ADeLe: AIのタスク横断的性能予測と説明
Microsoft Researchらは、AIモデルとタスクを18の核心能力で評価し、新規タスクでの性能を約88%の精度で予測・説明可能にする評価手法「ADeLe」をNatureで発表した。
キーポイント
従来のベンチマークの限界を超える評価手法
従来のベンチマークは特定タスクでの性能を報告するが、基盤となる能力を説明せず、新規タスクでの予測が困難だった。ADeLeはこの課題を解決する。
能力スコアによるモデルとタスクの共通評価基盤
推論やドメイン知識など18の核心能力について、タスクは要求度(0-5)、モデルは能力プロファイルとしてスコア化し、両者を同じ尺度で比較可能にする。
高い予測精度と説明可能性の実現
能力スコアを用いて、GPT-4oやLlama-3.1などのモデルが未経験のタスクでどのように振る舞うかを約88%の精度で予測し、性能差の理由をタスク要求との関係で説明できる。
モデルの強み・弱みの構造化された可視化
多くのタスクでモデルを評価することで能力プロファイルを作成し、モデルが成功または失敗する可能性が高い領域を特定し、限界を明らかにする。
ADeLeによるベンチマーク評価の限界の可視化
多くの既存ベンチマークは測定対象能力を単離できておらず、難易度範囲も限定的で、不完全または誤解を招く評価結果をもたらしている。ADeLeはタスクに必要な能力をスコアリングすることでこれらの問題を明らかにする。
LLMの能力プロファイルとモデル間の差異
15のLLMを18の能力で評価した結果、モデルごとに強み・弱みが異なり、新しいモデルが全ての能力で一貫して優れているわけではない。知識系タスクはモデルサイズと学習に強く依存し、推論系モデルは論理・学習・抽象化・社会的推論で明確な向上を示す。
ADeLeの予測機能と実用性
ADeLeはモデルの能力プロファイルとタスク要求を比較することで、未知のタスクでも約88%の精度で成功を予測し、従来手法を上回る。これにより展開前の失敗予測が可能になり、AI評価の信頼性と予測可能性が向上する。
影響分析・編集コメントを表示
影響分析
この研究は、AIモデルの評価をブラックボックスから透明性の高い科学的プロセスへと転換する可能性を秘めており、モデル開発、ベンチマーク設計、実世界での適用判断に大きな影響を与える。業界全体の評価基準の標準化や、より目的に合ったモデル選択を促進する基盤技術となり得る。
編集コメント
Nature掲載という学術的裏付けがあり、従来のベンチマーク評価の限界を打破する画期的な手法として、AI業界の評価基準そのものに影響を与える可能性が高い。実用性と革新性のバランスが取れた重要な研究成果。

概要
AIベンチマークは特定のタスクでの性能を報告するが、基盤となる能力に関する洞察は限られている。ADeLeは18のコア能力にわたってタスクとモデルの両方をスコアリングすることでモデルを評価し、タスクの要求とモデルの能力を直接比較可能にする。
これらの能力スコアを用いることで、この手法はGPT-4oやLlama-3.1などのモデルを含め、新しいタスクでの性能を約88%の精度で予測する。
能力プロファイルを構築し、モデルが成功または失敗しやすい箇所を特定することで、タスク横断的な強みと限界を明らかにする。
結果をタスクの要求と結びつけることで、ADeLeは性能の差異を説明し、タスクの複雑さが増すにつれて性能がどのように変化するかを示す。
AIベンチマークは大規模言語モデル(LLM)が特定のタスクでどのように性能を発揮するかを報告するが、その性能を支える基盤となる能力についての洞察はほとんど提供しない。ベンチマークは失敗の理由を説明せず、新しいタスクでの結果を確実に予測することもできない。この問題に対処するため、マイクロソフトの研究者らはプリンストン大学およびバレンシア工科大学と共同で、ADeLe(新しいタブで開く)(AI Evaluation with Demand Levels)を提案した。これは、推論やドメイン知識などの幅広い能力セットを用いてモデルとタスクの両方を特徴付け、新しいタスクでの性能を予測し、モデルの特定の強みと弱みに関連付ける手法である。
Natureに掲載された論文「General Scales Unlock AI Evaluation with Explanatory and Predictive Power(新しいタブで開く)」において、研究チームはADeLeがどのように総合的なベンチマークスコアを超えるものであるかを説明している。評価を孤立したテストの集合として扱うのではなく、ADeLeは同一の能力スコアセットを用いてベンチマークとLLMの両方を表現する。これらのスコアは、モデルが未経験のタスクでどのように性能を発揮するかを推定するために使用できる。本研究はマイクロソフトのAccelerating Foundation Models Research(AFMR)助成プログラムによって支援された。
ADeLeベースの評価
ADeLeは、注意、推論、ドメイン知識などの18のコア能力にわたってタスクをスコアリングし、各能力がどの程度要求されるかに基づき、各タスクに0から5の値を割り当てる。例えば、基本的な算術問題は定量的推論(quantitative reasoning)のスコアが低くなるが、オリンピックレベルの証明問題ははるかに高いスコアとなる。
このような多数のタスクでモデルを評価することで、能力プロファイル(ability profile)が生成される。これは、モデルがどこで性能を発揮し、どこで破綻するかを示す構造化されたビューである。このプロファイルを新しいタスクの要求と比較することで、失敗につながる具体的なギャップを特定することが可能になる。このプロセスを図1に示す。
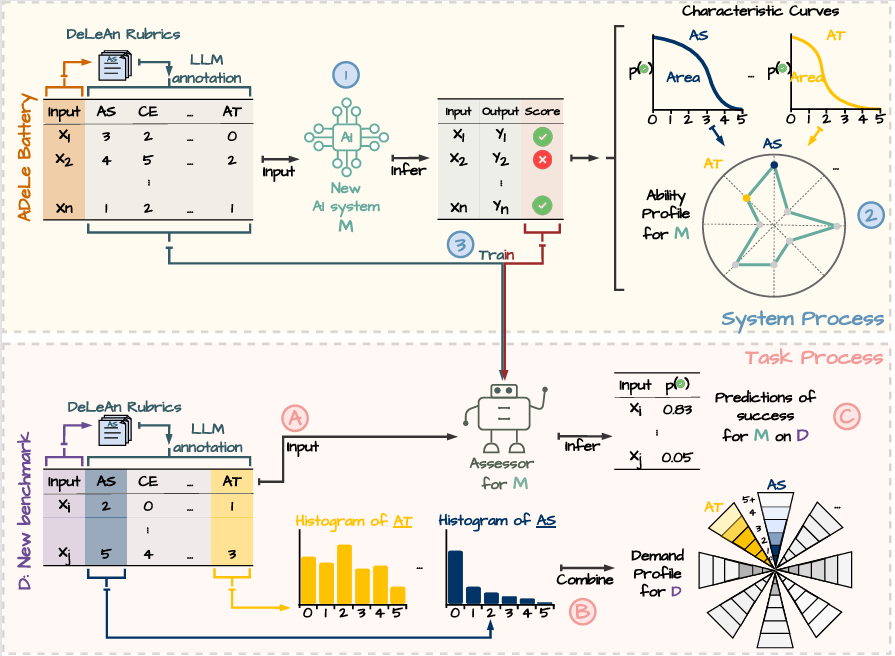 image図1. 上部: (1) ADeLeベンチマークにおけるモデル性能と、(2) その結果得られる能力プロファイル。各モデルのコア能力にわたる強みと限界を示す。下部: (1) 各タスクへの18のスコアリング基準の適用と、(2) その結果得られるタスクプロファイル。各タスクが要求する能力を示す。
image図1. 上部: (1) ADeLeベンチマークにおけるモデル性能と、(2) その結果得られる能力プロファイル。各モデルのコア能力にわたる強みと限界を示す。下部: (1) 各タスクへの18のスコアリング基準の適用と、(2) その結果得られるタスクプロファイル。各タスクが要求する能力を示す。
ADeLeの評価
ADeLeを用いて、研究チームは現在の評価手法が何を捉え、何を見逃しているかを理解するため、様々なAIベンチマークとモデルの振る舞いを評価した。その結果、広く使われている多くのベンチマークはモデル能力について不完全で、時に誤解を招く像を提供しており、より構造化されたアプローチがそれらのギャップを明確にし、モデルが新たな環境でどのように振る舞うかを予測する助けとなり得ることが示された。
ADeLeは、多くのベンチマークが測定を意図した能力を単離しておらず、難易度の範囲も限定的であることを明らかにしている。例えば、論理的推論(logical reasoning)を評価するよう設計されたテストが、専門知識やメタ認知(metacognition)にも大きく依存している場合がある。また、狭い難易度範囲に焦点を当て、より単純なケースとより複雑なケースの両方を省略しているベンチマークもある。タスクが要求する能力に基づいてスコアリングすることで、ADeLeはこうした不一致を可視化し、既存のベンチマークを診断し、より優れたベンチマークを設計する方法を提供する。
この枠組みを15のLLMに適用し、研究チームは18の能力それぞれについて0〜5のスコアを用いて能力プロファイルを構築した。各能力について、タスクの難易度に伴う性能の変化を測定し、モデルが50%の成功率を示す難易度レベルをその能力のスコアとした。図2はこれらの結果を放射状プロット(radial plots)として示しており、モデルがどこで優れ、どこで破綻するかを可視化している。
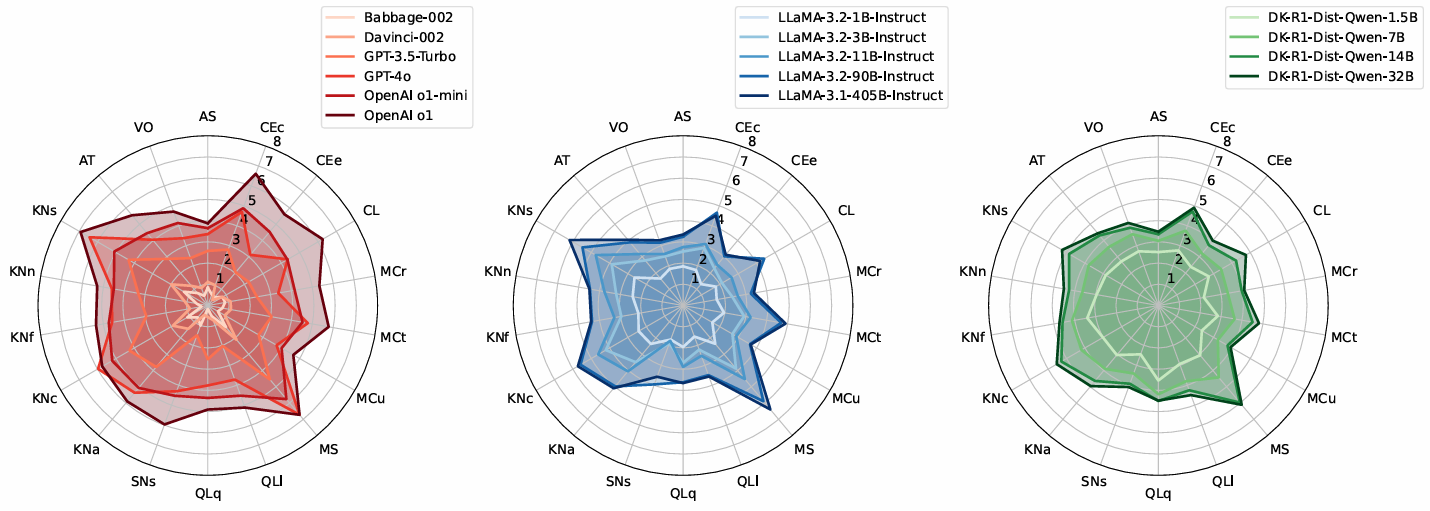 image図2. 18の能力にわたる15のLLMの能力プロファイル。左: OpenAIモデル。中央: Llamaモデル。右: DeepSeek-R1蒸留モデル(distilled models)。
image図2. 18の能力にわたる15のLLMの能力プロファイル。左: OpenAIモデル。中央: Llamaモデル。右: DeepSeek-R1蒸留モデル(distilled models)。
この分析は、モデルによって強みと弱みが異なることを示している。新しいモデルは一般的に古いモデルを上回るが、すべての能力において一貫して優れているわけではない。知識を多く要するタスクでの性能はモデルサイズと学習に強く依存し、推論指向モデル(reasoning-oriented models)は論理、学習、抽象化、社会的推論(social inference)を必要とするタスクで明確な向上を示す。これらのパターンは通常、異なるベンチマークにわたる複数の個別分析を必要とし、タスク要求が注意深く制御されていない場合には矛盾する結論を生み出す可能性さえある。ADeLeはこれらを単一の枠組みの中で明らかにする。
ADeLeは予測も可能にする。モデルの能力プロファイルとタスクの要求とを比較することで、モデルが未経験のタスクであっても成功するかどうかを予測できる。実験では、このアプローチはGPT-4oやLLaMA-3.1-405Bなどのモデルで約88%の精度を達成し、従来手法を上回った。これにより、AIモデルを実際に運用する前に、潜在的な失敗を説明し予測することが可能になり、AIモデル評価の信頼性と予測可能性が向上する。
AIシステムが真に推論できるかどうかは、この分野の中心的な議論である。一部の研究は強力な推論性能を報告する一方、他の研究は規模が大きくなると破綻することを示している。これらの結果はタスクの難易度の違いを反映している。ADeLeは、「推論」を測定するとラベル付けされたベンチマークが、基本的な問題解決から高度な論理、抽象化、ドメイン知識の必要性を組み合わせたタスクまで、必要とするものが異なることを示している。同じモデルが、要求の低いテストでは90%以上のスコアを獲得できる一方、要求の高いテストでは15%以下のスコアしか得られないことがあり、これは能力の変化ではなく、タスク要求の違いを反映している。
OpenAIのo1やGPT-5などの推論指向モデルは、標準モデルに対して測定可能な向上を示す。論理や数学だけでなく、ユーザーの意図の解釈においてもである。しかし、タスクの要求が高まるにつれて性能は低下する。AIシステムは推論できるが、ある程度までであり、ADeLeは各モデルにとってその限界点がどこにあるかを特定する。
ポッドキャストシリーズ

AIテストと評価: 科学と産業からの学び
マイクロソフトが他の分野からどのように学び、AIガバナンスの柱として評価とテストを進めているかを探る。
今すぐ聴く
新しいタブで開く
今後の展望
ADeLeはAIの進歩とともに進化するよう設計されており、マルチモーダルおよび具現化AIシステム(embodied AI systems)への拡張が可能である。また、AI研究、政策立案、セキュリティ監査のための標準化された枠組みとして機能する可能性もある。
より広く言えば、ADeLeはシステムの振る舞いを説明し性能を予測する、より体系的なAI評価アプローチを推進するものである。この研究は、AI評価への心理測定学(psychometrics)の適用に関するマイクロソフトの研究や、AI評価の重要性を強調するSocietal AIに関する最近の研究など、以前の取り組みに基づいている。
汎用AIシステムが既存の評価手法を追い越し続ける中、ADeLeのようなアプローチは、実世界での使用におけるより厳格で透明性のある評価への道筋を提供する。研究チームは、より広いコミュニティを通じてこの取り組みを拡大するために活動している。追加の実験、ベンチマーク注釈、リソースはGitHub(新しいタブで開く)で利用可能である。
新しいタブで開くこの投稿「ADeLe: Predicting and explaining AI performance across tasks」は、Microsoft Researchで最初に公開されました。
原文を表示
At a glance
AI benchmarks report performance on specific tasks but provide limited insight into underlying capabilities; ADeLe evaluates models by scoring both tasks and models across 18 core abilities, enabling direct comparison between task demands and model capabilities.
Using these ability scores, the method predicts performance on new tasks with ~88% accuracy, including for models such as GPT-4o and Llama-3.1.
It builds ability profiles and identifies where models are likely to succeed or fail, highlighting strengths and limitations across tasks.
By linking outcomes to task demands, ADeLe explains differences in performance, showing how it changes as task complexity increases.
AI benchmarks report how large language models (LLMs) perform on specific tasks but provide little insight into their underlying capabilities that drive their performance. They do not explain failures or reliably predict outcomes on new tasks. To address this, Microsoft researchers in collaboration with Princeton University and Universitat Politècnica de València introduce ADeLe (opens in new tab) (AI Evaluation with Demand Levels), a method that characterizes both models and tasks using a broad set of capabilities, such as reasoning and domain knowledge, so performance on new tasks can be predicted and linked to specific strengths and weaknesses in a model.
In a paper published in Nature, “General Scales Unlock AI Evaluation with Explanatory and Predictive Power (opens in new tab),” the team describes how ADeLe moves beyond aggregate benchmark scores. Rather than treating evaluation as a collection of isolated tests, it represents both benchmarks and LLMs using the same set of capability scores. These scores can then be used to estimate how a model will perform on tasks it has not encountered before. The research was supported by Microsoft’s Accelerating Foundation Models Research (AFMR) grant program.
ADeLe-based evaluation
ADeLe scores tasks across 18 core abilities, such as attention, reasoning, domain knowledge, and assigns each task a value from 0 to 5 based on how much it requires each ability. For example, a basic arithmetic problem might score low on quantitative reasoning, but an Olympiad-level proof would score much higher.
Evaluating a model across many such tasks produces an ability profile—a structured view of where the model performs and where it breaks down. Comparing this profile to the demands of a new task makes it possible to identify the specific gaps that lead to failure. The process is illustrated in Figure 1.
imageFigure 1. Top: (1) Model performance on the ADeLe benchmark and (2) the resulting ability profiles, showing each model’s strengths and limitations across core abilities. Bottom: (1) Application of 18 scoring criteria to each task and (2) the resulting task profiles, showing the abilities each task requires.
Evaluating ADeLe
Using ADeLe, the team evaluated a range of AI benchmarks and model behaviors to understand what current evaluations capture and what they miss. The results show that many widely used benchmarks provide an incomplete and sometimes misleading picture of model capabilities and that a more structured approach can clarify those gaps and help predict how models will behave in new settings.
ADeLe shows that many benchmarks do not isolate the abilities they are intended to measure or only cover a limited range of difficulty levels. For example, a test designed to evaluate logical reasoning may also depend heavily on specialized knowledge or metacognition. Others focus on a narrow range of difficulty, omitting both simpler and more complex cases. By scoring tasks based on the abilities they require, ADeLe makes these mismatches visible and provides a way to diagnose existing benchmarks and design better ones.
Applying this framework to 15 LLMs, the team constructed ability profiles using 0–5 scores for each of 18 abilities. For each ability, the team measured how performance changes with task difficulty and used the difficulty level at which the model has a 50% chance of success as its ability score. Figure 2 illustrates these results as radial plots that show where the model performs well and where it breaks down.
imageFigure 2. Ability profiles for 15 LLMs across 18 abilities. Left: OpenAI models. Middle: Llama models. Right: DeepSeek-R1 distilled models.
This analysis shows that models differ in their strengths and weaknesses across abilities. Newer models generally outperform older ones, but not consistently across all abilities. Performance on knowledge-heavy tasks depends strongly on model size and training, while reasoning-oriented models show clear gains on tasks requiring logic, learning, abstraction, and social inference. These patterns typically require multiple, separate analyses across different benchmarks and can still produce conflicting conclusions when task demands are not carefully controlled. ADeLe surfaces them within a single framework.
ADeLe also enables prediction. By comparing a model’s ability profile to the demands of a task, it can forecast whether the model will succeed, even on tasks that are unfamiliar. In experiments, this approach achieved approximately 88% accuracy for models like GPT-4o and LLaMA-3.1-405B, outperforming traditional methods. This makes it possible to both explain and anticipate potential failures before deployment, improving the reliability and predictability of AI model assessment.
Whether AI systems can truly reason is a central debate in the field. Some studies report strong reasoning performance, while others show they break down at scale. These results reflect differences in task difficulty. ADeLe shows that benchmarks labeled as measuring “reasoning” vary in what they require, from basic problem-solving to tasks that combine the need for advanced logic, abstraction, and domain knowledge. The same model can score above 90% on lower-demand tests and below 15% on more demanding ones, reflecting differences in task requirements rather than a change in capability.
Reasoning-oriented models like OpenAI’s o1 and GPT-5 show measurable gains over standard models—not only in logic and mathematics but also with interpreting user intent. However, performance declines as task demands increase. AI systems can reason, but only up to a point, and ADeLe identifies where that point is for each model.
PODCAST SERIES
image
AI Testing and Evaluation: Learnings from Science and Industry
Discover how Microsoft is learning from other domains to advance evaluation and testing as a pillar of AI governance.
Listen now
Opens in a new tab
Looking ahead
ADeLe is designed to evolve alongside advances in AI and can be extended to multimodal and embodied AI systems. It also has the potential to serve as a standardized framework for AI research, policymaking, and security auditing.
More broadly, it advances a more systematic approach to AI evaluation—one that explains system behavior and predicts performance. This work builds on earlier efforts, including Microsoft research on applying psychometrics to AI evaluation and recent work on Societal AI, emphasizing the importance of AI evaluation.
As general-purpose AI systems continue to outpace existing evaluation methods, approaches like ADeLe offer a path toward more rigorous and transparent assessment in real-world use. The research team is working to expand this effort through a broader community. Additional experiments, benchmark annotations, and resources are available on GitHub (opens in new tab).
Opens in a new tabThe post ADeLe: Predicting and explaining AI performance across tasks appeared first on Microsoft Research.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み