AWS上のHugging Face smolagentsを用いたマルチモデルフレームワークによるエージェント型AI
Hugging FaceのsmolagentsライブラリとAWSマネージドサービス(SageMaker、Bedrock)を統合し、医療分野におけるマルチモデル駆動の自律型エージェント(Agentic AI)の実装例とアーキテクチャを示す技術記事。
キーポイント
Agentic AIの進化と企業向けデプロイ
対話型AIから、複雑な推論、ツール使用、コード実行が可能な自律型エージェントへの進化を示し、エンタープライズ向けに自動スケーリングやカスタム統合に対応する管理エンドポイントの重要性を強調。
smolagentsとAWSの統合実装
Hugging Face smolagentsを用いて、Amazon SageMaker AIエンドポイント、Amazon Bedrock API、コンテナ化されたモデルサーバーをオーケストレーションする具体的な実装手法を紹介。
医療分野でのユースケースとセキュリティ
6つの薬剤に関する臨床意思決定支援を例に、ベクトル検索による知識統合とAWSのセキュリティ・コンプライアンス機能を組み合わせた信頼性の高いアーキテクチャを提示。
単一モデルの限界とマルチモデルアプローチ
単一モデルのアプローチが抱える柔軟性の欠如やAPIの不一致という課題を解決し、運用ニーズに基づいて最適なモデルを選択できるマルチモデル展開の可能性を示唆。
影響分析・編集コメントを表示
影響分析
本記事は、単一のLLMに依存しない「エージェント型AI」の実装パターンを具体化しており、企業におけるAI導入の次のステップとして、複数のモデルや既存インフラ(SageMaker等)を統合して自律的な意思決定を行うシステム構築の標準的なアプローチを示している。これにより、開発者は柔軟かつ堅牢なAIソリューションを設計できるようになる。
編集コメント
AWSとHugging Faceの連携により、実務レベルでのAgentic AI構築ハードルが下がる具体的なコード例とアーキテクチャ図は、開発者にとって非常に参考になる。医療データのような機微な情報を扱う場合のセキュリティ考慮事項にも言及されており、実装時の注意点も押さえられている。
*この投稿は、Hugging Face の Jeff Boudier, Simon Pagezy, Florent Gbelidji によって共同執筆されました。*
Agentic AI システムは、複雑な推論、ツール使用、コード実行が可能な自律型エージェントへと進化を遂げた対話型 AI から派生したものです。エンタープライズアプリケーションでは、特定のニーズに合わせた戦略的な展開アプローチから恩恵を受けます。これらのニーズには、自動スケーリング機能を提供するマネージドエンドポイント、複雑な推論をサポートするファウンデーションモデル API、カスタム統合要件に対応できるコンテナ化された展開オプションが含まれます。
Hugging Face smolagents は、数行のコードでエージェントを構築して実行することを容易にするために設計されたオープンソースの Python ライブラリです。ここでは、Amazon Web Services (AWS) のマネージドサービスと Hugging Face smolagents を統合することで、Agentic AI ソリューションをどのように構築するかを示します。あなたは、マルチモデル展開オプション、ベクトル強化された知識検索機能、および臨床意思決定支援機能を備えた医療用 AI エージェントの展開方法を学びます。
医療を例に挙げていますが、このアーキテクチャは、ドメイン固有の知性と信頼性が極めて重要な複数の業界にも適用可能です。本ソリューションでは、smolagents のモデル非依存・モダリティ非依存・ツール非依存という設計を活用し、Amazon SageMaker AI エンドポイント、Amazon Bedrock API、およびコンテナ化されたモデルサーバー間でオーケストレーションを行います。
ソリューション概要
多くの AI システムは、多様な企業ニーズに適応できない単一モデルアプローチに制約を抱えています。これらのシステムには、デプロイメントオプションが硬直的であったり、異なる AI サービス間で API が一貫していなかったり、最適なモデル選択のためのマルチモデルデプロイメントオプションが欠如していたりする傾向があります。
本ソリューションは、組織がいかにしてこれらの制約に対処する AI システムを構築できるかを示しています。このソリューションでは、運用上のニーズに基づいてデプロイメントを選択でき、異なる AI バックエンドやデプロイメント方法間でも一貫したリクエスト・レスポンス形式を提供します。また、医療知識の統合とベクトル検索を通じて文脈に応じた応答を生成し、コンテナ化アーキテクチャにより開発環境から本番環境までの展開をサポートします。
この医療ユースケースでは、AI エージェントが臨床意思決定支援および AWS のセキュリティ・コンプライアンス機能を活用して、6 つの薬剤に関する複雑な医療クエリをどのように処理するかを示しています。
アーキテクチャ
本ソリューションは、エージェント型 AI の機能を提供するために以下のサービスと機能で構成されています:
- 専門的な医療クエリへの対応と管理された自動スケーリングを実現するための、BioM-ELECTRA-Large-SQuAD2 モデルを搭載した SageMaker AI。
- 複雑な推論とファウンデーションモデルへのアクセスを提供するための、Anthropic 製の Claude 3.5 Sonnet V2 を利用する Amazon Bedrock。
- 医療知識のインデックス化によるベクトル類似度マッチングおよび文脈に基づく知識検索を行うための Amazon OpenSearch Service。
- smolagents ライブラリを利用した Python アプリケーションのサーバーレスコンテナオーケストレーションとスケーラブルな展開を実現するための、AWS Fargate を備えた Amazon Elastic Container Service (Amazon ECS)。
- セキュリティおよびアクセス制御のための AWS Identity and Access Management (IAM)。
- 自己ホスト型モデルデプロイメントのための、BioM-ELECTRA-Large-SQuAD2 モデルを搭載したコンテナ化されたモデルサーバー。
以下の図は本ソリューションのアーキテクチャを示しています。
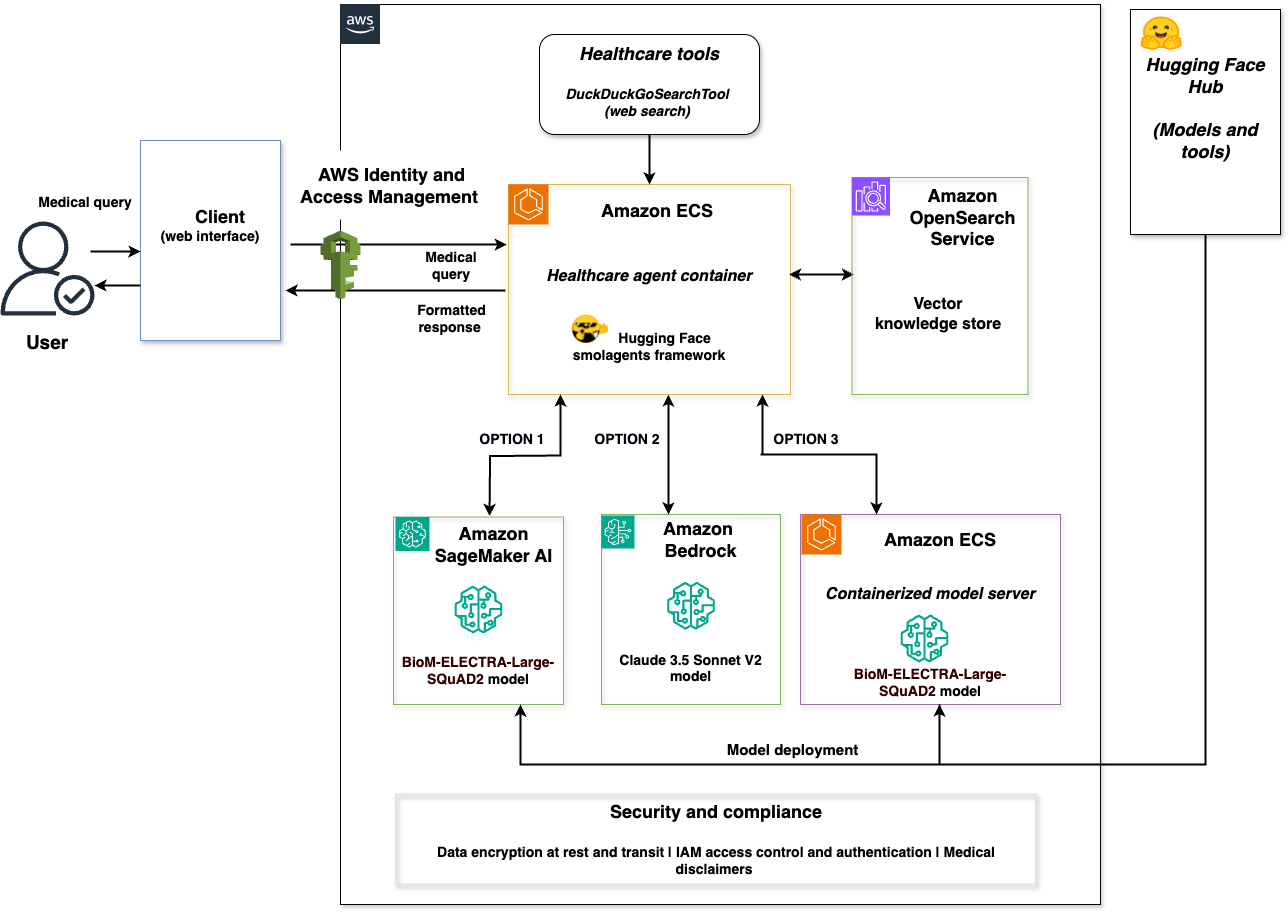
アーキテクチャは、Hugging Face smolagents フレームワークと AWS サービスの完全な統合です。クライアントの Web インターフェースは、3 つのモデルバックエンド間でオーケストレーションを行うヘルスケアエージェントコンテナに接続されています。これら 3 つのバックエンドとは、BioM-ELECTRA を使用する SageMaker AI、Claude 3.5 Sonnet V2 を使用する Amazon Bedrock、および BioM-ELECTRA を使用するコンテナ化されたモデルサーバーです。本ソリューションには、OpenSearch Service に支えられたベクトルストアと、保存時および転送時のデータ暗号化を備えたセキュリティレイヤーが含まれています。セキュリティレイヤーはまた、IAM アクセス制御と認証、ならびに規制遵守のための医療に関する免責事項の処理も担当します。
このソリューションは、smolagents を通じたデプロイオプションをサポートしており、各バックエンドが異なるシナリオに対して最適化されています:
- Hugging Face Hub のモデルを使用した自動スケーリングと本番ワークロード向けに管理されたエンドポイントを提供する SageMaker AI。
- AWS API を介した基盤モデルへのサーバーレスアクセスおよび複雑な推論を実現する Amazon Bedrock。
- Hugging Face Hub からのセルフホスト型モデルデプロイメントおよびツール統合を可能にするコンテナ化されたモデルサーバー。
3 つのバックエンドは Hugging Face Messages API の互換性 を実装しており、選択されたモデルサービスに関わらず、一貫したリクエストおよびレスポンス形式が保証されています。ユーザーは要件に基づいて適切なバックエンドを選択します。本ソリューションは自動ルーティングを提供するものではなく、デプロイオプションを提供するものです。
完全な実装は、sample-healthcare-agent-with-smolagents-on-aws GitHub リポジトリ で利用可能です。
主な利点
Hugging Face smolagents と AWS マネージドサービスの統合は、エンタープライズ向けエージェント AI の導入において大きなメリットをもたらします。
デプロイメントの選択肢
組織は、各ユースケースに最適なデプロイメントを選択できます。基盤モデルへのサーバーレスアクセスには Amazon Bedrock を、カスタムツールの統合や SageMaker AI による専門ドメインモデルには、コンテナ化されたセルフホスト型デプロイメントを利用します。これらのオプションにより、画一的なアプローチではなく、特定のワークロード要件に合わせたマッチングが可能になります。
マルチモデルデプロイメントの選択肢
組織は、エージェントロジックを変更することなく、インフラストラクチャの選択を最適化できます。アプリケーションコードを変更せずに、コンテナ化されたモデルサーバー、SageMaker AI、Amazon Bedrock を切り替えることが可能です。これにより、一貫したエージェント動作を維持しながら、デプロイメントの選択肢を提供します。
コード生成機能
smolagents の CodeAgent アプローチは、Python コードの直接生成と処理を通じて、多段階操作を簡素化します。以下の比較は、smolagents の多段階操作を示しています:
JSON ベースの多段階アプローチ:
{
"action": "search",
"parameters": {"query": "drug interactions"},
"next_action": {
"action": "filter",
"parameters": {"criteria": "severity > moderate"}
}
}
## smolagents CodeAgent:
# Search and filter in single code block
results = search_tool("drug interactions")
filtered_results = [r for r in results if r.severity > "moderate"]
final_answer(f"Found {len(filtered_results)} severe interactions: {filtered_results}")
smolagents の CodeAgent は、単一のコードブロック内で多段階の操作を処理することをサポートしており、大規模言語モデル(LLM)の呼び出し回数を削減しながらエージェント開発を合理化します。これにより、AWS サービス展開全体にわたるエージェントロジックの完全な制御が可能になります。
## スケーラブルなアーキテクチャ
アプリケーションを AWS にデプロイすることで、組織のセキュリティ要件を満たし規制コンプライアンスを維持するのに役立つセキュリティ機能と自動スケーリング機能を入手できます。Amazon ECS および Fargate でコンテナ化されたワークロードを実行することで、自動化されたリソーススケーリングを通じて信頼性の高い運用を実現し、コストを最適化できます。
それでは、このソリューションの実装について見ていきましょう。
## 前提条件
ソリューションをデプロイする前に、以下のものが必要です:
- IAM ロール、Amazon ECS クラスター、および Amazon OpenSearch Service ドメインを作成するための適切な権限を持つ AWS アカウント。
- 設定済みでインストールされた AWS Command Line Interface (AWS CLI) バージョン 2.0 以降。
- デプロイメントスクリプトを実行するための Python 3.10 以降。
- Docker のインストールと実行(本番環境では安全なコード実行サンドボックスを提供するために必須)。
- AWS リージョン内の Amazon Bedrock、SageMaker AI、および OpenSearch Service へのアクセス権限。リソースの作成と管理には適切な IAM 権限が必要です。
- 今回の実装では、Python 3.10+、smolagents フレームワーク、transformers 4.28.1+、PyTorch 2.0.0+、および boto3 を使用します。
必要な Python パッケージをインストールするには、以下のコマンドを実行してください:
pip install -r healthcare_ai_agent/phase_00_installation/requirements.txt
環境変数の設定
インフラストラクチャをデプロイする前に、AWS リージョンとリソース名に対応する必要な環境変数を設定してください。
- 以下の環境変数をターミナルで設定します:
export AWS_REGION=us-west-2
export SAGEMAKER_ENDPOINT_NAME=healthcare-qa-endpoint-1
export OPENSEARCH_DOMAIN=healthcare-vector-store
export OPENSEARCH_INDEX=medical-knowledge
export BEDROCK_MODEL_ID=anthropic.claude-3-5-sonnet-20241022-v2:0
export SAGEMAKER_MODEL_ID=sultan/BioM-ELECTRA-Large-SQuAD2
export CONTAINERIZED_MODEL_ID=sultan/BioM-ELECTRA-Large-SQuAD2
- 変数が設定されていることを確認する:
echo $AWS_REGION
echo $SAGEMAKER_ENDPOINT_NAME
これらの環境変数は、デプロイおよびテストのプロセス全体で使用されます。次のステップに進む前に、これらが正しく設定されていることを確認してください。
AWS インフラストラクチャのセットアップ
Smolagents_SageMaker_Bedrock_Opensearch.py の実装に含まれる SampleAWSInfrastructureManager クラスを使用して、基盤となる AWS インフラストラクチャコンポーネントの作成から始めます。
完全なインフラストラクチャのデプロイ(自動化アプローチ)
AWS インフラストラクチャコンポーネントを自動的にデプロイするには、拡張された main 関数を使用できます。
- 拡張された main 関数の実行:
from Smolagents_SageMaker_Bedrock_Opensearch import enhanced_main
enhanced_main()
完全な AWS インフラストラクチャのデプロイにはオプション 1 を選択します
- デプロイにより、Amazon ECS クラスター、IAM ロール、および OpenSearch Service ドメインが自動的に作成されます。
- デプロイが完了するまで待機してください(約 15〜20 分)。
AWS コンポーネントの個別作成(代替アプローチ)
コンポーネントを個別に作成したい場合は、ベクトル強化された知識検索用の OpenSearch Service ドメインと、コンテナ化デプロイ用の Amazon ECS クラスターを設定できます。
OpenSearch Service ドメインと Amazon ECS クラスターは、完全な AWS インフラストラクチャのデプロイメント(enhanced_main のオプション 1)の一部として自動的に作成されます。すでに完全なインフラストラクチャをデプロイ済みの場合、両方のコンポーネントが準備されているため、Amazon SageMaker AI エンドポイントのデプロイセクションへスキップできます。
Amazon SageMaker AI エンドポイントのデプロイ
専門的な医療問い合わせ処理のために、BioM-ELECTRA-Large-SQuAD2 モデルを SageMaker AI へデプロイします。デプロイには、enhanced_main を通じて行うための自動化された方法と、SageMaker AI エンドポイントを介して行うための手動方法の両方が用意されています。
enhanced main を使用したデプロイ(自動化方法)
from Smolagents_SageMaker_Bedrock_Opensearch import enhanced_main
enhanced_main 関数の開始
enhanced_main()
SageMaker エンドポイントのデプロイにはオプション 2 を選択する
SageMaker AI エンドポイントの手動デプロイ方法
- SageMaker の環境変数が設定されていることを確認します(「環境変数の設定」セクションから):
echo $SAGEMAKER_MODEL_ID
echo $SAGEMAKER_ENDPOINT_NAME
- Amazon SageMaker 用デプロイメント関数を実行します:
from Smolagents_SageMaker_Bedrock_Opensearch import deploy_sagemaker_endpoint_safe
endpoint_name = deploy_sagemaker_endpoint_safe()
- デプロイメントには HuggingFaceModel を使用し、transformers 4.28.1、PyTorch 2.0.0、および ml.m5.xlarge インスタンスタイプを指定しています。
- エンドポイントのデプロイが完了するまでお待ちください(約 5〜10 分)。
- エンドポイントのデプロイ状況を確認します:
エンドポイントステータスの確認
print(f"✅ Endpoint deployed: {endpoint_name}")
- エンドポイントは、MAX_LENGTH=512 および TEMPERATURE=0.1 を設定した質問応答タスク用に構成されています。
マルチモデルバックエンドの構成
SampleTripleHealthcareAgent クラスを使用して、運用上の要件に基づいたモデル選択を行うための 2 つの追加バックエンドオプションを構成します。
オプション 1 – Amazon Bedrock アクセスの設定
Claude 3.5 Sonnet V2 を含む基盤モデルとの統合のために、Amazon Bedrock へのアクセスを設定します。
- Amazon Bedrock のモデル設定が完了していることを確認してください(「環境変数の構成」セクションから):
echo $BEDROCK_MODEL_ID
- AWS アカウントには Claude 3.5 Sonnet V2 へのアクセス権限が自動的に付与されています。
- モデルの利用可否は、Amazon Bedrock コンソールの Model catalog で確認できます。
医療知識ベースの初期化
OpenSearch Service に 6 つの薬剤とベクトル埋め込みを含む医療知識データベースを設定します。デプロイメントタスク用の対話型メニューを提供する enhanced_main() 関数を使用するか、SampleOpenSearchManager クラスを使用して手動で初期化できます。
エンハンスドメイン(自動化手法)を使用した初期化
from Smolagents_SageMaker_Bedrock_Opensearch import enhanced_main
エンハンスドメイン関数の開始
enhanced_main()
オプション 4 を選択して OpenSearch の初期化と医療知識のインデックス作成を行う
医療知識ベースの初期化(手動手法)
- SampleOpenSearchManager を初期化する:
from Smolagents_SageMaker_Bedrock_Opensearch import enhanced_main
エンハンスドメイン関数の開始
enhanced_main()
オプション 4 を選択して OpenSearch の初期化と医療知識のインデックス作成を行う
- システムは、drug_name(薬剤名)、content(内容)、content_type(コンテンツタイプ)フィールドのマッピングを持つ医療知識インデックスを作成します。
- メトホルミン、リシノプリル、アトルバスタチン、アムロジピン、オメプラゾール、シンバスタチンの医療知識が自動的にインデックスされます。
- 各薬剤には副作用、モニタリング要件、および薬剤クラス情報が含まれています。
- ベクトルストアは、ターゲットクエリのためのコンテンツタイプフィルタ付きの類似度検索をサポートしています。
- インデックス作成が正常に完了したことを確認する:
# インデックス作成の正常な完了を確認
print("Medical knowledge base initialized with 6 medications")
オプション 2 – コンテナ化モデルサーバーのデプロイ
コアインフラストラクチャの設定後、セルフホスト型モデル展開機能を提供するコンテナ化モデルサーバーをデプロイします。
BioM-ELECTRA-Large-SQuAD2 モデルのデプロイには、LocalContainerizedModelServer クラスを使用してコンテナ化されたモデルサーバーをデプロイします。
コンテナを Amazon ECS にデプロイする方法(自動化された方法)
自動化されたデプロイには、コンテナ化された Amazon ECS デプロイメントを使用してください:
from Smolagents_SageMaker_Bedrock_Opensearch import enhanced_main
拡張メイン関数の開始
enhanced_main()
ECS コンテナデプロイのためにオプション 3 を選択
コンテナ化されたモデルサーバーをデプロイする方法(手動方法)
- コンテナ化されたモデル設定が設定されていることを確認してください(環境変数の設定ステップから):
echo $CONTAINERIZED_MODEL_ID
- コンテナ化されたモデルサーバーを初期化します:
from Smolagents_SageMaker_Bedrock_Opensearch import LocalContainerizedModelServer
containerized_server = LocalContainerizedModelServer()
containerized_server.start_server()
コンテナ化されたモデルサーバーは、安全なコード実行のために Docker サンドボックス(Docker sandboxing)を使用します。
- コンテナ化されたモデルサーバーが稼働していることを確認します:
print(f"✅ Containerized Model Server status: {containerized_server.get_status()}")
コンテナ化されたモデルサーバーには以下が含まれています
原文を表示
*This post is cowritten by Jeff Boudier, Simon Pagezy, and Florent Gbelidji from Hugging Face.*
Agentic AI systems represent an evolution from conversational AI to autonomous agents capable of complex reasoning, tool usage, and code execution. Enterprise applications benefit from strategic deployment approaches tailored to specific needs. These needs include managed endpoints, which deliver auto-scaling capabilities, foundation model APIs to support complex reasoning, and containerized deployment options that support custom integration requirements.
Hugging Face smolagents is an open source Python library designed to make it straightforward to build and run agents using a few lines of code. We will show you how to build an agentic AI solution by integrating Hugging Face smolagents with Amazon Web Services (AWS) managed services. You’ll learn how to deploy a healthcare AI agent that demonstrates multi-model deployment options, vector-enhanced knowledge retrieval, and clinical decision support capabilities.
While we use healthcare as an example, this architecture applies to multiple industries where domain-specific intelligence and reliability are critical. The solution uses the model-agnostic, modality-agnostic, and tool-agnostic design of smolagents to orchestrate across Amazon SageMaker AI endpoints, Amazon Bedrock APIs, and containerized model servers.
Solution overview
Many AI systems face limitations with single-model approaches that can’t adapt to diverse enterprise needs. These systems often have rigid deployment options, inconsistent APIs across different AI services, and lack multi-model deployment options for optimal model selection.
This solution demonstrates how organizations can build AI systems that address these limitations. The solution allows deployment selection based on operational needs and provides consistent request and response formats across different AI backends and deployment methods. It generates contextual responses through medical knowledge integration and vector search, supporting deployment from development to production environments through containerized architecture.
This healthcare use case illustrates how the AI agent can process complex medical queries for six medications with clinical decision support and AWS security and compliance capabilities.
Architecture
The solution consists of the following services and features to deliver the agentic AI capabilities:
- SageMaker AI with BioM-ELECTRA-Large-SQuAD2 model for specialized medical queries and managed auto-scaling.
- Amazon Bedrock with Claude 3.5 Sonnet V2 by Anthropic for complex reasoning and foundation model access.
- Amazon OpenSearch Service for vector similarity matching and contextual knowledge retrieval with medical knowledge indexing.
- Amazon Elastic Container Service (Amazon ECS), with AWS Fargate, for serverless container orchestration and scalable deployment of the Python application that uses the smolagents library.
- AWS Identity and Access Management (IAM) for security and access control.
- Containerized model server with BioM-ELECTRA-Large-SQuAD2 for self-hosted model deployment.
The following diagram illustrates the solution architecture.
The architecture is a complete integration of the Hugging Face smolagents framework with AWS services. A client web interface connects to a healthcare agent container that orchestrates across three model backends: SageMaker AI with BioM-ELECTRA, Amazon Bedrock with Claude 3.5 Sonnet V2, and a containerized model server with BioM-ELECTRA. The solution includes a vector store powered by OpenSearch Service and a security layer with data encryption at rest and in transit. The security layer also handles IAM access control and authentication, and any medical disclaimers for regulatory compliance.
This solution supports deployment options through smolagents with each backend optimized for different scenarios:
- SageMaker AI for managed endpoints with auto-scaling and production workloads using Hugging Face Hub models.
- Amazon Bedrock for serverless access to foundation models and complex reasoning through AWS APIs.
- A containerized model server for self-hosted model deployment and tool integration from Hugging Face Hub.
The three backends implement Hugging Face Messages API compatibility, confirming consistent request and response formats regardless of the selected model service. Users select the appropriate backend based on their requirements—the solution provides deployment options rather than automatic routing.
The complete implementation is available in the sample-healthcare-agent-with-smolagents-on-aws GitHub repository.
Key benefits
The integration of Hugging Face smolagents with AWS managed services offers significant advantages for enterprise agentic AI deployments.
Deployment choice
Organizations can choose the optimal deployment for each use case: Amazon Bedrock for serverless access to foundation models and self-hosted containerized deployment for custom tool integration or SageMaker AI for specialized domain models. These options help to match specific workload requirements, rather than a one-size-fits-all approach.
Multi-model deployment options
Organizations can optimize their infrastructure choices without changing their agent logic. You can switch between containerized model server, SageMaker AI, and Amazon Bedrock without modifying your application code. This provides deployment options, while maintaining consistent agent behavior.
Code generation capabilities
The CodeAgent approach of smolagents streamlines multi-step operations through direct Python code generation and processing. The following comparison illustrates the multi-step operations of smolagents:
Multi-step JSON-based approach:
{
"action": "search",
"parameters": {"query": "drug interactions"},
"next_action": {
"action": "filter",
"parameters": {"criteria": "severity > moderate"}
}
}smolagents CodeAgent:
# Search and filter in single code block
results = search_tool("drug interactions")
filtered_results = [r for r in results if r.severity > "moderate"]
final_answer(f"Found {len(filtered_results)} severe interactions: {filtered_results}")The smolagents CodeAgent supports single code blocks to handle multi-step operations, reducing large language model (LLM) calls while streamlining agent development. It provides full control of agent logic across AWS service deployments.
Scalable architecture
By deploying the application on AWS, you gain access to security features and auto-scaling capabilities that help you meet organizational security requirements and maintain regulatory compliance. Running containerized workloads with Amazon ECS and Fargate helps you achieve reliable operations and optimize costs through automated resource scaling.
Let’s walk through implementing this solution.
Prerequisites
Before you deploy the solution, you need the following:
- An AWS account with appropriate permissions to create IAM roles, Amazon ECS clusters, and Amazon OpenSearch Service domains.
- AWS Command Line Interface (AWS CLI) version 2.0 or later installed and configured.
- Python 3.10 or later for running deployment scripts.
- Docker installed and running (required for production environments to provide secure code execution sandbox).
- Access to Amazon Bedrock, SageMaker AI, and OpenSearch Service in your AWS Region with appropriate IAM permissions to create and manage resources.
- For this implementation, we’re using Python 3.10+, smolagents framework, transformers 4.28.1+, PyTorch 2.0.0+, and boto3.
Run the following command to install the required Python packages:
pip install -r healthcare_ai_agent/phase_00_installation/requirements.txtConfigure environment variables
Set the required environment variables for your AWS Region and resource names before deploying the infrastructure.
- Set the following environment variables in your terminal:
export AWS_REGION=us-west-2
export SAGEMAKER_ENDPOINT_NAME=healthcare-qa-endpoint-1
export OPENSEARCH_DOMAIN=healthcare-vector-store
export OPENSEARCH_INDEX=medical-knowledge
export BEDROCK_MODEL_ID=anthropic.claude-3-5-sonnet-20241022-v2:0
export SAGEMAKER_MODEL_ID=sultan/BioM-ELECTRA-Large-SQuAD2
export CONTAINERIZED_MODEL_ID=sultan/BioM-ELECTRA-Large-SQuAD2- Verify the variables are set:
echo $AWS_REGION
echo $SAGEMAKER_ENDPOINT_NAMEThese environment variables are used throughout the deployment and testing processes. Verify that they’re set before proceeding to the next step.
Set up AWS infrastructure
Start by creating the foundational AWS infrastructure components using the SampleAWSInfrastructureManager class from the Smolagents_SageMaker_Bedrock_Opensearch.py implementation.
Deploy complete infrastructure (automated approach)
For automated deployment of the AWS infrastructure components, you can use the enhanced main function.
- Start the enhanced main function:
from Smolagents_SageMaker_Bedrock_Opensearch import enhanced_main
enhanced_main()
# Select option 1 for complete AWS infrastructure deployment- The deployment automatically creates an Amazon ECS cluster, IAM roles, and an OpenSearch Service domain.
- Wait for deployment to complete (approximately 15–20 minutes).
Create individual AWS components (alternative approach)
If you prefer to create components individually, you can set up an OpenSearch Service domain for vector-enhanced knowledge retrieval and an Amazon ECS cluster for containerized deployment.
Both the OpenSearch Service domain and Amazon ECS cluster are automatically created as part of the complete AWS infrastructure deployment (Option 1 in enhanced_main). If you’ve already deployed the complete infrastructure, both components are ready and you can skip to the Deploy the Amazon SageMaker AI endpoint section.
Deploy the Amazon SageMaker AI endpoint
Deploy the BioM-ELECTRA-Large-SQuAD2 model to SageMaker AI for specialized medical query processing. An automated method (for deployment through the enhanced main) and a manual method (for deployment through the SageMaker AI endpoint) are provided.
To deploy using enhanced main (automated method)
from Smolagents_SageMaker_Bedrock_Opensearch import enhanced_main
# Start the enhanced main function
enhanced_main()
# Select option 2 for SageMaker endpoint deploymentTo deploy the SageMaker AI endpoint (manual method)
- Verify your SageMaker environment variables are set (from the Configure environment variables section):
echo $SAGEMAKER_MODEL_ID
echo $SAGEMAKER_ENDPOINT_NAME- Run the Amazon SageMaker deployment function:
from Smolagents_SageMaker_Bedrock_Opensearch import deploy_sagemaker_endpoint_safe
endpoint_name = deploy_sagemaker_endpoint_safe()- The deployment uses the HuggingFaceModel with transformers 4.28.1, PyTorch 2.0.0, and ml.m5.xlarge instance type.
- Wait for the endpoint deployment to complete (approximately 5–10 minutes).
- Verify the endpoint deployment:
# Verify endpoint status
print(f"✅ Endpoint deployed: {endpoint_name}")- The endpoint is configured for question-answering tasks with MAX_LENGTH=512 and TEMPERATURE=0.1.
Configure the multi-model backends
Configure the two additional backend options using the SampleTripleHealthcareAgent class for model selection based on operational needs.
Option 1 – Set up Amazon Bedrock access
Configure access to Amazon Bedrock for foundation model integration with Claude 3.5 Sonnet V2.
- Verify your Amazon Bedrock model configuration is set (from the Configure environment variables section):
echo $BEDROCK_MODEL_ID- Access to Claude 3.5 Sonnet V2 is automatically available for your AWS account.
- You can verify model availability in the Amazon Bedrock console under Model catalog.
Initialize the medical knowledge base
Set up the medical knowledge database with six medications and vector embeddings in OpenSearch Service. You can use the enhanced_main() function, which provides an interactive menu for deployment tasks, or initialize manually using the SampleOpenSearchManager class.
To initialize using enhanced main (Automated method)
from Smolagents_SageMaker_Bedrock_Opensearch import enhanced_main
# Start the enhanced main function
enhanced_main()
# Select option 4 for OpenSearch initialization and medical knowledge indexingTo initialize the medical knowledge base (Manual method)
- Initialize the SampleOpenSearchManager:
from Smolagents_SageMaker_Bedrock_Opensearch import enhanced_main
# Start the enhanced main function
enhanced_main()
# Select option 4 for OpenSearch initialization and medical knowledge indexing- The system creates the medical knowledge index with mappings for drug_name, content, and content_type fields.
- Medical knowledge for Metformin, Lisinopril, Atorvastatin, Amlodipine, Omeprazole, and Simvastatin is automatically indexed.
- Each medication includes side effects, monitoring requirements, and drug class information.
- The vector store supports similarity search with content type filtering for targeted queries.
- Verify the indexing completed successfully:
# Verify the indexing completed successfully
print("Medical knowledge base initialized with 6 medications")Option 2 – Deploy the containerized model server
After setting up the core infrastructure, deploy a containerized model server that provides self-hosted model deployment capabilities.
Deploy the containerized model server using the LocalContainerizedModelServer class with BioM-ELECTRA-Large-SQuAD2 for model deployment.
To deploy containers to Amazon ECS (automated method)
For automated deployment, use the containerized Amazon ECS deployment:
from Smolagents_SageMaker_Bedrock_Opensearch import enhanced_main
# Start the enhanced main function
enhanced_main()
# Select option 3 for ECS container deploymentTo deploy the containerized model server (manual method)
- Verify your containerized model configuration is set (from the Configure environment variables step):
echo $CONTAINERIZED_MODEL_ID- Initialize the containerized model server:
from Smolagents_SageMaker_Bedrock_Opensearch import LocalContainerizedModelServer
containerized_server = LocalContainerizedModelServer()
containerized_server.start_server()The containerized model server uses Docker sandboxing for secure code execution.
- Verify that the containerized model server is running:
print(f"✅ Containerized Model Server status: {containerized_server.get_status()}")The containerized model server includes
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み