カスタムLLMのデプロイを加速: OumiでファインチューニングしAmazon Bedrockにデプロイ
AWSとOumiは、Oumiを使用してLlamaモデルをファインチューニングし、Amazon S3で成果物を管理した後、Amazon BedrockのCustom Model Importでデプロイするワークフローを紹介し、実験段階から本番環境への移行の摩擦を軽減する方法を示している。
キーポイント
実験から本番への移行課題の解決
オープンソースLLMのファインチューニングでは、実験段階と本番環境への移行の間に、異なるツールが必要となることで摩擦が生じる課題がある。
OumiとAWSによる統合ワークフローの提案
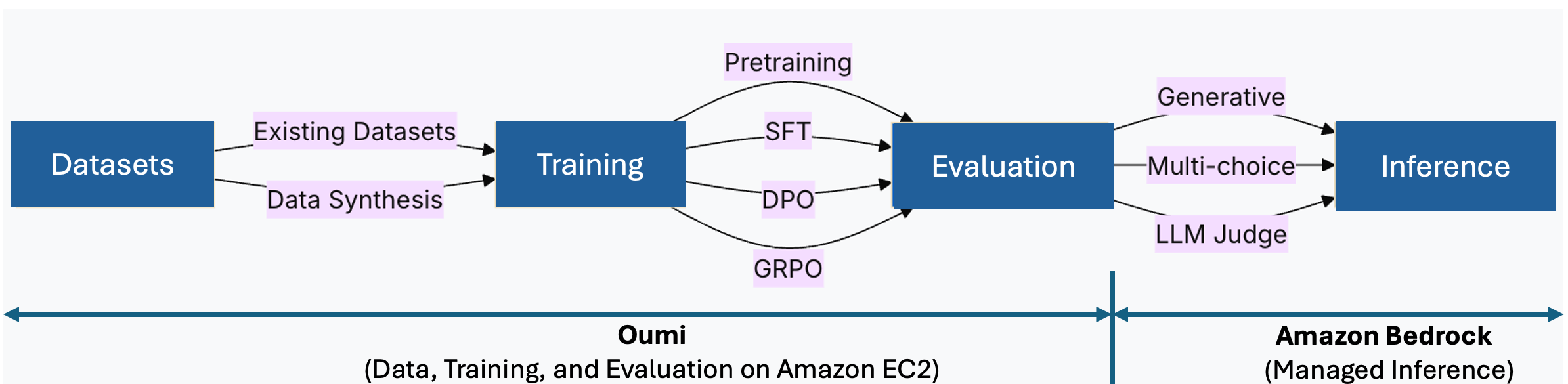
Oumiを使用したデータ準備・トレーニング・評価と、Amazon EC2/SageMaker/EKSでの計算、Amazon S3での成果物管理、Amazon Bedrockへのデプロイを組み合わせた一貫したワークフローを構築できる。
Oumiのレシピ駆動型トレーニングの利点
単一の設定を定義して実験全体で再利用できる「レシピ駆動型トレーニング」により、定型コードを減らし、再現性を向上させる。
Amazon Bedrockへのマネージド推論デプロイ
ファインチューニングしたカスタムモデルを、Amazon BedrockのCustom Model Import機能を使用してマネージド推論環境にデプロイできる。
影響分析・編集コメントを表示
影響分析
この記事は、企業がオープンソースLLMをカスタマイズして本番環境で運用する際の具体的な技術的ハードルを、実用的なAWSベースのソリューションで示しており、AI実装の現場における実践的なガイドとしての価値が高い。ただし、技術的には既存ツールの組み合わせによるワークフロー改善が中心であり、根本的な技術革新を提示するものではない。
編集コメント
AWSのエコシステム内で、オープンソースLLMのカスタマイズから本番デプロイまでをシームレスに繋ぐ実用的なチュートリアル。技術的深掘りよりも、特定のツールチェーン(Oumi + AWS)を使った具体的な実装手順に焦点が当てられている。
*この投稿は、Oumi の David Stewart と Matthew Persons によって共同執筆されました。*
オープンソースの大規模言語モデル(LLM)のファインチューニングは、実験段階と本番環境の間で停滞することがよくあります。トレーニング設定、アーティファクト管理、スケーラブルなデプロイメントそれぞれが異なるツールを必要とし、迅速な実験から安全かつエンタープライズグレードの環境への移行時に摩擦が生じます。
本記事では、Oumi を使用して Amazon EC2 上で Llama モデルをファインチューニングする方法(Oumi を用いて合成データを生成するオプションあり)、成果物を Amazon S3 に保存し、Custom Model Import を使用して Amazon Bedrock 上で管理された推論のためにデプロイする方法をご紹介します。本ウォークスルーでは EC2 を使用していますが、ニーズに応じてファインチューニングは Amazon SageMaker や Amazon Elastic Kubernetes Service などの他のコンピューティングサービスでも完了可能です。
Oumi と Amazon Bedrock のメリット
Oumi は、データ準備からトレーニング、評価に至るまでファウンデーションモデルのライフサイクルを効率化するオープンソースシステムです。各段階で個別のツールを組み立てるのではなく、単一の設定を定義して実行間で再利用できます。
このワークフローにおける主なメリットは以下の通りです:
- レシピ駆動型トレーニング:設定を一度定義するだけで実験間での再利用が可能となり、ボイラープレートコードが削減され、再現性が向上します
- 柔軟なファインチューニング:制約条件に応じて、フルファインチューニングまたは LoRA などのパラメータ効率的な手法を選択できます
- 統合評価:追加のツールなしでベンチマークや LLM-as-a-judge を用いてチェックポイントの評価スコアを取得できます
- データ合成:生産データが限られている場合に、タスク固有のデータを生成できます
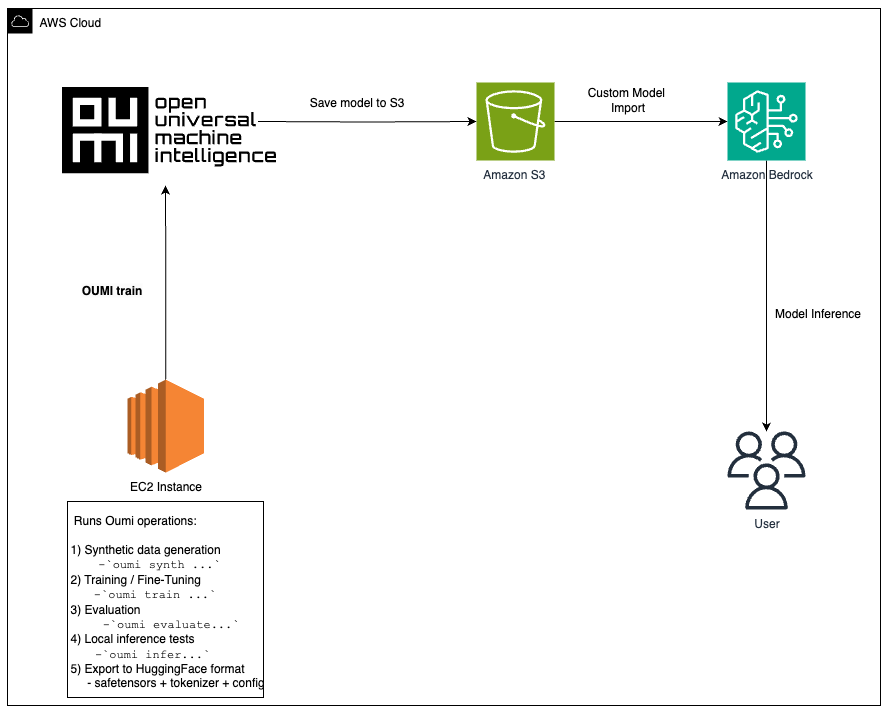
Amazon Bedrock は、管理されたサーバーレス推論を提供することでこれを補完します。Oumi でファインチューニングを行った後、Custom Model Import を介して 3 つの手順でモデルをインポートします:S3 へのアップロード、インポートジョブの作成、そして呼び出しです。推論インフラストラクチャの管理は不要です。以下のアーキテクチャ図は、これらのコンポーネントがどのように連携するかを示しています。
 image
image
図 1:Oumi は EC2 上でデータ、トレーニング、評価を管理します。Amazon Bedrock は Custom Model Import を介して管理された推論を提供します。
ソリューションの概要
このワークフローは以下の 3 つのステージで構成されています:
- EC2 で Oumi を使用してファインチューニング:GPU 最適化インスタンス(例:g5.12xlarge または p4d.24xlarge)を起動し、Oumi をインストールして設定ファイルに従ってトレーニングを実行します。大規模モデルの場合、Oumi はマルチ GPU またはマルチノード構成に対して、Fully Sharded Data Parallel (FSDP)、DeepSpeed、および Distributed Data Parallel (DDP) の戦略による分散トレーニングをサポートしています。
- 成果物を S3 に保存:モデルの重み、チェックポイント、ログをアップロードして永続的なストレージを実現します。
- Amazon Bedrock へのデプロイ:S3 アーティファクトを指すカスタムモデルインポートジョブを作成します。Amazon Bedrock は推論インフラストラクチャを自動的にプロビジョニングします。クライアントアプリケーションは、Amazon Bedrock Runtime APIs を使用してインポートされたモデルを呼び出します。
このアーキテクチャは、ファインチューニング済みモデルを生産環境へ移行する際の一般的な課題に対処します:
課題
Oumi と Amazon Bedrock のソリューション
イテレーション速度
Oumi のモジュラーレシピにより、設定Acrossでの迅速な実験が可能になります
再現性
S3 はバージョン管理されたチェックポイントとトレーニングメタデータを保存します
スケーラブルな推論
Amazon Bedrock は手動の GPU プロビジョニングなしで自動的にスケールします
セキュリティとコンプライアンス
AWS Identity and Access Management (IAM)、Amazon Virtual Private Cloud (VPC)、およびAWS Key Management Services (KMS) はネイティブに統合されています
コスト最適化
トレーニングには Amazon EC2 Spot Instances を活用し、推論には Amazon Bedrock カスタムモデルの 5 分間隔 価格設定 が適用されます
技術的実装
例として meta-llama/Llama-3.2-1B-Instruct モデルを使用した実践的なワークフローを順を追って説明します。このモデルを選定したのは、AWS の g6.12xlarge EC2 インスタンス上でファインチューニングを行うのに適しているためですが、同様のワークフローは多くの他のオープンソースモデルでも再現可能です(なお、より大規模なモデルでは、より大きなインスタンスが必要になったり、複数のインスタンスにわたる分散トレーニングが必要になる場合があります)。詳細については、Oumi モデルのファインチューニングレシピ および Amazon Bedrock のカスタムモデルアーキテクチャ をご覧ください。
前提条件
このウォークスルーを完了するには、以下のものが必要です:
- EC2、S3、およびターゲット AWS リージョンでのカスタムモデルインポートを使用する権限を持つ AWS アカウント(当記事では us-west-2 を使用)。サポート対象リージョンのリストについては、Amazon Bedrock のドキュメントを参照してください。
- 認証情報を設定した IAM ロール。このロールは、S3 内のモデルアーティファクトの読み書きと、カスタムモデルインポートジョブの作成を許可する必要があります。
- モデルインポートジョブの実行およびモデルの呼び出しに使用するための、認証情報が設定された AWS Command Line Interface (AWS CLI) バージョン 2 以降。
- ゲート付きモデル重み(例:meta-llama/Llama-3.2-1B-Instruct)へのアクセスに必要な Hugging Face アカウントおよびアクセストークン。
- サポート用ソースコードリポジトリ: github.com/aws-samples/sample-oumi-fine-tuning-bedrock-cmi
AWS リソースのセットアップ
- ローカルマシン上でこのリポジトリをクローンします:
git clone https://github.com/aws-samples/sample-oumi-fine-tuning-bedrock-cmi.git
cd sample-oumi-fine-tuning-bedrock-cmi
- セットアップスクリプトを実行して、IAM ロール(Identity and Access Management roles)、S3 バケットを作成し、GPU 最適化 EC2 インスタンスを起動します:
./scripts/setup-aws-env.sh [--dry-run]
このスクリプトは AWS リージョン、S3 バケット名、EC2 キーペア名、セキュリティグループ ID を入力するようプロンプトを表示し、必要なすべてのリソースを作成します。デフォルト設定: g6.12xlarge インスタンス、Single CUDA(Amazon Linux 2023)搭載の Deep Learning Base AMI、および 100 GB の gp3 ストレージ。*注意:IAM ロールの作成や EC2 インスタンスの起動に権限がない場合は、このリポジトリを IT 管理者と共有し、AWS 環境を設定するためにこのセクションを完了するよう依頼してください。
- インスタンスが起動すると、スクリプトは SSH コマンドと Amazon Bedrock 用インポートロール ARN(5 番目のステップで必要)を出力します。インスタンスに SSH で接続し、以下の 1 番目のステップを続けて実行してください。
IAM ポリシーの詳細、スコープのガイダンス、検証手順については、iam/README.md を参照してください。
ステップ 1: EC2 環境のセットアップ
EC2 環境をセットアップするために、以下の手順を実行してください。
- EC2 インスタンス(Amazon Linux 2023)上でシステムを更新し、基本依存関係をインストールします:
sudo yum update -y
sudo yum install python3 python3-pip git -y
- サポートリポジトリをクローンします:
git clone https://github.com/aws-samples/sample-oumi-fine-tuning-bedrock-cmi.git
cd sample-oumi-fine-tuning-bedrock-cmi
- 環境変数を設定します(セットアップスクリプトから取得した実際のリージョン名とバケット名に置き換えてください):
export AWS_REGION=us-west-2
export S3_BUCKET=your-bucket-name
export S3_PREFIX=your-s3-prefix
aws configure set default.region "$AWS_REGION"
- セットアップスクリプトを実行して、Python の仮想環境を作成し、Oumi をインストールし、GPU の利用可能性を検証し、Hugging Face の認証を設定します。オプションについては setup-environment.sh を参照してください。
./scripts/setup-environment.sh
source .venv/bin/activate
- ゲート付きモデルの重みにアクセスするために Hugging Face で認証を行います。huggingface.co/settings/tokens でアクセストークンを生成し、その後以下を実行します:
hf auth login
ステップ 2:トレーニングの設定
デフォルトのデータセットは tatsu-lab/alpaca で、configs/oumi-config.yaml に設定されています。Oumi はトレーニング中にこれを自動的にダウンロードするため、手動でのダウンロードは不要です。異なるデータセットを使用する場合は、configs/oumi-config.yaml 内の dataset_name パラメータを更新してください。サポートされている形式については、Oumi データセットドキュメント を参照してください。
[オプション] Oumi を使用して合成トレーニングデータを生成する:
推論バックエンドとして Amazon Bedrock を使用して合成データを生成するには、configs/synthesis-config.yaml 内の model_name プレースホルダーを、アクセス権限を持つ Amazon Bedrock モデル ID(例:anthropic.claude-sonnet-4-6)に更新してください。詳細については Oumi データ合成ドキュメント を参照してください。その後、以下を実行します:
oumi synth -c configs/synthesis-config.yaml
ステップ 3:モデルのファインチューニング
Llama-3.2-1B-Instruct 用の Oumi の組み込みトレーニング レシピ を使用して、モデルをファインチューニングします:
./scripts/fine-tune.sh --config configs/oumi-config.yaml --output-dir models/final [--dry-run]
ハイパーパラメータをカスタマイズするには、oumi-config.yaml を編集してください。
*注: ステップ 2 で合成データを生成した場合は、トレーニング前に設定ファイル内のデータセットパスを更新してください。*
nvidia-smi または Amazon CloudWatch Agent を使用して GPU の利用率を監視してください。長時間実行されるジョブの場合、Amazon EC2 Automatic Instance Recovery を設定して、インスタントの中断に対応できるようにしてください。
ステップ 4: モデルの評価(オプション)
標準的なベンチマークを使用して、ファインチューニングされたモデルを評価できます:
oumi evaluate -c configs/evaluation-config.yaml
評価設定ファイルは、モデルパスとベンチマークタスク(例:MMLU など)を指定します。カスタマイズするには、evaluation-config.yaml を編集してください。LLM-as-a-judge 手法や追加のベンチマークについては、Oumi の 評価ガイド を参照してください。
ステップ 5: Amazon Bedrock へのデプロイ
モデルを Amazon Bedrock にデプロイするには、以下の手順を実行してください:
- モデルアーティファクトを S3 にアップロードし、Amazon Bedrock へモデルをインポートします。
./scripts/upload-to-s3.sh --bucket $S3_BUCKET --source models/final --prefix $S3_PREFIX
./scripts/import-to-bedrock.sh --model-name my-fine-tuned-llama --s3-uri s3://$S3_BUCKET/$S3_PREFIX --role-arn $BEDROCK_ROLE_ARN --wait
- インポートスクリプトは完了時にモデル ARN を出力します。MODEL_ARN にこの値(形式:arn:aws:bedrock:::imported-model/)を設定してください。
- Amazon Bedrock 上でモデルを呼び出します
./scripts/invoke-model.sh --model-id $MODEL_ARN --prompt "Translate this text to French: What is the capital of France?"
- Amazon Bedrock は自動的に管理された推論環境を作成します。IAM ロールの設定については、bedrock-import-role.json を参照してください。
- モデル改訂のロールバックをサポートするために、バケットで S3 バージョニングを有効にしてください。SSE-KMS 暗号化およびバケットポリシーの強化については、コンパニオンリポジトリ内のセキュリティスクリプトを参照してください。
ステップ 6: クリーンアップ
継続的なコストを防ぐために、このウォークスルー中に作成されたリソースを削除します:
aws ec2 terminate-instances --instance-ids $INSTANCE_ID
aws s3 rm s3://$S3_BUCKET/$S3_PREFIX/ --recursive
aws be
原文を表示
*This post is cowritten by David Stewart and Matthew Persons from Oumi.*
Fine-tuning open source large language models (LLMs) often stalls between experimentation and production. Training configurations, artifact management, and scalable deployment each require different tools, creating friction when moving from rapid experimentation to secure, enterprise-grade environments.
In this post, we show how to fine-tune a Llama model using Oumi on Amazon EC2 (with the option to create synthetic data using Oumi), store artifacts in Amazon S3, and deploy to Amazon Bedrock using Custom Model Import for managed inference. While we use EC2 in this walkthrough, fine-tuning can be completed on other compute services such as Amazon SageMaker or Amazon Elastic Kubernetes Service, depending on your needs.
Benefits of Oumi and Amazon Bedrock
Oumi is an open source system that streamlines the foundation model lifecycle, from data preparation and training to evaluation. Instead of assembling separate tools for each stage, you define a single configuration and reuse it across runs.
Key benefits for this workflow:
- Recipe-driven training: Define your configuration once and reuse it across experiments, reducing boilerplate and improving reproducibility
- Flexible fine-tuning: Choose full fine-tuning or parameter-efficient methods like LoRA, based on your constraints
- Integrated evaluation: Score checkpoints using benchmarks or LLM-as-a-judge without additional tooling
- Data synthesis: Generate task-specific datasets when production data is limited
Amazon Bedrock complements this by providing managed, serverless inference. After fine-tuning with Oumi, you import your model via Custom Model Import in three steps: upload to S3, create the import job, and invoke. No inference infrastructure to manage. The following architecture diagram shows how these components work together.
Figure 1: Oumi manages data, training, and evaluation on EC2. Amazon Bedrock provides managed inference via Custom Model Import.
Solution overview
This workflow consists of three stages:
- Fine-tune with Oumi on EC2: Launch a GPU-optimized instance (for example, g5.12xlarge or p4d.24xlarge), install Oumi, and run training with your configuration. For larger models, Oumi supports distributed training with Fully Sharded Data Parallel (FSDP), DeepSpeed, and Distributed Data Parallel (DDP) strategies across multi-GPU or multi-node setups.
- Store artifacts on S3: Upload model weights, checkpoints, and logs for durable storage.
- Deploy to Amazon Bedrock: Create a Custom Model Import job pointing to your S3 artifacts. Amazon Bedrock provisions inference infrastructure automatically. Client applications call the imported model using the Amazon Bedrock Runtime APIs.
This architecture addresses common challenges in moving fine-tuned models to production:
Challenge
Oumi and Amazon Bedrock solution
Iteration speed
Oumi’s modular recipes enable rapid experimentation across configurations
Reproducibility
S3 stores versioned checkpoints and training metadata
Scalable inference
Amazon Bedrock scales automatically without manual GPU provisioning
Security and compliance
AWS Identity and Access Management (IAM), Amazon Virtual Private Cloud (VPC), and AWS Key Management Services (KMS) integrate natively
Cost optimization
Amazon EC2 Spot Instances for training; Amazon Bedrock custom model 5-minute interval pricing for inference
Technical implementation
Let’s walk through a hands-on workflow using the meta-llama/Llama-3.2-1B-Instruct model as an example. While we selected this model since it pairs well with fine-tuning on an AWS g6.12xlarge EC2 instance, the same workflow can be replicated across many other open source models (note that larger models may require larger instances or distributed training across instances). For more information, see the Oumi model fine-tuning recipes and Amazon Bedrock custom model architectures.
Prerequisites
To complete this walkthrough, you need:
- An AWS account with permissions to use EC2, S3, and Custom Model Import in your target AWS Region (we use us-west-2). For the list of supported Regions, see the Amazon Bedrock documentation.
- An IAM role configured with credentials. The role must allow reading and writing model artifacts in S3 and creating a Custom Model Import job.
- AWS Command Line Interface (AWS CLI) version 2 or later, configured with credentials, to run the model import job and invoke the model.
- A Hugging Face account and access token for gated model weights (for example, meta-llama/Llama-3.2-1B-Instruct).
- The companion source code repository: github.com/aws-samples/sample-oumi-fine-tuning-bedrock-cmi
Set up AWS Resources
- Clone this repository on your local machine:
git clone https://github.com/aws-samples/sample-oumi-fine-tuning-bedrock-cmi.git
cd sample-oumi-fine-tuning-bedrock-cmi- Run the setup script to create IAM roles, an S3 bucket, and launch a GPU-optimized EC2 instance:
./scripts/setup-aws-env.sh [--dry-run]The script prompts for your AWS Region, S3 bucket name, EC2 key pair name, and security group ID, then creates all required resources. Defaults: g6.12xlarge instance, Deep Learning Base AMI with Single CUDA (Amazon Linux 2023), and 100 GB gp3 storage. *Note: If you do not have permissions to create IAM roles or launch EC2 instances, share this repository with your IT administrator and ask them to complete this section to set up your AWS environment.*
- Once the instance is running, the script outputs the SSH command and the Amazon Bedrock import role ARN (needed in Step 5). SSH into the instance and continue with Step 1 below.
See the iam/README.md for IAM policy details, scoping guidance, and validation steps.
Step 1: Set up the EC2 environment
Complete the following steps to set up the EC2 environment.
- On the EC2 instance (Amazon Linux 2023), update the system and install base dependencies:
sudo yum update -y
sudo yum install python3 python3-pip git -y- Clone the companion repository:
git clone https://github.com/aws-samples/sample-oumi-fine-tuning-bedrock-cmi.git
cd sample-oumi-fine-tuning-bedrock-cmi- Configure environment variables (replace the values with your actual region and bucket name from the setup script):
export AWS_REGION=us-west-2
export S3_BUCKET=your-bucket-name
export S3_PREFIX=your-s3-prefix
aws configure set default.region "$AWS_REGION"- Run the setup script to create a Python virtual environment, install Oumi, validate GPU availability, and configure Hugging Face authentication. See setup-environment.sh for options.
./scripts/setup-environment.sh
source .venv/bin/activate- Authenticate with Hugging Face to access gated model weights. Generate an access token at huggingface.co/settings/tokens, then run:
hf auth loginStep 2: Configure training
The default dataset is tatsu-lab/alpaca, configured in configs/oumi-config.yaml. Oumi downloads it automatically during training, no manual download is needed. To use a different dataset, update the dataset_name parameter in configs/oumi-config.yaml. See the Oumi dataset docs for supported formats.
[Optional] Generate synthetic training data with Oumi:
To generate synthetic data using Amazon Bedrock as the inference backend, update the model_name placeholder in configs/synthesis-config.yaml with an Amazon Bedrock model ID you have access to (e.g. anthropic.claude-sonnet-4-6). See Oumi data synthesis docs for details. Then run:
oumi synth -c configs/synthesis-config.yamlStep 3: Fine-tune the model
Fine-tune the model using Oumi’s built-in training recipe for Llama-3.2-1B-Instruct:
./scripts/fine-tune.sh --config configs/oumi-config.yaml --output-dir models/final [--dry-run]To customize hyperparameters, edit oumi-config.yaml.
*Note: If you generated synthetic data in Step 2, update the dataset path in the config before training. *
Monitor GPU utilization with nvidia-smi or Amazon CloudWatch Agent. For long-running jobs, configure Amazon EC2 Automatic Instance Recovery to handle instance interruptions.
Step 4: Evaluate model (Optional)
You can evaluate the fine-tuned model using standard benchmarks:
oumi evaluate -c configs/evaluation-config.yamlThe evaluation config specifies the model path and benchmark tasks (e.g., MMLU). To customize, edit evaluation-config.yaml. For LLM-as-a-judge approaches and additional benchmarks, see Oumi’s evaluation guide.
Step 5: Deploy to Amazon Bedrock
Complete the following steps to deploy the model to Amazon Bedrock:
- Upload model artifacts to S3 and import the model to Amazon Bedrock.
./scripts/upload-to-s3.sh --bucket $S3_BUCKET --source models/final --prefix $S3_PREFIX
./scripts/import-to-bedrock.sh --model-name my-fine-tuned-llama --s3-uri s3://$S3_BUCKET/$S3_PREFIX --role-arn $BEDROCK_ROLE_ARN --wait- The import script outputs the model ARN on completion. Set MODEL_ARN to this value (format: arn:aws:bedrock:::imported-model/).
- Invoke the model on Amazon Bedrock
./scripts/invoke-model.sh --model-id $MODEL_ARN --prompt "Translate this text to French: What is the capital of France?"- Amazon Bedrock creates a managed inference environment automatically. For IAM role set up, see bedrock-import-role.json.
- Enable S3 versioning on the bucket to support rollback of model revisions. For SSE-KMS encryption and bucket policy hardening, see the security scripts in the companion repository.
Step 6: Clean up
To avoid ongoing costs, remove the resources created during this walkthrough:
aws ec2 terminate-instances --instance-ids $INSTANCE_ID
aws s3 rm s3://$S3_BUCKET/$S3_PREFIX/ --recursive
aws be
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み