Amazon Polly双方向ストリーミングの紹介:会話型AIのためのリアルタイム音声合成
AWSはAmazon Pollyの双方向ストリーミングAPIを発表し、リアルタイムのテキスト生成と音声合成を同時に行うことで、会話型AIアプリケーションの応答遅延を大幅に削減する新機能を提供した。
キーポイント
双方向ストリーミングAPIの導入
従来のリクエスト-レスポンス型ではなく、HTTP/2を利用した双方向通信により、テキストの送信と音声の受信を同時に行える新しいAPIアーキテクチャを実現した。
LLMとの連携最適化
大規模言語モデルがトークン単位でテキストを生成する特性に合わせ、完全な応答文を待たずに逐次音声合成を開始できるため、会話型AIの応答遅延を大幅に削減する。
従来TTSの課題解決
従来のテキスト読み上げAPIでは、完全なテキスト収集→合成リクエスト→音声生成→再生開始という段階的な待ち時間が発生していたが、新APIではこれらのボトルネックを解消する。
主要機能と制御性
インクリメンタルなテキスト送信、リアルタイム音声受信、フラッシュ設定による合成タイミング制御、単一接続での真の双方向通信を実現するStartSpeechSynthesisStream APIを提供する。
リアクティブストリームによるテキスト送信
Amazon Pollyへのテキスト送信はリアクティブストリームのPublisherを使用し、TextEventオブジェクトにテキストを格納して送信する。
ビジターパターンによるオーディオイベント処理
オーディオデータはレスポンスハンドラを通じてビジターパターンで受信され、onAudioEventでオーディオチャンクを即時処理し、onStreamClosedEventで合成完了を検知する。
LLMとの統合によるインクリメンタル生成
双方向ストリーミングをLLMのインクリメンタルテキスト生成と統合する実装例が示されており、Publisherを介して外部からテキストを注入できる。
影響分析・編集コメントを表示
影響分析
この技術革新は、会話型AIの実用性を大きく前進させるもので、特にLLMとの連携において自然な対話体験を実現する基盤技術となる。AWSのクラウドサービスとして提供されることで、広範な開発者が高度な音声合成機能を容易に導入できる環境を整備し、音声インターフェースの普及を加速させる可能性が高い。
編集コメント
LLMの普及に伴い顕在化していた音声合成の遅延問題に対して、AWSが実用的な解決策を提供した点が評価できる。クラウドネイティブなアーキテクチャ設計は、今後の音声AIサービスにおける新たな標準となる可能性がある。
タイトル: Amazon Polly 双方向ストリーミング API の紹介: 会話型 AI のためのリアルタイム音声合成
自然な会話体験を構築するには、リアルタイムのインタラクションに追従する音声合成が必要です。本日、Amazon Polly の新しい 双方向ストリーミング API のリリースをお知らせします。これにより、テキストの送信と音声の受信を同時に開始できる、効率的なリアルタイム テキスト読み上げ (TTS) 合成が可能になります。
この新しい API は、大規模言語モデル (LLM) からの応答のように、テキストや音声を逐次生成する会話型 AI アプリケーション向けに構築されています。ユーザーは完全なテキストが揃う前に音声合成を開始できます。Amazon Polly は既に合成された音声をユーザーにストリーミングで返す機能をサポートしています。新しい API はさらに一歩進み、HTTP/2 を介した双方向通信に重点を置くことで、速度の向上、レイテンシーの低減、利用の効率化を実現します。
従来のテキスト読み上げの課題
従来のテキスト読み上げ API はリクエスト-レスポンスパターンに従います。これには、合成リクエストを行う前に完全なテキストを収集する必要がありました。Amazon Polly はリクエスト後に音声を逐次ストリーミングで返しますが、ボトルネックは入力側にあります。テキストが完全に揃うまで、テキストの送信を開始できません。LLM によって駆動される会話アプリケーションでは、テキストがトークン単位で生成されるため、合成が開始される前に応答全体を待つ必要があります。
LLM によって駆動される仮想アシスタントを考えてみてください。モデルは数秒間にわたってトークンを逐次生成します。従来の TTS では、ユーザーは以下を待たなければなりません:
- LLM が完全な応答の生成を終えること
- TTS サービスがテキスト全体を合成すること
- 再生が開始される前に音声をダウンロードすること
新しい Amazon Polly 双方向ストリーミング API は、これらのボトルネックに対処するために設計されています。
新機能: 双方向ストリーミング
StartSpeechSynthesisStream API は根本的に異なるアプローチを導入します:
- テキストを逐次送信: 利用可能になったテキストを Amazon Polly にストリーミングします。完全な文や段落を待つ必要はありません。
- 音声を即座に受信: 生成されると同時に合成された音声バイトをリアルタイムで受け取ります。
- 合成タイミングを制御: フラッシュ設定を使用してバッファリングされたテキストの即時合成をトリガーします。
- 真の双方向通信: 単一の接続を介して同時に送受信します。
主要コンポーネント
| コンポーネント | イベント方向 | 方向 | 目的 |
|---|---|---|---|
TextEvent | インバウンド | クライアント → Amazon Polly | 合成するテキストを送信 |
CloseStreamEvent | インバウンド | クライアント → Amazon Polly | テキスト入力の終了を通知 |
AudioEvent | アウトバウンド | Amazon Polly → クライアント | 合成された音声チャンクを受信 |
StreamClosedEvent | アウトバウンド | Amazon Polly → クライアント | ストリーム完了の確認 |
従来の方法との比較
従来のファイル分離実装
以前は、低遅延の TTS を実現するにはアプリケーションレベルの実装が必要でした:
このアプローチには以下が必要でした:
- サーバーサイドのテキスト分割ロジック
- 複数の並列 Amazon Polly API 呼び出し
- 複雑な音声再構築
導入後: ネイティブ双方向ストリーミング
利点:
- 分割ロジックが不要
- 単一の永続的接続
- 両方向のネイティブストリーミング
- インフラストラクチャの複雑さの軽減
- 低レイテンシー
パフォーマンスベンチマーク
実際の効果を測定するため、従来の SynthesizeSpeech API と新しい双方向 StartSpeechSynthesisStream API の両方を同じ入力(7,045文字の散文、970語)に対してベンチマークしました。Matthew音声とGenerative エンジン、MP3出力24kHz、us-west-2リージョンを使用しました。
測定方法: 両方のテストは、LLMが単語あたり約30ミリ秒でトークンを生成することをシミュレートします。従来のAPIテストは、文の境界に達するまで単語をバッファリングし、完全な文をSynthesizeSpeechリクエストとして送信し、完全な音声応答を待ってから続行します。これらのテストは、合成をリクエストする前に完全な文が必要であるため、従来のTTS統合がどのように機能するかを反映しています。双方向ストリーミングAPIテストは、各単語が到着するとストリームに送信し、Amazon Pollyが完全なテキストが揃う前に合成を開始できるようにします。両方のテストは同じテキスト、音声、出力設定を使用します。
| メトリクス | 従来の SynthesizeSpeech | 双方向ストリーミング | 改善 |
|---|---|---|---|
| 総処理時間 | 115,226 ms (~115s) | 70,071 ms (~70s) | 39% 高速化 |
| API呼び出し | 27 | 1 | 27倍 減少 |
| 送信された文 | 27 (順次) | 27 (単語到着時にストリーミング) | — |
| 総音声バイト数 | 2,354,292 | 2,324,636 | — |
主な利点はアーキテクチャにあります:双方向 API は、単一の接続を介して入力テキストを送信し、合成された音声を同時に受信することを可能にします。各文が蓄積されるのを待ってから合成をリクエストする代わりに、テキストは LLM が生成するにつれて単語ごとに Amazon Polly にストリーミングされます。会話型 AI にとって、これは Amazon Polly が生成全体を通じてテキストを逐次受信・処理することを意味し、LLM が終了した後に一度にすべてを受信するわけではありません。その結果、生成完了後の合成待ち時間が短縮され、プロンプトから完全に配信された音声までのエンドツーエンドのレイテンシーが大幅に減少します。
技術的実装
はじめに
双方向ストリーミング API は、AWS SDK for Java 2.x、JavaScript v3、.NET v4、C++、Go v2、Kotlin、PHP v3、Ruby v3、Rust、Swift で利用できます。AWS Command Line Interface (AWS CLI) v1 および v2、PowerShell v4 および v5、Python、.NET v3 のサポートは現在提供されていません。以下は例です:
原文を表示
Building natural conversational experiences requires speech synthesis that keeps pace with real-time interactions. Today, we’re excited to announce the new Bidirectional Streaming API for Amazon Polly, enabling streamlined real-time text-to-speech (TTS) synthesis where you can start sending text and receiving audio simultaneously.
This new API is built for conversational AI applications that generate text or audio incrementally, like responses from large language models (LLMs), where users must begin synthesizing audio before the full text is available. Amazon Polly already supports streaming synthesized audio back to users. The new API goes further focusing on bidirectional communication over HTTP/2, allowing for enhanced speed, lower latency, and streamlined usage.
The challenge with traditional text-to-speech
Traditional text-to-speech APIs follow a request-response pattern. This required you to collect the complete text before making a synthesis request. Amazon Polly streams audio back incrementally after a request is made, but the bottleneck is on the input side—you can’t begin sending text until it’s fully available. In conversational applications powered by LLMs, where text is generated token by token, this means waiting for the entire response before synthesis starts.
Consider a virtual assistant powered by an LLM. The model generates tokens incrementally over several seconds. With traditional TTS, users must wait for:
- The LLM to finish generating the complete response
- The TTS service to synthesize the entire text
- The audio to download before playback begins
The new Amazon Polly bidirectional streaming API is designed to address these bottlenecks.
What’s new: Bidirectional Streaming
The StartSpeechSynthesisStream API introduces a fundamentally different approach:
- Send text incrementally: Stream text to Amazon Polly as it becomes available—no need to wait for complete sentences or paragraphs.
- Receive audio immediately: Get synthesized audio bytes back in real-time as they’re generated.
- Control synthesis timing: Use flush configuration to trigger immediate synthesis of buffered text.
- True duplex communication: Send and receive simultaneously over a single connection.
Key Components
Component
Event Direction
Direction
Purpose
TextEvent
Inbound
Client → Amazon Polly
Send text to be synthesized
CloseStreamEvent
Inbound
Client → Amazon Polly
Signal end of text input
AudioEvent
Outbound
Amazon Polly → Client
Receive synthesized audio chunks
StreamClosedEvent
Outbound
Amazon Polly → Client
Confirmation of stream completion
Comparison to traditional methods
Traditional file separation implementations
Previously, achieving low-latency TTS required application-level implementations:
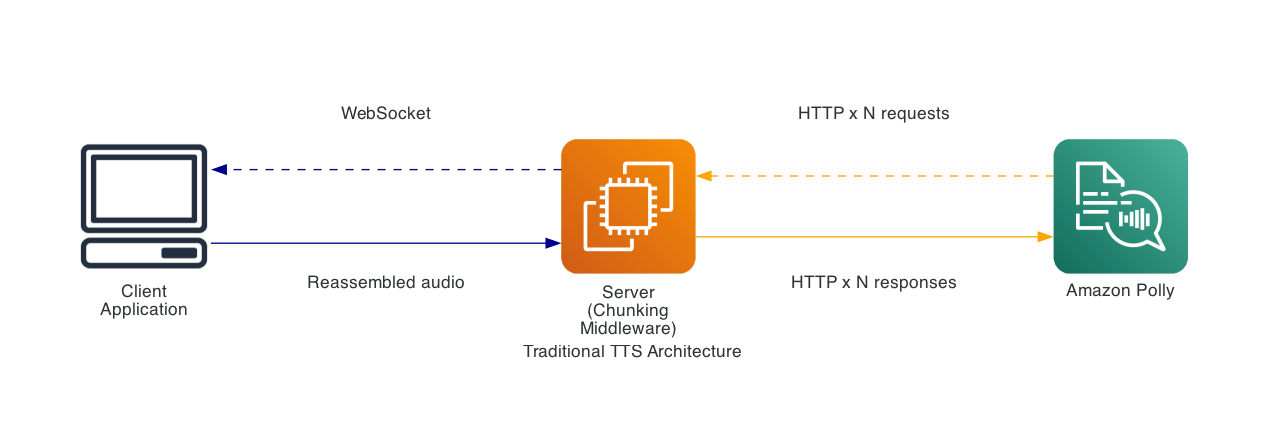
This approach required:
- Server-side text separation logic
- Multiple parallel Amazon Polly API calls
- Complex audio reassembly
After: Native Bidirectional Streaming

Benefits:
- No separation logic required
- Single persistent connection
- Native streaming in both directions
- Reduced infrastructure complexity
- Lower latency
Performance benchmarks
To measure the real-world impact, we benchmarked both the traditional SynthesizeSpeech API and the new bidirectional StartSpeechSynthesisStream API against the same input: 7,045 characters of prose (970 words), using the Matthew voice with the Generative engine, MP3 output at 24kHz in us-west-2.
How we measured: Both tests simulate an LLM generating tokens at ~30 ms per word. The traditional API test buffers words until a sentence boundary is reached, then sends the complete sentence as a SynthesizeSpeech request and waits for the full audio response before continuing. These tests mirror how traditional TTS integrations work, because you must have the complete sentence before requesting synthesis. The bidirectional streaming API test sends each word to the stream as it arrives, allowing Amazon Polly to begin synthesis before the full text is available. Both tests use the same text, voice, and output configuration.
Metric
Traditional SynthesizeSpeech
Bidirectional Streaming
Improvement
Total processing time
115,226 ms (~115s)
70,071 ms (~70s)
39% faster
API calls
27
1
27x fewer
Sentences sent
27 (sequential)
27 (streamed as words arrive)
—
Total audio bytes
2,354,292
2,324,636
—
The key advantage is architectural: the bidirectional API allows sending input text and receiving synthesized audio simultaneously over a single connection. Instead of waiting for each sentence to accumulate before requesting synthesis, text is streamed to Amazon Polly word-by-word as the LLM produces it. For conversational AI, this means that Amazon Polly receives and processes text incrementally throughout generation, rather than receiving it all at once after the LLM finishes. The result is less time waiting for synthesis after generation completes—the overall end-to-end latency from prompt to fully delivered audio is significantly reduced.
Technical implementation
Getting started
You can use the bidirectional streaming API with AWS SDK for Java-2x, JavaScript v3, .NET v4, C++, Go v2, Kotlin, PHP v3, Ruby v3, Rust, and Swift. Support for CLIs (AWS Command Line Interface (AWS CLI) v1 and v2, PowerShell v4 and v5), Python, .NET v3 are not currently supported. Here’s an example:
// Create the async Polly client
PollyAsyncClient pollyClient = PollyAsyncClient.builder()
.region(Region.US_WEST_2)
.credentialsProvider(DefaultCredentialsProvider.create())
.build();
// Create the stream request
StartSpeechSynthesisStreamRequest request = StartSpeechSynthesisStreamRequest.builder()
.voiceId(VoiceId.JOANNA)
.engine(Engine.GENERATIVE)
.outputFormat(OutputFormat.MP3)
.sampleRate("24000")
.build();Sending text events
Text is sent to Amazon Polly using a reactive streams Publisher. Each TextEvent contains text:
TextEvent textEvent = TextEvent.builder() .text("Hello, this is streaming text-to-speech!") .build();Handling audio events
Audio arrives through a response handler with a visitor pattern:
StartSpeechSynthesisStreamResponseHandler responseHandler =
StartSpeechSynthesisStreamResponseHandler.builder()
.onResponse(response -> System.out.println("Stream connected"))
.onError(error -> handleError(error))
.subscriber(StartSpeechSynthesisStreamResponseHandler.Visitor.builder()
.onAudioEvent(audioEvent -> {
// Process audio chunk immediately
byte[] audioData = audioEvent.audioChunk().asByteArray();
playOrBufferAudio(audioData);
})
.onStreamClosedEvent(event -> {
System.out.println("Synthesis complete. Characters processed: "
+ event.requestCharacters());
})
.build())
.build();Complete example: streaming text from an LLM
Here’s a practical example showing how to integrate bidirectional streaming with incremental text generation:
public class LLMIntegrationExample {
private final PollyAsyncClient pollyClient;
private Subscriber textSubscriber;
/**
* Start a bidirectional stream and return a handle for sending text.
*/
public CompletableFuture startStream(VoiceId voice, AudioConsumer audioConsumer) {
StartSpeechSynthesisStreamRequest request = StartSpeechSynthesisStreamRequest.builder()
.voiceId(voice)
.engine(Engine.GENERATIVE)
.outputFormat(OutputFormat.PCM)
.sampleRate("16000")
.build();
// Publisher that allows external text injection
Publisher textPublisher = subscriber -> {
this.textSubscriber = subscriber;
subscriber.onSubscribe(new Subscription() {
@Override
public void request(long n) { /* Demand-driven by subscriber */ }
@Override
public void cancel() { textSubscriber = null; }
});
};
StartSpeechSynthesisStreamResponseHandler handler =
StartSpeechSynthesisStreamResponseHandler.builder()
.subscriber(StartSpeechSynthesisStreamResponseHandler.Visitor.builder()
.onAudioEvent(event -> {
if (event.audioChunk() != null) {
audioConsumer.accept(event.audioChunk().asByteArray());
}
})
.onStreamClosedEvent(event -> audioConsumer.complete())
.build())
.build();
return pollyClient.startSpeechSynthesisStream(request, textPublisher, handler);
}
/**
* Send text file to the stream. Call this as LLM tokens arrive.
*/
public void sendText(String text, boolean flush) {
if (textSubscriber != null) {
TextEvent event = TextEvent.builder()
.text(text)
.flushStreamConfiguration(FlushStreamConfiguration.builder()
.force(flush)
.build())
.build();
textSubscriber.onNext(event);
}
}
/**
* Close the stream when text generation is complete.
*/
public void closeStream() {
if (textSubscriber != null) {
textSubscriber.onNext(CloseStreamEvent.builder().build());
textSubscriber.onComplete();
}
}
}Integration pattern with LLM streaming
The following shows how to integrate patterns with LLM streaming:
// Start the Polly stream
pollyStreamer.startStream(VoiceId.JOANNA, audioPlayer::playChunk);// As LLM generates tokens...
llmClient.streamCompletion(prompt, token -> {
// Send each token to Polly
//Optionally Flush at sentence boundaries to force synthesis
//note the tradeoff here: you may get the audio sooner, but audio quality may be impacted
boolean isSentenceEnd = token.endsWith(".") || token.endsWith("!") || token.endsWith("?");
pollyStreamer.sendText(token, isSentenceEnd);
});
// When LLM completes
pollyStreamer.closeStream();Business benefits
Improved user experience
Latency directly impacts user satisfaction. The faster users hear a response, the more natural and engaging the interaction feels. The bidirectional streaming API enables:
- Reduced perceived wait time – Audio playback begins while the LLM is still generating, masking backend processing time.
- Higher engagement – Faster, more responsive interactions lead to increased user retention and satisfaction.
- Streamlined implementation – The setup and management of the streaming solution is now a single API call with clear hooks and callbacks to remove the complexity.
Reduced operational costs
Streamlining your architecture translates directly to cost savings:
Cost factor
Traditional chunking
Bidirectional Streaming
Infrastructure
WebSocket servers, load balancers, chunking middleware
Direct client-to-Amazon Polly connection
Development
Custom chunking logic, audio reassembly, error handling
SDK handles complexity
Maintenance
Multiple components to monitor and update
Single integration point
API Calls
Multiple calls per request (one per chunk)
Single streaming session
Organizations can expect to reduce infrastructure costs by removing intermediate servers and decrease development time by using native streaming capability.
Use cases
The bidirectional streaming API is recommended for:
- Conversational AI Assistants – Stream LLM responses directly to speech
- Real-time Translation – Synthesize translated text as it’s generated
- Interactive Voice Response (IVR) – Dynamic, responsive phone systems
- Accessibility Tools – Real-time screen readers and text-to-speech
- Gaming – Dynamic NPC dialogue and narration
- Live Captioning – Audio output for live transcription systems
Conclusion
The new Bidirectional Streaming API for Amazon Polly represents a significant advancement in real-time speech synthesis. By enabling true streaming in both directions, it removes latency bottlenecks that have traditionally plagued conversational AI applications.
Key takeaways:
- Reduced latency – Audio begins playing while text is still being generated
- Simplified architecture – No need for file separation workarounds or complex infrastructure
- Native LLM integration – Purpose-built for streaming text from language models
- Flexible control – Fine-grained control over synthesis timing with flush configuration
Whether you’re building a virtual assistant, accessibility tool, or any application requiring responsive text-to-speech, the bidirectional streaming API provides the foundation for truly conversational experiences.
Next steps
The bidirectional streaming API is now Generally Available. To get started:
- Update to the latest AWS SDK for Java 2.x with bidirectional streaming support
- Review the API documentation for detailed reference
- Try the example code in this post to experience the low-latency streaming
We’re excited to see what you build with this new capability. Share your feedback and use cases with us!
About the authors

“Scott Mishra”
<a href="https://www.linkedin.com/in/scott-mishra/" targe
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み