用 GB200。
Q:遥操作真的会被淘汰吗?
A:Jim 预测一两年内降到接近 0。但戴设备做家务不像开车是刚需,且行业大量已有的遥操作基础设施不会一夜间报废。
Q:灵巧操作的缩放定律意味着什么?
A:如果 R² = 0.998 持续成立,意味着增加人类视频数据,机器人灵巧性就会可预测地提升。这是整场演讲中最核心的实证论据。
Q:英伟达在这盘棋里赚什么?
A:WAM 和神经仿真器对算力需求极高。Jim 的那句“buy more, save more”直接反映了范式切换天然有助于卖芯片的商业意图。
最后:值得追踪的三个悬念
三件事最值得追踪:
- DreamZero 如何跨越“GPT-2 阶段”:未来 12-18 个月能不能把极限参数做稳,决定了这套范式的真实威力。
- 英伟达内部对 VLA 范式的切换时刻:观察其产品更新中架构实质演进。如果下一代还是 VLA,则演讲更偏向概念营销。
- 第一人称视频数据的飞轮载体:英伟达自身没有消费级硬件入口,需观望谁(如苹果、Meta)能真正转动这块千万小时量级的数据。
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み