Amazon SageMaker AI でエージェントがガイドするワークフローによるモデルカスタマイズの加速
Amazon SageMaker AI が、自然言語による使用ケース定義からモデルカスタマイズ、評価、デプロイまでを自動化する「エージェント型ワークフロー」および専用スキル機能を導入し、専門知識の壁を下げた。
キーポイント
エージェントによる自動ワークフローの実現
開発者が自然言語で要件を記述するだけで、データ準備から SFT/DPO/RLVR といった複雑な微調整手法の選択、評価、デプロイまで AI コーディングエージェントがシームレスに実行する。
専門知識を内包した「Agent Skills」の提供
AWS とデータサイエンスの深い知見をコード化した事前構築モジュール(Skills)が、SageMaker AI の API やベストプラクティスに基づき、各工程で正確なガイダンスと実行可能なノートブックを生成する。
Kiro による JupyterLab 統合開発環境
Amazon の AI ソフトウェア開発エージェント「Kiro」が SageMaker AI Studio の JupyterLab に統合され、ACP(Agent Code Platform)を通じてリアルタイムで開発を支援する。
カスタマイズ性とコスト削減効果
生成されたコードは完全編集可能で再利用可能なアーティファクトとなり、組織のガバナンス基準に合わせたスキルのカスタマイズも可能であるため、トークン使用量の削減と生産性向上を両立する。
計画フェーズでのスキル活性化と対話
コーディングエージェントは即座に実行せず、まずワークフローを生成する前に必要なスキル(例:プランニング、ファインチューン設定)を特定し、データ準備状況やユースケースについて質問して推奨事項を決定します。
データ分析に基づく最適なモデル選定
エージェントはデータ構造とタスク要件を分析し、高コストな試行錯誤を避けるために特定のユースケースに合わせたモデルや手法(例:医療推論にはQwen3-0.6B)を推奨します。
サーバーレストレーニングと統合モニタリング
SageMaker AI のサーバーレストレーニング機能を用いて、MLflow Apps を通じてトレーニングおよび検証メトリクスを追跡しながらモデルをカスタマイズし、Studio 上でジョブを監視できます。
影響分析・編集コメントを表示
影響分析
この発表は、LLM のカスタマイズにおける参入障壁を劇的に低下させ、専門的な微調整技術(SFT, DPO など)の習得コストを下げ、より多くの組織が独自データを活用したモデル開発を実現する契機となる。特に「Agent Skills」による標準化と自動化は、実験サイクルの短縮とトークンコストの削減に直結し、企業における AI 実装のスピードと効率性を根本から変える可能性を秘めている。
編集コメント
従来の複雑な微調整プロセスを「自然言語」で扱える点に大きな革新性があり、AI エンジニアリングの民主化を加速させる重要な一歩です。ただし、生成されるコードの品質保証や、高度なカスタマイズ要件への対応については、実際の導入事例での検証が今後の課題となります。
すべての組織は同じ基盤モデルへのアクセス権を持っています。真の競争優位性は、独自のデータとドメイン専門知識を用いてそれらをカスタマイズすることから生まれます。しかし、そこへ到達するのは複雑で、経験豊富なチームであっても困難を伴います。これには、教師あり微調整(SFT)、直接選好最適化(DPO)、強化学習検証可能報酬(RLVR)といった微調整技術の習得、断片化した API やモデル固有のデータ形式の扱い、厳格な評価設計、そして数ヶ月にわたる実験サイクルの管理が必要です。
Amazon SageMaker AI は今、この状況を変えるエージェント型体験を提供しています。開発者は自然言語でユースケースを記述するだけで、AI コーディングエージェントがユースケースの定義やデータ準備から、技術選択、評価、デプロイに至るまでの全工程を効率化します。専用設計のエージェントスキルは、特定のユースケースに適用される微調整に関する専門知識、必要な形式へのデータ変換、LLM-as-a-Judge メトリクスを用いた品質評価、Amazon Bedrock や SageMaker AI エンドポイントへの柔軟なデプロイといった分野で特化した支援を提供します。モデルカスタマイズ用のエージェントスキルは生産性を向上させるだけでなく、トークン使用量も削減します。生成されたコードはすべて完全に変更可能であり、既存のワークフローにシームレスに統合される再利用可能なアーティファクトを生成します。
この体験を真に強力なものにしているのは、モデルカスタマイズ用のエージェントスキルです。これらは事前構築されたモジュール型の指示セットであり、カスタマイズのライフサイクル全体にわたる AWS およびデータサイエンスの深い専門知識をエンコードしています。ユースケースを記述すると、AI コーディングエージェントが関連するスキルをアクティブ化し、データの準備と検証、技術の選択、ハイパーパラメータ設定、モデル評価、そしてデプロイメントへと導きます。スキルは、SageMaker AI API や ML ワークフロー、ベストプラクティス、一般的なパターンに関する専門知識を提供し、コーディングエージェントがより正確で SageMaker AI に特化したガイダンスを行い、各ステップで実行可能なノートブックを生成できるようにします。スキルは完全にカスタマイズ可能であるため、チームのワークフロー、ガバナンス基準、およびツールリングの好みに合わせて修正することができ、汎用型コードアシスタントでは一般的に課題となる再現性のある組織レベルのベストプラクティスを実現できます。
Amazon Kiro in SageMaker AI Studio JupyterLab
SageMaker AI の JupyterLab には、ACP(Agent Communication Protocol)を介した統合型エージェント開発環境のサポートが含まれています。デフォルトでは、Amazon の AI ソフトウェア開発エージェントである Kiro が チャットパネルに事前設定されています。これにより、JupyterLab 環境内で直接、AI によるコード補完、デバッグ支援、対話型コーディングサポートが提供されます。SageMaker AI JupyterLab でコーディングエージェントを使用すると、関連する SageMaker AI モデルカスタマイズ用スキル(Skills)が自動的にエージェントのコンテキストに読み込まれます。
さらに、Claude Code など、お好みの他の ACP 互換 コーディングエージェントを設定することも可能です。これにより、ワークフローに最も適したツールで作業する柔軟性が得られます。SageMaker AI JupyterLab 内で使用する場合、ACP 互換のエージェントも同様に SageMaker AI スキル統合の恩恵を受けることができます。この例では JupyterLab との統合を示していますが、JupyterLab 外でもご自身の IDE へのリモートアクセス を利用することもできます。
前提条件
本チュートリアルを開始する前に、以下の前提条件を満たしている必要があります:
- AWS アカウント
- SageMaker AI ドメインへのアクセス権限、またはドメインの作成機能。SageMaker AI ドメインをお持ちでない場合は、クイックセットアップまたは手動セットアップオプションを使用して作成できます。
- 必要な権限を持つ AWS IAM ロール
- Amazon Simple Storage Service (Amazon S3) バケット
- SageMakerAI Studio JupyterLab コンピューティングスペースへのアクセス権限、またはその作成機能。新機能を使用するためにインスタンスタイプの最小要件はありません。
- 本稿執筆時点では、SageMakerAI Studio JupyterLab で SageMaker AI Distribution イメージバージョン 4.1 以上が必要です。
- ドメインの実行ロールに「AmazonSageMakerFullAccess」マネージドポリシーを付与または確認してください。Lambda、S3、Bedrock へのアクセス用の追加インラインポリシーも、同じ実行ロールに付与してください。
- SageMakerAI Studio の実行ロールの信頼ポリシーには、以下の 3 つのサービスがロールを引き受けることを許可する必要があります:sagemaker.amazonaws.com、lambda.amazonaws.com、bedrock.amazonaws.com。
スキル概要
SageMaker AI エージェントスキルは、Agent Skills オープンフォーマット に準拠して構築されています。エージェント誘導型モデルカスタマイズワークフローは、カスタマイズの全ライフサイクルをカバーする 9 つのモジュラースキルによって支えられています:
スキル名
フェーズ
説明
ユースケース仕様書作成 (Use Case Specification)
設定 (Configuration)
ビジネス課題、ユーザー、成功基準を定義するための構造化された発見
計画
発見
ユースケースに合わせた動的かつ多段階のカスタマイズプランを生成します
微調整設定
構成、トレーニング
SageMaker AI Hub からベースモデルを選択し、推奨手法(SFT、DPO、または RLVR)を提案します
データセット評価
評価、トレーニング
トレーニング前にデータセットの形式とスキーマを検証します
データセット変換
データエンジニアリング
ML データフォーマット間の変換(OpenAI チャット、SageMaker AI、Hugging Face、Amazon Nova)を行います
微調整
トレーニング
SageMaker AI サーバーレス微調整用のトレーニングノートブックを生成します
モデル評価
評価
組み込みおよびカスタムメトリクスを使用した LLM-as-Judge(LLM を裁判官として用いた)評価を設定します
モデル展開
デプロイメント
展開パス(SageMaker AI エンドポイントまたは Bedrock)を決定し、コードを生成します
コーディングエージェント(Kiro、Claude Code、Cursor など)が会話型インターフェースを提供し、SageMaker AI スキルがワークフローをオーケストレーションします。コーディングエージェントと対話すると、関連するスキルがアクティブ化されます。これにより、AWS が提供する MCP サーバーを通じて SageMaker AI API の呼び出し、S3 データソースへのアクセス、モデルレジストリ との対話が可能になります。各ステップを既存の ML パイプラインに実行する Jupyter ノートブックが自動的に生成されます。
サポートされているファインチューニング技術
現在、モデルカスタマイズ機能は 3 つのファインチューニング手法をサポートしており、ユースケースに基づいて計画フェーズで最適な手法を推奨します。
手法
説明
最も適した用途
SFT (Supervised Fine-Tuning)
入力/出力ペアを用いたトレーニング
タスク固有の動作:指示の遵守、フォーマット準拠、ドメイン適応型レスポンス
DPO (Direct Preference Optimization)
好ましい出力と拒否された出力との比較によるトレーニング
トーン、スタイル、主観的嗜好を人間の判断に一致させるように調整
RLVR (Reinforcement Learning with Verifiable Rewards)
コードベースの報酬関数を用いたトレーニング
正しさをプログラム的に検証できるタスク
ソリューションの実装
本ソリューションでは、FreedomIntelligence/medical-o1-reasoning-SFT データセット上で小型言語モデル(SLM)をファインチューニングし、診断を提供する前に医療ケースを段階的に検討する臨床推論モデルを構築します。これにより、汎用モデルをドメイン固有の推論タスクに特化させるためにファインチューニングがどのように活用されるかが示されます。異なるユースケースを試したい場合は、SageMaker AI は SFT(Supervised Fine-Tuning)、DPO(Direct Preference Optimization)、RLVR などの技術にわたる サンプルデータセットのライブラリ を提供しており、これをスタートポイントとして利用できます。
入門ガイド
- JupyterLab を備えた SageMaker AI Space を開くか作成する
- SageMaker AI Studio に移動する
- 左側のナビゲーションパネルから「Spaces」へ進むか、モデルハブから「Customize with agent」をクリックする
- 次のいずれかを実行:
「Create Space」をクリックしてアプリケーションとして JupyterLab を選択する
- JupyterLab が含まれた既存の Space を開く
本記事では、まず Kiro の使用を開始し、その後コーディングエージェントとして Claude Code に切り替えます。Kiro を引き続き使用したい場合は計画フェーズセクションへ移動するか、JupyterLab での Claude Code の使用方法を確認するには次のセクションへ進んでください。
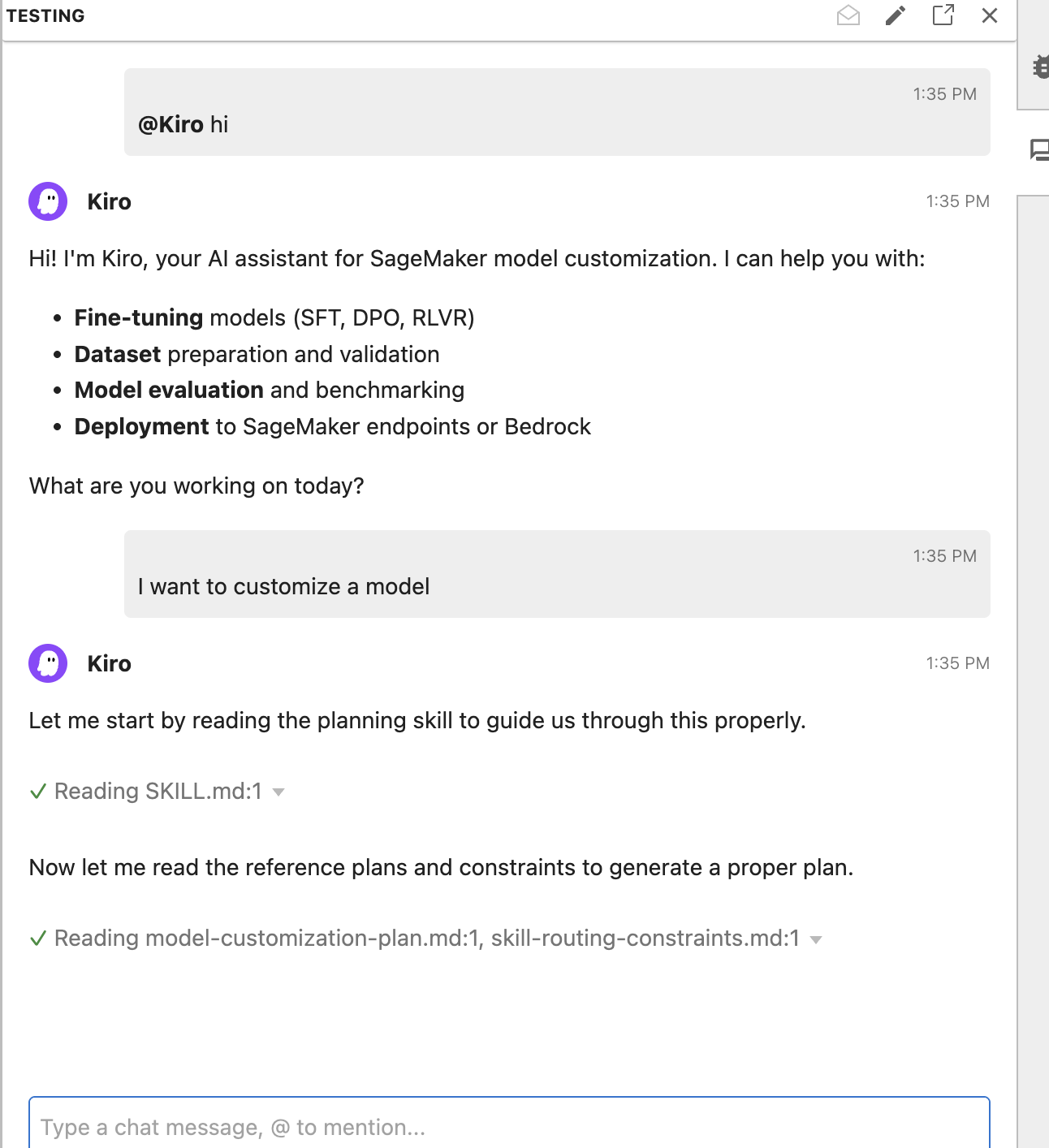
チャットパネルで Kiro の使用開始:
Kiro を使用する前に認証が必要です。チャットパネルが認証プロセスを案内します。
- JupyterLab で、右側のサイドバーにあるチャットアイコンをクリックしてチャットパネルを開きます
- @ と入力すると、利用可能なエージェントが表示されます
- エージェントドロップダウンから@Kiro を選択します。質問をしたり、コードのサポートを求めたりしてください。
スペースで Kiro を初めて使用する際は、ログインを求められることがあります。ログインするには、チャットに表示される手順に従うか、以下のリンクに従ってください:
- JupyterLab で新しいターミナルを開きます: File > New > Terminal
- 以下のコマンドを実行します kiro-cli login --use-device-flow
ターミナルで 3 つのログインオプションのいずれかを選択してください:
- Builder ID を使用して無料で利用
- Google または GitHub を使用して無料で利用
- Pro ライセンスを使用して利用
- プロンプトを入力: "I want to customize a model"
JupyterLab での Claude Code の設定
SageMaker AI Studio では、Agent Control Protocol (ACP: エージェント制御プロトコル) を使用して追加のコーディングエージェントを実装できます。ACP に対応する例として挙げられるエージェントは以下の通りです:
- Claude (via claude-agent-acp)
- OpenCode (via opencode CLI >= 1.0.0)
- Gemini (via gemini CLI >= 0.34.0)
- Codex (via codex-acp)
インストール手順の詳細については、JupyterLab ユーザーガイド をご覧ください。
Claude Code を使用するには:
- SageMaker AI Studio の JupyterLab ターミナルで CLI ツールをインストールします:npm install -g @zed-industries/claude-agent-acp
restart-jupyter-serverコマンドを実行するか、Studio UI を介してスペースを再起動してください。なお、保存されていない作業やメモリ上の状態(アクティブなカーネルなど)はすべて失われます。- 各エージェント固有の認証プロセスに従って認証を行います。
- JupyterLab のチャットパネルにあるペルソナドロップダウンからエージェントを選択します(@Claude)
Claude Code は、Amazon SageMaker AI Studio 上で Amazon Bedrock を介して Claude Code を設定するものを含む、ほとんどの Anthropic サブスクリプションで使用可能です。Claude Code を Amazon Bedrock を通じて Claude に使用するように設定するには、まず Claude コードガイドの 前提条件 を参照し、Bedrock モデルへのアクセスを有効化するとともに、実行ロールに対して InvokeModel および bedrock:InvokeModelWithResponseStream の権限を付与してください。その後、以下のファイルを作成して Claude Code が Bedrock を使用するように設定します。
~/.claude/settings.json:
{
"env": {
"CLAUDE_CODE_USE_BEDROCK": "1"
}
}
プランニングフェーズ
ユーザーからのプロンプトを受け取ると、コーディングエージェントはすぐにタスクの実行を開始するわけではありません。まずプランニングフェーズに入り、タスクを完了するために必要なスキルを特定してアクティブ化します。この過程で、エージェントはユーザーがレビューし修正できるワークフローを生成します。初期のプロンプトから、エージェントは2 つの関連するスキルドメインを認識し、全体のワークフローを構造化するための「プランニングスキル」と、トレーニングジョブを設定するためのfinetuning-setupスキル(微調整設定)の両方をアクティブ化します。コードを生成する前に、データセットの準備状況やユースケースの詳細について targeted な質問を行い、推奨される技術と評価指標の根拠とします。
SageMaker AI でのファインチューニング
複数のモデルファミリーとファインチューニング手法が利用可能であるため、特定のユースケースに最適なアプローチを選択することは難しい場合があります。エージェントはデータセットの構造とタスク要件を分析し、カスタマイズされたモデルと手法の推奨を提供することで、高額な試行錯誤サイクルを回避するお手伝いをします。SageMaker AI は、Amazon Nova、GPT-OSS、Llama、Qwen、DeepSeek の各モデルファミリーに対してサーバーレスのカスタマイズをサポートしています。今回のユースケースでは、医療推論などのドメイン固有タスクに十分でありながら、トレーニングとデプロイのコスト効果が高いことから、Qwen3-0.6B を選択しました。
- チャットパネルでエージェントにプロンプトを入力します:「医療ケースを段階的に検討した後に診断を提供する、臨床推論用のモデルをファインチューニングしたいです」。
- プランを確認し、エージェントのフォローアップ質問に回答します。エージェントは、統合された SageMaker AI MLflow アプリを通じてトレーニングおよび検証メトリクスを追跡する SageMaker AI サーバーレストレーニングジョブを使用するトレーニングノートブックを生成します。
- ノートブックを開き、コードを検証してノートブックセルを実行し、トレーニングジョブを送信します。
- SageMaker AI Studio 内でジョブの監視を行います。
モデルの損失はトレーニング中に着実に減少し、段階的な臨床推論を提供する能力を正しく学習したことを示します。
原文を表示
Every organization has access to the same foundation models. The real competitive advantage comes from customizing them with your proprietary data and domain expertise. But getting there is complex, even for experienced teams. It requires mastering fine-tuning techniques like Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), and Reinforcement Learning Verifiable Rewards (RLVR), navigating fragmented APIs and model-specific data formats, designing rigorous evaluations, and managing months-long experiment cycles.
Amazon SageMaker AI now offers an agentic experience that changes this. Developers describe their use case using natural language, and the AI coding agent streamlines the entire journey, from use case definition and data preparation through technique selection, evaluation, and deployment. Purpose-built agent skills deliver specialized expertise on fine-tuning applied to your specific use case, data transformation to required formats, quality evaluation using LLM-as-a-Judge metrics, and flexible deployment to Amazon Bedrock or SageMaker AI endpoints. Agent skills for model customization not only boost productivity but also decrease token usage. All generated code is fully editable, producing reusable artifacts that integrate seamlessly into existing workflows.
What makes this experience truly powerful is agent Skills for model customization. They are pre-built, modular instruction sets that encode deep AWS and data science expertise across the entire customization lifecycle. When you describe your use case, the AI coding agent activates the relevant skills, guiding it through data preparation and validation, technique selection, hyperparameter configuration, model evaluation, and deployment. Skills provide specialized knowledge about SageMaker AI APIs, ML workflows, best practices, and common patterns, enabling your coding agent to provide more accurate, SageMaker AI-specific guidance, generating ready-to-run notebooks at each step. Skills are fully customizable, so you can modify them to match your team’s workflows, governance standards, and tooling preferences, enabling reproducible organizational best practices, a common challenge with general-purpose coding assistants.
Amazon Kiro in SageMaker AI Studio JupyterLab
JupyterLab in SageMaker AI includes an integrated agentic development environment support through ACP. By default, Kiro, Amazon’s AI software development agent, is pre-configured in the chat panel, providing AI-powered code completion, debugging assistance, and interactive coding support directly within your JupyterLab environment. When you use coding agents in SageMaker AI JupyterLab, the space automatically loads relevant SageMaker AI model customization Skills into your agent’s context.
Additionally, you can configure other Agent Communication Protocol(ACP) compatible coding agents of your choice, such as Claude Code, giving you flexibility to work with the tools that best fit your workflow. ACP-compatible agents can benefit from the same SageMaker AI Skills integration when used within SageMaker AI JupyterLab. While this example shows the integration with JupyterLab, you can also use remote access to your own IDE outside of JupyterLab.
Prerequisites
Before starting this tutorial, you must have the following prerequisites:
- An AWS account
- The ability to access or create a SageMaker AI domain. If you don’t have a SageMaker AI domain, you can create one using the quick setup or manual setup options
- An AWS IAM role with the required permissions
- An Amazon Simple Storage Service (Amazon S3) bucket
- Access to or can create a SageMakerAI Studio JupyterLab compute space. There is no minimum instance type requirement to use the new features.
- As of this publication, SageMaker AI Distribution image version 4.1 or higher is required on your SageMakerAI Studio JupyterLab.
- Verify or Attach AmazonSageMakerFullAccess managed policy to your domain’s execution role. Attach the additional inline policy for Lambda, S3 and Bedrock access to the same execution role
- Your SageMakerAI Studio execution role’s trust policy must allow these three services to assume the role: sagemaker.amazonaws.com, lambda.amazonaws.com, bedrock.amazonaws.com.
Skills overview
The SageMaker AI agent skills are built conforming with the Agent Skills open format. The agent-guided model customization workflows are powered by nine modular skills that cover the full customization lifecycle:
Skill Name
Phase
Description
Use Case Specification
Configuration
Structured discovery to define business problem, users, and success criteria
Planning
Discovery
Generates a dynamic, multi-step customization plan tailored to your use case
Fine-tuning Setup
Configuration, Training
Selects base model from SageMaker AI Hub and recommends technique (SFT, DPO, or RLVR)
Dataset Evaluation
Evaluation, Training
Validates dataset format and schema before training
Dataset Transformation
Data Engineering
Converts between ML data formats (OpenAI chat, SageMaker AI, Hugging Face, Amazon Nova)
Fine-tuning
Training
Generates training notebooks for SageMaker AI serverless fine-tuning
Model Evaluation
Evaluation
Configures LLM-as-Judge evaluation with built-in and custom metrics
Model Deployment
Deployment
Determines deployment pathway (SageMaker AI endpoint or Bedrock) and generates code
The coding agent (Kiro, Claude Code, Cursor, etc.) provides the conversational interface while the SageMaker AI Skills orchestrate the workflow. When you interact with your coding agent, it activates the relevant skills. This allows you to call SageMaker AI APIs, access S3 data sources, and interact with model registries through AWS-provided MCP servers. Jupyter notebooks are generated for you that execute each step of the process into existing ML pipelines.
Supported Fine-Tuning Techniques
The model customization skills currently support three fine-tuning techniques and recommend the right one during the planning phase based on your use case.
Technique
Description
Best For
SFT (Supervised Fine-Tuning)
Trains on input/output pairs
Task-specific behavior: instruction following, format compliance, domain-adapted responses
DPO (Direct Preference Optimization)
Trains on preferred vs. rejected outputs
Aligning tone, style, and subjective preferences to match human judgement
RLVR (Reinforcement Learning with Verifiable Rewards)
Trains using code-based reward functions
Tasks where correctness can be programmatically verified
Solution implementation
For this solution, you’ll fine-tune a small language model (SLM) on the FreedomIntelligence/medical-o1-reasoning-SFT dataset to build a clinical reasoning model that walks through medical cases step-by-step before providing a diagnosis. This demonstrates how fine-tuning can specialize a general-purpose model for domain-specific reasoning tasks. If you’d like to try a different use case, SageMaker AI provides a library of sample datasets across techniques like SFT, DPO, and RLVR that you can use as a starting point.
Getting started
- Open or Create a SageMaker AI Space with JupyterLab
- Navigate to SageMaker AI Studio
- Go to Spaces in the left navigation panel or click “Customize with agent” from the model hub
- Either:
Click Create Space and select JupyterLab as your application
- Open an existing Space that includes JupyterLab
In this post, we’ll start with using Kiro and switch to Claude Code as our coding agent. To keep using Kiro, move to the Planning Phase section, or move to the next section to see how to use Claude Code in JupyterLab.
Start Using Kiro in the Chat Panel:
Kiro requires authentication before you can use it. The chat panel will guide you through the authentication process.
- In JupyterLab, open the chat panel by clicking the chat icon in the right sidebar
- Type @ to see your available agents
- Select @Kiro from the agent dropdown. Start asking questions or requesting code assistance.
The first time you use Kiro in a space, it will ask you to login. To login, follow the instructions provided by the chat, or follow here:
- In JupyterLab, open a new terminal: File > New > Terminal
- Run the following command kiro-cli login --use-device-flow
Select one of the 3 login options in the terminal:
- Use for Free with Builder ID
- Use for Free with Google or GitHub
- Use with Pro license
- Enter a prompt: “I want to customize a model”
Configuring Claude Code in JupyterLab
SageMaker AI Studio supports implementing additional coding agents using Agent Control Protocol (ACP). Example agents that support ACP include:
- Claude (via claude-agent-acp)
- OpenCode (via opencode CLI >= 1.0.0)
- Gemini (via gemini CLI >= 0.34.0)
- Codex (via codex-acp)
View the JupyterLab user guide for more information on installation steps.
To use Claude Code:
- Install the CLI tool in your SageMaker AI Studio JupyterLab terminal: npm install -g @zed-industries/claude-agent-acp
- Restart the space by running the command restart-jupyter-server or by restarting the space via the Studio UI. Please note, this will result in any unsaved work or in memory state (like active kernels) being lost.
- Authenticate with the agent following its specific authentication process
- Select the agent from the persona dropdown in the JupyterLab chat panel (@Claude)
Claude Code can be used with most Anthropic subscriptions including configuring Claude Code with Amazon Bedrock on Amazon SageMaker AI Studio. To configure Claude Code to use Claude through Amazon Bedrock follow the prerequisites in the Claude code guide, enabling Bedrock model access and providing your execution role access to bedrock:InvokeModel and bedrock:InvokeModelWithResponseStream. Then, create the following file to configure Claude Code to use Bedrock.
~/.claude/settings.json:
{
"env": {
"CLAUDE_CODE_USE_BEDROCK": "1"
}
} Planning phase
Upon receiving the user prompt, the coding agent doesn’t immediately begin executing tasks. It enters a planning phase where it identifies and activates the skills necessary to complete the job. In the process, the agent generates a workflow which users can review and modify. From the initial prompt, the agent recognizes two relevant skill domains and activates both the planning skill for structuring the overall workflow and the finetuning-setup skill for configuring the training job. Before generating any code, the agent asks targeted questions about dataset readiness and use case details to inform its technique and evaluation metrics recommendations.
Fine-tune in SageMaker AI
With multiple model families and fine-tuning techniques available, choosing the right approach for your specific use case can be challenging. The agent analyzes your dataset structure and task requirements to provide tailored model and technique recommendations, helping you avoid costly trial-and-error cycles. SageMaker AI supports serverless customization across Amazon Nova, GPT-OSS, Llama, Qwen, and DeepSeek family of models. For this use case, we chose Qwen3-0.6B because it is cost-effective to train and deploy while being sufficient for domain-specific tasks like medical reasoning.
- In the chat panel, prompt the agent: “I want to fine-tune a model for clinical reasoning that walks through medical cases step-by-step before providing a diagnosis.”
- Confirm the plan and answer the agent’s follow-up questions. The agent generates a training notebook that will use a SageMaker AI serverless training job with training and validation metrics tracked through integrated SageMakerAI MLflow Apps.
- Open the notebook, verify the code and run the notebook cells to submit the training job.
- Monitor the job within your SageMaker AI Studio.
The model’s loss will show a steady decrease during training, showing it successfully learned to provide step-by-step clinical
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み