Strands Evalsで現実的なユーザーをシミュレートして多段階AIエージェントを評価
AWS Machine Learning Blogは、Strands Evaluation SDKのActorSimulatorが、現実的なユーザーをシミュレートしてマルチターンAIエージェントを評価する手法を紹介し、本番環境での会話評価の課題を解決する方法を提案している。
キーポイント
マルチターン評価の必要性
本番環境での会話は単一ターンでは完結せず、ユーザーのフォローアップ質問や方向転換など動的なパターンに対応する評価が求められる。
従来手法の限界
手動での多数の会話評価はスケールせず、スクリプト化された会話フローは予測可能なパスに限定され、実際のユーザー行動を捉えられない。
ActorSimulatorによる解決策
Strands Evaluation SDKのActorSimulatorは、現実的で目標駆動型のユーザーをプログラム的に生成し、エージェントと自然な会話を複数ターンにわたって行わせる。
評価パイプラインへの統合
構造化されたユーザーシミュレーションを評価パイプラインに統合することで、包括的な評価スイートの構築が可能になる。
評価パイプラインとの統合
本番環境での評価には、ActorSimulatorをOpenTelemetryによるテレメトリ収集やStrands Evalsセッションマッピングと組み合わせ、会話のトレースを構造化されたセッションとして評価パイプラインに渡すことが必要である。
会話ループの終了条件
シミュレートされたユーザーの目標が達成された場合、エージェントがリクエストを完了できないと判断された場合、または最大ターン数に達した場合に、会話ループは終了する。
カスタムアクタープロファイルによる対象テスト
特定のテスト目標には、自動生成されたプロファイルではなく、完全に定義されたアクタープロファイルを使用できる。これにより、焦りやすい専門家ユーザーや忍耐強い初心者など、特定のペルソナに対するエージェントの応答を検証できる。
影響分析・編集コメントを表示
影響分析
この記事は、AIエージェントの評価における重要な課題であるマルチターン会話評価を、現実的なユーザーシミュレーションを通じて解決する手法を提示しており、本番環境でのAIエージェントの信頼性向上に貢献する可能性がある。特に、AWSのプラットフォームを通じて広く利用可能になることで、業界標準の評価手法として普及する可能性を示唆している。
編集コメント
AIエージェントの実用化が進む中、評価手法の進化は品質保証の鍵となる。本記事は理論ではなく実践的なソリューションを提供しており、開発現場での即時適用が期待できる内容だ。
単一ターンのエージェント対話の評価は、ほとんどのチームがよく理解しているパターンに従います。入力(input)を提供し、出力(output)を収集し、結果を判断します。Strands Evaluation SDKのようなフレームワークは、有用性(helpfulness)、忠実性(faithfulness)、ツール使用(tool usage)を評価する評価者(evaluators)を通じて、このプロセスを体系化します。以前のブログ記事では、これらの機能を使用してAIエージェントの包括的な評価スイート(evaluation suites)を構築する方法について説明しました。しかし、本番環境での会話は1ターンで終わることはほとんどありません。
実際のユーザーは、複数のターンにわたって展開する対話を行います。回答が不完全な場合はフォローアップの質問をし、新しい情報が現れた場合は方向を変え、ニーズが満たされない場合は不満を表現します。「パリ行きのフライトを予約して」という単独のリクエストをうまく処理する旅行アシスタントでも、同じユーザーが「実は、代わりに電車を調べてもらえますか?」や「エッフェル塔近くのホテルはどうですか?」とフォローアップした場合に苦戦する可能性があります。これらの動的なパターンをテストするには、固定された入力と期待される出力を持つ静的なテストケース(test cases)だけでは不十分です。
中核的な難しさは規模(scale)です。エージェントが変更されるたびに数百ものマルチターン会話を手動で実施することはできず、スクリプト化された会話フロー(conversation flows)を書くことは、実際のユーザーの行動を見逃すような事前に決められたパスに縛られることになります。評価チームが必要としているのは、現実的で目標駆動型(goal-driven)のユーザーをプログラムで生成し、彼らがエージェントと複数のターンにわたって自然に対話できるようにする方法です。この記事では、Strands Evaluations SDKのActorSimulatorが、評価パイプライン(evaluation pipeline)に統合される構造化されたユーザーシミュレーション(user simulation)を通じてこの課題にどのように取り組むかを探ります。
なぜマルチターン評価は根本的に難しいのか
単一ターン評価は直截的な構造を持っています。入力は事前に分かっており、出力は自己完結的で、評価コンテキスト(evaluation context)はその単一のやり取りに限定されます。マルチターン会話は、これらの前提のすべてを崩します。
マルチターン対話では、各メッセージはそれ以前のすべてに依存します。ユーザーの2つ目の質問は、エージェントが最初の質問にどう答えたかによって形作られます。部分的な回答は、残された部分についてのフォローアップを引き出し、誤解はユーザーに元のリクエストを言い直させ、驚くような提案は会話を新しい方向に進めることができます。
これらの適応的行動(adaptive behaviors)は、テスト設計時には予測できない会話パス(conversation paths)を生み出します。入出力ペア(I/O pairs)の静的なデータセット(dataset)は、どれだけ大きくても、この動的な性質を捉えることはできません。なぜなら、「正しい」次のユーザーメッセージは、エージェントが今言ったことに依存するからです。
手動テスト(Manual testing)は理論的にはこのギャップをカバーしますが、実際には失敗します。テスターは現実的なマルチターン会話を実施できますが、すべてのシナリオ、すべてのペルソナタイプ(persona type)、エージェントの変更のたびにそれを行うことは持続可能ではありません。エージェントの能力が成長するにつれて、会話パスの数は組み合わせ的に増加し、チームが手動で探索できる範囲をはるかに超えます。
一部のチームはショートカットとしてプロンプトエンジニアリング(prompt engineering)に頼り、テスト中に大規模言語モデル(LLM)に「ユーザーのように振る舞う」よう求めます。構造化されたペルソナ定義(persona definitions)と明示的な目標追跡(goal tracking)なしでは、これらのアプローチは一貫性のない結果を生み出します。シミュレートされたユーザーの行動は実行間で漂移し、時間を追った評価の比較や、真の後退(regressions)とランダムな変動の識別を困難にします。構造化されたユーザーシミュレーションへのアプローチは、人間の会話の現実性と自動テストの再現性と規模を組み合わせることで、このギャップを埋めることができます。
良いシミュレートされたユーザーとは何か
シミュレーションベースのテスト(Simulation-based testing)は、他の工学分野では確立されています。フライトシミュレーター(Flight simulators)は、現実世界では危険または再現不可能なシナリオに対するパイロットの反応をテストします。ゲームエンジン(Game engines)は、リリース前にAI駆動のエージェントを使用して数百万のプレイヤー行動パスを探索します。同じ原理が会話型AI(conversational AI)にも適用されます。定義した条件下で現実的なアクター(actors)がシステムと対話する制御された環境を作り、結果を測定します。
AIエージェント評価において、有用なシミュレートされたユーザーは、一貫したペルソナから始まります。あるターンでは技術的専門家のように振る舞い、次のターンでは混乱した初心者のように振る舞うユーザーは、信頼性の低い評価データを生み出します。一貫性とは、実際の人物と同じように、すべてのやり取りを通じて同じコミュニケーションスタイル、専門知識レベル、性格特性を維持することを意味します。
同様に重要なのは、目標駆動型の行動です。実際のユーザーは、達成したい何かを持ってエージェントにやってきます。彼らはそれを達成するまで粘り強く取り組み、うまくいかないときはアプローチを調整し、目標が達成されたときにはそれを認識します。明示的な目標なしでは、シミュレートされたユーザーは会話を早々に終わらせすぎるか、または無限に質問を続ける傾向があり、どちらも実際の使用状況を反映していません。
シミュレートされたユーザーはまた、事前に決められたスクリプトに従うのではなく、エージェントが言ったことに適応的に応答しなければなりません。エージェントが明確化の質問をしたとき、アクターはそのキャラクターに沿ってそれに答えるべきです。応答が不完全な場合、アクターは次に進むのではなく、残された部分についてフォローアップします。会話が話題から外れた場合、アクターはそれを元の目標に向かって戻します。これらの適応的行動は、シミュレートされた会話を評価データとして価値あるものにします。なぜなら、それらはエージェントが本番環境で直面するのと同じ会話ダイナミクス(conversation dynamics)を行使するからです。
ペルソナの一貫性、目標追跡、適応的行動をシミュレーションフレームワーク(simulation framework)に組み込むことが、構造化されたユーザーシミュレーションとアドホックなプロンプト(ad-hoc prompting)を区別します。Strands EvalsのActorSimulatorは、まさにこれらの原則に基づいて設計されています。
ActorSimulatorの仕組み
ActorSimulatorは、現実的なユーザーペルソナとして振る舞うように設定されたStrands Agentをラップするシステムを通じて、これらのシミュレーション品質を実装します。プロセスはプロファイル生成(profile generation)から始まります。入力クエリ(input query)とオプションのタスク説明(task description)を含むテストケースが与えられると、ActorSimulatorはLLMを使用して完全なアクタープロファイル(actor profile)を作成します。「パリ行きのフライトの予約を手伝ってほしい」という入力と「予算内でフライト予約を完了する」というタスク説明を持つテストケースは、予算を気にする旅行者で、初心者レベルの経験とカジュアルなコミュニケーションスタイルを持つプロファイルを生成するかもしれません。プロファイル生成により、各シミュレートされた会話に明確で一貫したキャラクターが与えられます。
プロファイルが確立されると、シミュレーターはターンごとに会話を管理します。完全な会話履歴(conversation history)を維持し、各応答をコンテキスト内で生成し、シミュレートされたユーザーの行動をそのプロファイルと目標に沿って維持します。エージェントがリクエストの一部だけに対処した場合、シミュレートされたユーザーは自然にギャップについてフォローアップします。エージェントからの明確化の質問には、ペルソナと一貫した応答が返されます。すべての応答がアクターのペルソナとこれまでに言われたすべてのことを反映しているため、会話は有機的に感じられます。
目標追跡は会話と並行して実行されます。ActorSimulatorには、シミュレートされたユーザーが呼び出して元の目的が達成されたかどうかを評価できる、組み込みの目標完了評価ツール(goal completion assessment tool)が含まれています。目標が満たされたとき、またはシミュレートされたユーザーがエージェントがリクエストを完了できないと判断したとき、シミュレーターは停止信号(stop signal)を発し、会話は終了します。目標が達成される前に最大ターン数(maximum turn count)に達した場合も、会話は停止します。これにより、エージェントがユーザーニーズを効率的に解決していない可能性があるという信号が得られます。このメカニズムにより、会話が無限に実行されたり任意に切断されたりするのではなく、自然な終点を持つことが保証されます。
シミュレートされたユーザーからの各応答には、メッセージテキストとともに構造化された推論(structured reasoning)も含まれます。シミュレートされたユーザーがなぜその発言を選んだのか、不足している情報についてフォローアップしていたのか、混乱を表現していたのか、会話を方向転換していたのかを調べることができます。この透明性(transparency)は評価開発中に価値があります。なぜなら、各ターンの背後にある推論を見ることができ、会話がどこで成功し、どこで軌道を外れたかを追跡することがより簡単になるからです。
ActorSimulatorの始め方
始めるには、Strands Evaluation SDKをインストールする必要があります: pip install strands-agents-evals。ステップバイステップのセットアップについては、当社のドキュメントまたは以前のブログを参照して詳細を確認できます。これらの概念を実践に移すには最小限のコードが必要です。入力クエリとユーザーの目標を捉えたタスク説明を含むテストケースを定義します。ActorSimulatorはプロファイル生成、会話管理、目標追跡を自動的に処理します。
以下の例は、マルチターンのシミュレートされた会話を通じて旅行アシスタントエージェントを評価します。
from strands import Agent
from strands_evals import ActorSimulator, Case, Experimentテストケースを定義する
case = Case(
input="東京への旅行をホテルとアクティビティ込みで計画したい",
metadata={"task_description": "旅行パッケージの手配完了"}
)
評価したいエージェントを作成する
agent = Agent(
system_prompt="あなたは親切な旅行アシスタントです。",
callback_handler=None
)
テストケースからユーザーシミュレーターを作成する
user_sim = ActorSimulator.from_case_for_user_simulator(
case=case,
max_turns=5
)
マルチターン会話を実行する
user_message = case.input
conversation_history = []
while user_sim.has_next():
# エージェントがユーザーに応答する
agent_response = agent(user_message)
agent_message = str(agent_response)
conversation_history.append({
"role": "assistant",
"content": agent_message
})
# シミュレーターが次のユーザーメッセージを生成する
user_result = user_sim.act(agent_message)
user_message = str(user_result.structured_output.message)
conversation_history.append({
"role": "user",
"content": user_message
})
print(f"会話は{len(conversation_history) // 2}ターンで完了しました")
会話ループは、シミュレートされたユーザーの目標が達成されるか、シミュレートされたユーザーがエージェントがリクエストを完了できないと判断するか、最大ターン制限に達したときにhas_next()がFalseを返すまで続きます。結果のconversation_historyには、評価の準備が整った完全なマルチターントランスクリプトが含まれています。
評価パイプラインとの統合
スタンドアロンの会話ループは迅速な実験には便利ですが、本番環境での評価にはトレースをキャプチャして評価パイプラインにフィードする必要があります。次の例では、ActorSimulatorをOpenTelemetryテレメトリ収集とStrands Evalsセッションマッピングと組み合わせています。タスク関数はシミュレートされた会話を実行し、各ターンからスパンを収集してから、評価用に構造化されたセッションにマッピングします。
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.sdk.trace.export.in_memory_span_exporter import InMemorySpanExporter
from strands import Agent
from strands_evals import ActorSimulator, Case, Experiment
from strands_evals.evaluators import HelpfulnessEvaluator
from strands_evals.telemetry import StrandsEvalsTelemetry
from strands_evals.mappers import StrandsInMemorySessionMapper
エージェントトレースをキャプチャするためのテレメトリをセットアップ
telemetry = StrandsEvalsTelemetry()
memory_exporter = InMemorySpanExporter()
span_processor = BatchSpanProcessor(memory_exporter)
telemetry.tracer_provider.add_span_processor(span_processor)
def evaluation_task(case: Case) -> dict:
# シミュレーターを作成
user_sim = ActorSimulator.from_case_for_user_simulator(
case=case,
max_turns=3
)
# エージェントを作成
agent = Agent(
system_prompt="あなたは親切な旅行アシスタントです。",
callback_handler=None
)
# 会話全体でスパンを蓄積
all_target_spans = []
user_message = case.input
while user_sim.has_next():
memory_exporter.clear()
agent_response = agent(user_message)
agent_message = str(agent_response)
# テレメトリをキャプチャ
turn_spans = list(memory_exporter.get_finished_spans())
all_target_spans.extend(turn_spans)
# 次のユーザーメッセージを生成
user_result = user_sim.act(agent_message)
user_message = str(user_result.structured_output.message)
# 評価用にセッションにマッピング
mapper = StrandsInMemorySessionMapper()
session = mapper.map_to_session(
all_target_spans,
session_id="test-session"
)
return {"output": agent_message, "trajectory": session}
評価データセットを作成
test_cases = [
Case(
name="booking-simple",
input="来週パリ行きのフライトを予約する必要があります",
metadata={
"category": "booking",
"task_description": "フライト予約が確定"
}
)
]
evaluator = HelpfulnessEvaluator()
dataset = Experiment(cases=test_cases, evaluator=evaluator)
評価を実行
report = Experiment.run_evaluations(evaluation_task)
report.run_display()
このアプローチにより、会話ターン全体にわたるエージェントの動作の完全なトレースをキャプチャできます。スパンには、シミュレートされた会話の各ターンにおけるツール呼び出し、モデル呼び出し、タイミング情報が含まれます。これらのスパンを構造化されたセッションにマッピングすることで、GoalSuccessRateEvaluatorやHelpfulnessEvaluatorなどの評価者が、孤立したターンではなく会話全体として評価できるようになります。
ターゲットテストのためのカスタムアクタープロファイル
自動プロファイル生成はほとんどの評価シナリオをうまくカバーしますが、一部のテスト目標には特定のペルソナが必要です。エージェントが忍耐強い初心者とは異なる方法で短気な専門家ユーザーを扱うことや、ドメイン固有のニーズを持つユーザーに適切に応答することを確認したい場合があります。これらのケースでは、ActorSimulatorは完全に定義されたアクタープロファイルを受け入れます。
from strands_evals.types.simulation import ActorProfile
from strands_evals import ActorSimulator
from strands_evals.simulation.prompt_templates.actor_system_prompt import (
DEFAULT_USER_SIMULATOR_PROMPT_TEMPLATE
)
カスタムアクタープロファイルを定義
actor_profile = ActorProfile(
traits={
"personality": "分析的で細部にこだわる",
"communication_style": "直接的で技術的",
"expertise_level": "専門家",
"patience_level": "低い"
},
context="効率を重視するエリートステータスを持つ経験豊富なビジネストラベラー",
actor_goal="特定の座席設定とラウンジアクセス付きのビジネスクラスフライトを予約"
)
カスタムプロファイルでシミュレーターを初期化
user_sim = ActorSimulator(
actor_profile=actor_profile,
initial_query="来週の火曜日にロンドン行きのビジネスクラスフライトを予約する必要があります",
system_prompt_template=DEFAULT_USER_SIMULATOR_PROMPT_TEMPLATE,
max_turns=10
)
忍耐レベル、コミュニケーションスタイル、専門知識などの特性を定義することで、エージェントが異なるユーザーセグメントでどのように機能するかを体系的にテストできます。忍耐強く非技術的なユーザーでは高得点を獲得するが、短気な専門家では低得点のエージェントは、対処できる特定の品質ギャップを明らかにします。同じ目標を複数のペルソナ構成で実行することで、ユーザーシミュレーションはユーザータイプごとのエージェントの強みと弱みを理解するためのツールになります。
シミュレーションベース評価のベストプラクティス
これらのベストプラクティスは、シミュレーションベース評価を最大限に活用するのに役立ちます:
- タスクの複雑さに基づいてmax_turnsを設定し、集中型タスクには3-5、マルチステップワークフローには8-10を使用します。ほとんどの会話が目標を達成せずに制限に達する場合は、増やしてください。
- シミュレーターが評価できる具体的なタスク説明を書いてください。「ユーザーがフライトを予約するのを手伝う」は完了を確実に判断するには曖昧すぎますが、「日付、目的地、価格が確定したフライト予約」は具体的な目標を提供します。
- ユーザータイプ全体の広範なカバレッジには自動生成プロファイルを使用し、短気な専門家や初回ユーザーなど、本番ログからの特定のパターンを再現するにはカスタムプロファイルを使用します。
- 個々のトランスクリプトではなく、テストスイート全体のパターンに焦点を当ててください。シミュレートされたユーザーからの一貫したリダイレクトは、エージェントが話題から外れていることを示唆し、エージェント変更後の目標達成率の低下は回帰を示します。
- 最も一般的なシナリオをカバーする小さなテストケースセットから始め、評価手法が成熟するにつれてエッジケースと追加のペルソナに拡張します。
結論
Strands EvalsのActorSimulatorが、現実的なユーザーシミュレーションを通じて会話型AIエージェントの体系的でマルチターンの評価を可能にする方法を示しました。単一のやり取りのみをキャプチャする静的なテストケースに依存するのではなく、目標とペルソナを定義し、シミュレートされたユーザーが自然で適応的な会話を通じてエージェントと対話できるようにします。結果のトランスクリプトは、シングルターンテストに使用するのと同じ評価パイプラインに直接フィードされ、親切さスコア、目標達成率、すべての会話ターンにわたる詳細なトレースを提供します。
開始するには、Strands Agentsサンプルリポジトリの実際の例を探索してください。
原文を表示
Evaluating single-turn agent interactions follows a pattern that most teams understand well. You provide an input, collect the output, and judge the result. Frameworks like Strands Evaluation SDK make this process systematic through evaluators that assess helpfulness, faithfulness, and tool usage. In a previous blog post, we covered how to build comprehensive evaluation suites for AI agents using these capabilities. However, production conversations rarely stop at one turn.
Real users engage in exchanges that unfold over multiple turns. They ask follow-up questions when answers are incomplete, change direction when new information surfaces, and express frustration when their needs go unmet. A travel assistant that handles “Book me a flight to Paris” well in isolation might struggle when the same user follows up with “Actually, can we look at trains instead?” or “What about hotels near the Eiffel Tower?” Testing these dynamic patterns requires more than static test cases with fixed inputs and expected outputs.
The core difficulty is scale because you can’t manually conduct hundreds of multi-turn conversations every time your agent changes, and writing scripted conversation flows locks you into predetermined paths that miss how real users behave. What evaluation teams need is a way to generate realistic, goal-driven users programmatically and let them converse naturally with an agent across multiple turns. In this post, we explore how ActorSimulator in Strands Evaluations SDK addresses this challenge with structured user simulation that integrates into your evaluation pipeline.
Why multi-turn evaluation is fundamentally harder

Single-turn evaluation has a straightforward structure. The input is known ahead of time, the output is self-contained, and the evaluation context is limited to that single exchange. Multi-turn conversations break every one of these assumptions.
In a multi-turn interaction, each message depends on everything that came before it. The user’s second question is shaped by how the agent answered the first. A partial answer draws a follow-up about whatever was left out, a misunderstanding leads the user to restate their original request, and a surprising suggestion can send the conversation in a new direction.
These adaptive behaviors create conversation paths that can’t be predicted at test-design time. A static dataset of I/O pairs, no matter how large, can’t capture this dynamic quality because the “correct” next user message depends on what the agent just said.
Manual testing covers this gap in theory but fails in practice. Testers can conduct realistic multi-turn conversations, but doing so for every scenario, across every persona type, after every agent change is not sustainable. As the agent’s capabilities grow, the number of conversation paths grows combinatorially, well beyond what teams can explore manually.
Some teams turn to prompt engineering as a shortcut, asking a large language model (LLM) to “act like a user” during testing. Without structured persona definitions and explicit goal tracking, these approaches produce inconsistent results. The simulated user’s behavior drifts between runs, making it difficult to compare evaluations over time or identify genuine regressions versus random variation. A structured approach to user simulation can bridge this gap by combining the realism of human conversation with the repeatability and scale of automated testing.
What makes a good simulated user
Simulation-based testing is well established in other engineering disciplines. Flight simulators test pilot responses to scenarios that would be dangerous or impossible to reproduce in the real world. Game engines use AI-driven agents to explore millions of player behavior paths before release. The same principle applies to conversational AI. You create a controlled environment where realistic actors interact with your system under conditions you define, then measure the outcomes.
For AI agent evaluation, a useful simulated user starts with a consistent persona. One that behaves like a technical expert in one turn and a confused novice in the next produces unreliable evaluation data. Consistency means to maintain the same communication style, expertise level, and personality traits through every exchange, just as a real person would.
Equally important is goal-driven behavior. Real users come to an agent with something they want to accomplish. They persist until they achieve it, adjust their approach when something is not working, and recognize when their goal has been met. Without explicit goals, a simulated user tends to either end conversations too early or continue asking questions indefinitely, neither of which reflects real usage.
The simulated user must also respond adaptively to what the agent says, not follow a predetermined script. When the agent asks a clarifying question, the actor should answer it in character. If the response is incomplete, the actor follows up on whatever was left out rather than moving on. If the conversation drifts off topic, the actor steers it back toward the original goal. These adaptive behaviors make simulated conversations valuable as evaluation data because they exercise the same conversation dynamics your agent faces in production.
Building persona consistency, goal tracking, and adaptive behavior into a simulation framework is what differentiates structured user simulation from ad-hoc prompting. ActorSimulator in Strands Evals is designed around exactly these principles.
How ActorSimulator works
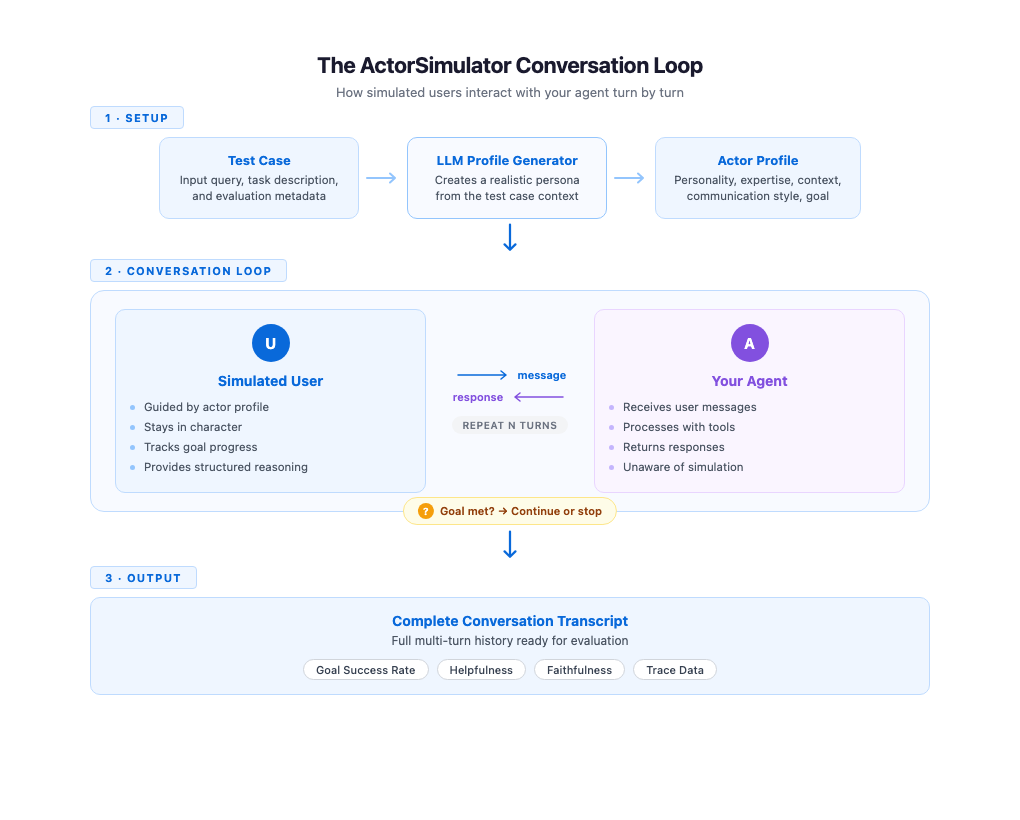
ActorSimulator implements these simulation qualities through a system that wraps a Strands Agent configured to behave as a realistic user persona. The process begins with profile generation. Given a test case containing an input query and an optional task description, ActorSimulator uses an LLM to create a complete actor profile. A test case with input “I need help booking a flight to Paris” and task description “Complete flight booking under budget” might produce a budget-conscious traveler with beginner-level experience and a casual communication style. Profile generation gives each simulated conversation a distinct, consistent character.
With the profile established, the simulator manages the conversation turn by turn. It maintains the full conversation history and generates each response in context, keeping the simulated user’s behavior aligned with their profile and goals throughout. When your agent addresses only part of the request, the simulated user naturally follows up on the gaps. A clarifying question from your agent gets a response that stays consistent with the persona. The conversation feels organic because every response reflects both the actor’s persona and everything said so far.
Goal tracking runs alongside the conversation. ActorSimulator includes a built-in goal completion assessment tool that the simulated user can invoke to evaluate whether their original objective has been met. When the goal is satisfied or the simulated user determines that the agent cannot complete their request, the simulator emits a stop signal and the conversation ends. If the maximum turn count is reached before the goal is met, the conversation also stops. This gives you a signal that the agent might not be resolving user needs efficiently. This mechanism makes sure conversations have a natural endpoint rather than running indefinitely or cutting off arbitrarily.
Each response from the simulated user also includes structured reasoning alongside the message text. You can inspect why the simulated user chose to say what they said, whether they were following up on missing information, expressing confusion, or redirecting the conversation. This transparency is valuable during evaluation development because you can see the reasoning behind each turn, making it more straightforward to trace where conversations succeed or go off track.
Getting started with ActorSimulator
To get started, you will need to install the Strands Evaluation SDK using: pip install strands-agents-evals. For a step-by-step setup, you can refer to our documentation or our previous blog for more details. Putting these concepts into practice requires minimal code. You define a test case with an input query and a task description that captures the user’s goal. ActorSimulator handles profile generation, conversation management, and goal tracking automatically.
The following example evaluates a travel assistant agent through a multi-turn simulated conversation.
from strands import Agent
from strands_evals import ActorSimulator, Case, Experiment
# Define your test case
case = Case(
input="I want to plan a trip to Tokyo with hotel and activities",
metadata={"task_description": "Complete travel package arranged"}
)
# Create the agent you want to evaluate
agent = Agent(
system_prompt="You are a helpful travel assistant.",
callback_handler=None
)
# Create user simulator from test case
user_sim = ActorSimulator.from_case_for_user_simulator(
case=case,
max_turns=5
)
# Run the multi-turn conversation
user_message = case.input
conversation_history = []
while user_sim.has_next():
# Agent responds to user
agent_response = agent(user_message)
agent_message = str(agent_response)
conversation_history.append({
"role": "assistant",
"content": agent_message
})
# Simulator generates next user message
user_result = user_sim.act(agent_message)
user_message = str(user_result.structured_output.message)
conversation_history.append({
"role": "user",
"content": user_message
})
print(f"Conversation completed in {len(conversation_history) // 2} turns")The conversation loop continues until has_next() returns False, which happens when the simulated user’s goals are met or simulated user determines that the agent cannot complete the request or the maximum turn limit is reached. The resulting conversation_history contains the full multi-turn transcript, ready for evaluation.
Integration with evaluation pipelines

A standalone conversation loop is useful for quick experiments, but production evaluation requires capturing traces and feeding them into your evaluator pipeline. The next example combines ActorSimulator with OpenTelemetry telemetry collection and Strands Evals session mapping. The task function runs a simulated conversation and collects spans from each turn, then maps them into a structured session for evaluation.
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.sdk.trace.export.in_memory_span_exporter import InMemorySpanExporter
from strands import Agent
from strands_evals import ActorSimulator, Case, Experiment
from strands_evals.evaluators import HelpfulnessEvaluator
from strands_evals.telemetry import StrandsEvalsTelemetry
from strands_evals.mappers import StrandsInMemorySessionMapper
# Setup telemetry for capturing agent traces
telemetry = StrandsEvalsTelemetry()
memory_exporter = InMemorySpanExporter()
span_processor = BatchSpanProcessor(memory_exporter)
telemetry.tracer_provider.add_span_processor(span_processor)
def evaluation_task(case: Case) -> dict:
# Create simulator
user_sim = ActorSimulator.from_case_for_user_simulator(
case=case,
max_turns=3
)
# Create agent
agent = Agent(
system_prompt="You are a helpful travel assistant.",
callback_handler=None
)
# Accumulate spans across conversation
all_target_spans = []
user_message = case.input
while user_sim.has_next():
memory_exporter.clear()
agent_response = agent(user_message)
agent_message = str(agent_response)
# Capture telemetry
turn_spans = list(memory_exporter.get_finished_spans())
all_target_spans.extend(turn_spans)
# Generate next user message
user_result = user_sim.act(agent_message)
user_message = str(user_result.structured_output.message)
# Map to session for evaluation
mapper = StrandsInMemorySessionMapper()
session = mapper.map_to_session(
all_target_spans,
session_id="test-session"
)
return {"output": agent_message, "trajectory": session}
# Create evaluation dataset
test_cases = [
Case(
name="booking-simple",
input="I need to book a flight to Paris next week",
metadata={
"category": "booking",
"task_description": "Flight booking confirmed"
}
)
]
evaluator = HelpfulnessEvaluator()
dataset = Experiment(cases=test_cases, evaluator=evaluator)
# Run evaluations
report = Experiment.run_evaluations(evaluation_task)
report.run_display()
This approach captures complete traces of your agent’s behavior across conversation turns. The spans include tool calls, model invocations, and timing information for every turn in the simulated conversation. By mapping these spans into a structured session, you make the full multi-turn interaction available to evaluators like GoalSuccessRateEvaluator and HelpfulnessEvaluator, which can then assess the conversation as a whole, rather than isolated turns.
Custom actor profiles for targeted testing
Automatic profile generation covers most evaluation scenarios well, but some testing goals require specific personas. You might want to verify that your agent handles an impatient expert user differently from a patient beginner, or that it responds appropriately to a user with domain-specific needs. For these cases, ActorSimulator accepts a fully defined actor profile that you control.
from strands_evals.types.simulation import ActorProfile
from strands_evals import ActorSimulator
from strands_evals.simulation.prompt_templates.actor_system_prompt import (
DEFAULT_USER_SIMULATOR_PROMPT_TEMPLATE
)
# Define a custom actor profile
actor_profile = ActorProfile(
traits={
"personality": "analytical and detail-oriented",
"communication_style": "direct and technical",
"expertise_level": "expert",
"patience_level": "low"
},
context="Experienced business traveler with elite status who values efficiency",
actor_goal="Book business class flight with specific seat preferences and lounge access"
)
# Initialize simulator with custom profile
user_sim = ActorSimulator(
actor_profile=actor_profile,
initial_query="I need to book a business class flight to London next Tuesday",
system_prompt_template=DEFAULT_USER_SIMULATOR_PROMPT_TEMPLATE,
max_turns=10
)
By defining traits like patience level, communication style, and expertise, you can systematically test how your agent performs across different user segments. An agent that scores well with patient, non-technical users but poorly with impatient experts reveals a specific quality gap that you can address. Running the same goal across multiple persona configurations turns user simulation into a tool for understanding your agent’s strengths and weaknesses by user type.
Best practices for simulation-based evaluation
These best practices help you get the most out of simulation-based evaluation:
- Set max_turns based on task complexity, using 3-5 for focused tasks and 8-10 for multi-step workflows. If most conversations reach the limit without completing the goal, increase it.
- Write specific task descriptions that the simulator can evaluate against. “Help the user book a flight” is too vague to judge completion reliably, while “flight booking confirmed with dates, destination, and price” gives a concrete target.
- Use auto-generated profiles for broad coverage across user types and custom profiles to reproduce specific patterns from your production logs, such as an impatient expert or a first-time user.
- Focus on patterns across your test suite rather than individual transcripts. Consistent redirects from the simulated user suggests that the agent is drifting off topic, and declining goal completion rates after an agent change points to a regression.
- Start with a small set of test cases covering your most common scenarios and expand to edge cases and additional personas as your evaluation practice matures.
Conclusion
We showed how ActorSimulator in Strands Evals enables systematic, multi-turn evaluation of conversational AI agents through realistic user simulation. Rather than relying on static test cases that capture only single exchanges, you can define goals and personas and let simulated users interact with your agent across natural, adaptive conversations. The resulting transcripts feed directly into the same evaluation pipeline that you use for single-turn testing, giving you helpfulness scores, goal success rates, and detailed traces across every conversation turn.
To get started, explore the working examples in the Strands Agents samples repository. For teams evaluating agents deployed through <a href="https://aws.amazon.com/bedrock/agentcore/?trk=2bc12158-bb93-427c-a19a-1c398faebbc8&sc_channel=ps&ef_id=Cj0KCQjwsdnNBhC4ARIsAA_3heh_4Q-3loHC_p8uMMAejTQt0u4gEE60U9aof3U1kdfNflYc9-6z7pEaAgtGEALw_wcB:G:s&s_kwcid=AL!4422!3!798517281045!e!!g!!agentcore!23606216570!196197897240&gad_campaignid=23606216570&gbraid=0AAAAADjHtp8Xb3vFSacq1jB
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み