LLM をジャッジとする強化学習微調整
AWS は、LLM-as-a-judge を活用した強化学習微調整(RLAIF)の手法を解説し、Amazon Nova モデルを用いてより柔軟で説明可能なモデル整列を実現する具体的な実装ステップを提示している。
キーポイント
LLM-as-a-judge の優位性
従来のルールベースや数値スコアリングに比べ、正しさ・トーン・安全性など多角的な文脈を理解し、ラショナル(理由)を提供することでモデルの改善を加速させる。
評価アーキテクチャの選定
ルールベースの評価と好みに基づく評価(Preference-based judging)という 2 つの主要な評価モードがあり、用途に応じて選択する必要がある。
実装プロセスの具体化
評価関数の設計とデプロイにおける 6 つの重要なステップを提示し、Amazon Nova モデルを用いた効果的な適用方法を詳述している。
影響分析・編集コメントを表示
影響分析
この記事は、LLM の実用化におけるボトルネックである「報酬関数の設計コスト」と「ブラックボックス性」に対する解決策を提示しており、企業レベルでのモデル整列(Alignment)プロセスを効率化する標準的なアプローチを示唆しています。特に、説明可能性を伴う評価手法の重要性を強調することで、信頼性の高い AI システム構築に向けた技術的指針として業界に大きな影響を与える可能性があります。
編集コメント
マニュアルでの報酬設計の限界を打破し、LLM 自身による評価とフィードバックループを確立する手法は、実務におけるモデルチューニングの効率化に直結する重要な知見です。特に「説明可能性」を強調している点が、信頼性要件の高いビジネスユースケースにおいて非常に価値が高いと言えます。
Large language models (LLMs) now drive the most advanced conversational agents, creative tools, and decision-support systems. However, their raw output often contains inaccuracies, policy misalignments, or unhelpful phrasing—issues that undermine trust and limit real-world utility. *Reinforcement Fine‑Tuning (RFT)* has emerged as the preferred method to align these models efficiently, using *automated reward signals* to replace costly manual labeling.
At the heart of modern RFT is reward functions. They’re built for each domain through verifiable reward functions that can score LLM generations through a piece of code (Reinforcement Learning with Verifiable Rewards or RLVR) or with LLM-as-a-judge, where a separate language model evaluates candidate responses to guide alignment (Reinforcement Learning with AI Feedback or RLAIF). Both these methods provide scores to the RL algorithm to nudge the model to solve the problem at hand. In this post, we take a deeper look at how RLAIF or RL with LLM-as-a-judge works with Amazon Nova models effectively.
Why RFT with LLM‑as‑a-judge compared to generic RFT?
Reinforcement Fine-Tuning can use any reward signal, straightforward hand‑crafted rules (RLVR), or an LLM that evaluates model outputs (LLM-as-a-judge or RLAIF). RLAIF makes alignment far more flexible and powerful, especially when reward signals are vague and hard to craft manually. Unlike generic RFT rewards that rely on blunt numeric scoring like substring matching, an LLM judge reasons across multiple dimensions—correctness, tone, safety, relevance—providing context-aware feedback that captures subtleties and domain-specific nuances without task-specific retraining. Additionally, LLM judges offer built-in explainability through rationales (for example, “Response A cites peer-reviewed studies”), providing diagnostics that accelerate iteration, pinpoint failure modes directly, and reduce hidden misalignments, something static reward functions can’t do.
Implementing LLM-as-a-judge: Six critical steps
This section covers the key steps involved in designing and deploying LLM-as-a-judge reward functions.
Select the judge architecture
The first critical decision is selecting your judge architecture. LLM-as-a-judge offers two primary evaluation modes: *Rubric-based (point- based) judging* and *Preference-based judging*, each suited to different alignment scenarios.
Criteria
Rubric-based judging
Preference-based judging
Evaluation method
Assigns a numeric score to a single response using predefined criteria
Compares two candidate responses side-by-side and selects the superior one
Quality measurement
Absolute quality measurements
Relative quality through direct comparison
Preferred used when
Clear, quantifiable evaluation dimensions exist (accuracy, completeness, safety compliance)
Policy model should explore freely without reference data restrictions
Data requirements
Only requires careful prompt engineering to align the model to reward specifications
Requires at least one response sample for preference comparison
Generalizability
Better for out-of-distribution data, avoids data bias
Depends on quality of reference responses
Evaluation style
Mirrors absolute scoring systems
Mirrors natural human evaluation through comparison
Recommended starting point
Start here if preference data is unavailable and RLVR unsuitable
Use when comparative data is available
Define your evaluation criteria
After you’ve selected your judge type, articulate the specific dimensions that you want to improve. Clear evaluation criteria are the foundation of effective RLAIF training.
For Preference-based judges:
Write clear prompts explaining what makes one response better than another. Be explicit about quality preferences with concrete examples. Example: *“Prefer responses that cite authoritative sources, use accessible language, and directly address the user’s question.”*
For Rubric-based judges:
We recommend using Boolean (pass/fail) scoring for rubric-based judges. Boolean scoring is more reliable and reduces judge variability compared to fine-grained 1–10 scales. Define clear pass/fail criteria for each evaluation dimension with specific, observable characteristics.
Select and configure your judge model
Choose an LLM with sufficient reasoning capability to evaluate your target domain, configured through Amazon Bedrock and called using a reward AWS Lambda function. For common domains like math, coding, and conversational capabilities, smaller models can work well with careful prompt engineering.
Model tier
Preferred for
Cost
Reliability
Amazon Bedrock model
Large/Heavyweight
Complex reasoning, nuanced evaluation, multi-dimensional scoring
High
Very High
Amazon Nova Pro, Claude Opus, Claude Sonnet
Medium/Lightweight
General domains like math or coding, balanced cost-performance
Low-Medium
Moderate-High
Amazon Nova 2 Lite, Claude Haiku
Refine your judge model prompt
Your judge prompt is the foundation of alignment quality. Design it to produce structured, parseable outputs with clear scoring dimensions:
- Structured output format – Specify JSON or parseable format for straightforward extraction
- Clear scoring rules – Define exactly how each dimension should be calculated
- Edge case handling – Address ambiguous scenarios (for example, “If response is empty, assign score 0”)
- Desired behaviors – Explicitly state behaviors to encourage or discourage
Align judge criteria with production evaluation metrics
Your reward function should mirror the metrics that you will use to evaluate the final model in production. Align your reward function with production success criteria to enable models designed for the correct objectives.
Alignment workflow:
- Define production success criteria (for example, accuracy, safety) with acceptable thresholds
- Map each criterion to specific judge scoring dimensions
- Validate that judge scores correlate with your evaluation metrics
- Test the judge on representative samples and edge cases
Building a robust reward Lambda function
Production RFT systems process thousands of reward evaluations per training step. Build a resilient reward Lambda function to help provide training stability, efficient compute usage, and reliable model behavior. This section covers how to build a reward Lambda function that’s resilient, efficient, and production ready.
Composite reward score structuring
Don’t rely solely on LLM judges. Combine them with fast, deterministic reward components that catch obvious failures before expensive judge evals:
Core components
Component
Purpose
When to use
Format correctness
Verify JSON structure, required fields, schema compliance
Always – catches malformed outputs immediately. Cheap and instant feedback.
Length penalties
Discourage overly verbose or terse responses
When output length matters (for example, summaries)
Language consistency
Verify responses match input language
Critical for multilingual applications
Safety filters
Rule-based checks for prohibited content
Always – prevents unsafe content from reaching production
Infrastructure readiness
- Implement exponential backoff: Handles Amazon Bedrock API rate limits and transient failures gracefully
- Parallelization strategy: Use ThreadPoolExecutor or async patterns to parallelize judge calls across rollouts to reduce latency
- Avoid Lambda cold start delays: Set an appropriate Lambda timeout (15 minutes recommended) and provisioned concurrency (~100 for typical setups)
- Error handling: Add comprehensive error handling that returns neutral/noisy rewards (0.5) rather than failing the entire training step
Test your reward Lambda function for resilience
Validate judge consistency and calibration:
- Consistency: Test judge on the same samples multiple times to measure score variance (should be low for deterministic evaluation)
- Cross-judge comparison: Compare scores across different judge models to identify evaluation blind spots
- Human calibration: Periodically sample rollouts for human review to catch judge drift or systematic errors
- Regression testing: Create a “judge test suite” with known good/bad examples to regression test judge behavior
RFT with LLM-as-a-judge – Training workflow
The following diagram illustrates the complete end-to-end training process, from baseline evaluation through judge validation to production deployment. Each step builds upon the previous one, creating a resilient pipeline that balances alignment quality with computational efficiency while actively preventing reward hacking and supporting production-ready model behavior.
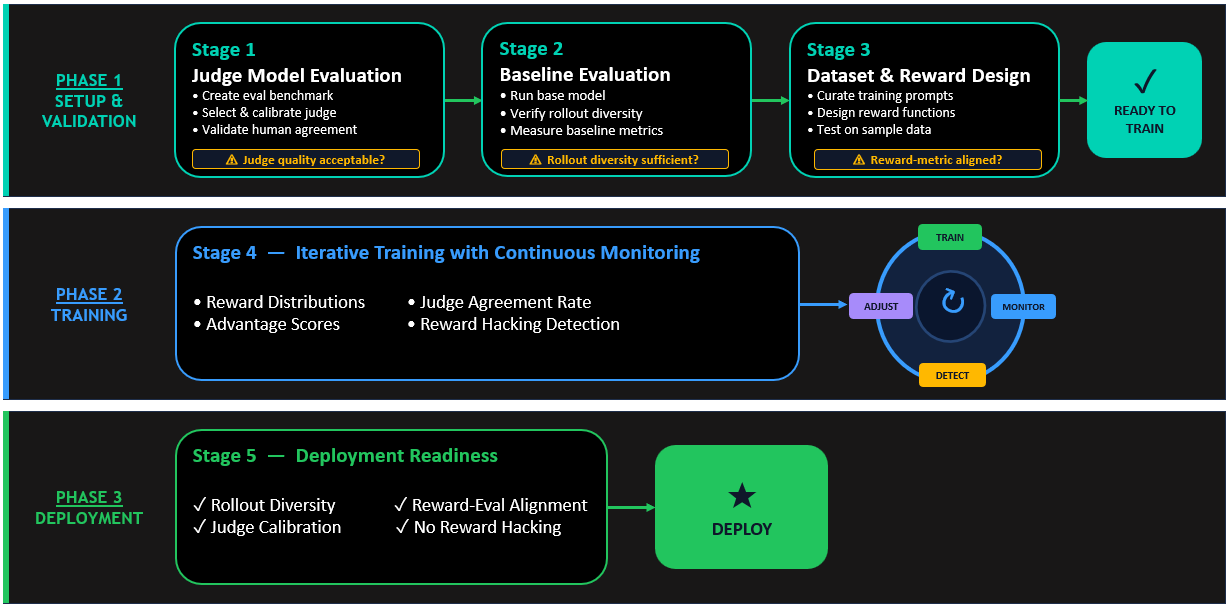
Real-world case study: Automating legal contract review
In this section, we refer to a real-world use case with a leading legal industry partner. The task is to generate comments on risks, assessments, and actions on legal documentation with respect to the policies and previous contracts as reference documents.
Challenge
Partner was interested in solving the problem of automating the process of reviewing, assessing, and flagging risks in legal contract documents. Specifically, they wanted to evaluate potential new contracts against internal guidelines and regulations, past contracts, and laws of the country pertaining to the contract.
Solution
We formulated this problem as one where we are providing a target document (the “contract” that needs evaluation), and a reference document (the grounding document and context) and expect the LLM to generate a JSON with multiple comments, comment types, and recommended actions to take based on the assessment. The original dataset available for this use case was relatively small that included complete contracts along with annotations and comments from legal experts. We used LLM as a judge using GPT OSS 120b model as the judge and a custom system prompt during RFT.
RFT workflow
In the following section we cover details of the key aspects in the RFT workflow for this use case.
Reward Lambda function for LLM-as-a-judge
The following code snippets present the key components of the reward Lambda function.
Note: name of Lambda function should have “SageMaker”, for example, "arn:aws:lambda:us-east-1:123456789012:function:MyRewardFunction**SageMaker**"
a) Start with defining a high-level objective
# Contract Review Evaluation - Unweighted Scoring
You are an expert contract reviewer evaluating AI-generated comments. Your PRIMARY objective is to assess how well each predicted comment identifies issues in the TargetDocument contract clauses and whether those issues are justified by the Reference guidelines.b) Define the evaluation approach
## Evaluation Approach
For each sample, you receive:
- **TargetDocument**: The contract text being reviewed (the document under evaluation)
- **Reference**: Reference guidelines/standards used for the review (the evaluation criteria)
- **Prediction**: One or more comments from the AI model
**Important**: The SystemPrompt shows what instructions the model received. Consider whether the model followed these instructions when evaluating the prediction quality.
**CRITICAL**: Each comment must identify a specific issue, gap, or concern IN THE TARGETDOCUMENT CONTRACT TEXT ITSELF. The comment's text_excerpt field should quote problematic contract language from the TargetDocument, NOT quote text from the Reference guidelines. The Reference justifies WHY the contract clause is problematic, but the issue must exist IN the contract.
Evaluate EACH predicted comment independently. Comments should flag problems in the contract clauses, not merely cite Reference requirements.c) Describe the scoring dimensions with clear specifications on how a particular score should be calculated
## Scoring Dimensions (Per Comment)
**EVALUATION ORDER**: Evaluate in this sequence: (1) TargetDocument_Grounding, (2) Reference_Consistency, (3) Actionability
### 1. TargetDocument_Grounding
**Evaluates**: (a) Whether text_excerpt quotes from TargetDocument contract text, and (b) Whether the comment is relevant to the quoted text_excerpt
**MANDATORY**: text_excerpt must quote from TargetDocument contract text. If text_excerpt quotes from Reference instead, score MUST be 1.
- **5**: text_excerpt correctly quotes TargetDocument contract text AND comment identifies a highly relevant, valid, and notable issue in that quoted text
- **4**: text_excerpt correctly quotes TargetDocument contract text AND comment identifies a valid and relevant issue in that quoted text
- **3**: text_excerpt correctly quotes TargetDocument contract text AND comment is somewhat relevant to that quoted text, but concern has moderate validity
- **2**: text_excerpt correctly quotes TargetDocument contract text BUT comment has weak relevance to that quoted text, or concern is questionable
- **1**: text_excerpt does NOT quote TargetDocument contract text (quotes Reference instead, or no actual quote), OR comment is irrelevant to the quoted text
### 2. Reference_Consistency
...
...d) Clearly define the final output format to parse
Scoring Calculation
Comment_Score = Simple average of the three dimensions:
- Comment_Score = (TargetDocument_Grounding + Reference_Consistency + Actionability) / 3
Aggregate_Score = Average of all Comment_Score values for the sample
Output Format
For each sample, evaluate ALL predicted comments and provide:
{ "comments": [
{ "comment_id": "...",
"TargetDocument_Grounding": {"score": X, "justification": "...", "supporting_evidence": "Verify text_excerpt quotes actual TargetDocument contract text and comment is relevant to it"},
"Reference_Consistency": {"score": X, "justification": "...", "supporting_reference": "Quote from Reference that justifies the concern OR explain meaningful reasoning"},
"Actionability": {"score": X, "justification": "Assess if action is clear, grounded in TargetDocument and Reference, and relevant to comment"},
"Comment_Score": X.XX
} ],
"Aggregat関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み