AI に備えたデータ構築:バンガードのバーチャルアナリストへの道
バーガー・グループ(Vanguard)は、基盤モデルの選定だけでなく「AI 対応データ」基盤の構築と組織横断的な協業に注力することで、複雑な金融データの自然言語クエリを可能にし、意思決定プロセスを劇的に加速させた。
キーポイント
AI 対応データ基盤への転換
高度な AI モデルの導入だけでなく、正確なビジネスインサイトを提供するためのセマンティックコンテキストとメタデータ管理を備えた「AI 対応データ」基盤の構築が不可欠であると認識し、アプローチを根本的にシフトした。
組織横断的な協働体制
データエンジニア、ビジネスアナリスト、コンプライアンス、セキュリティチームなど、従来分断されていた多様な専門家を巻き込み、各チームの知見を統合して仮想アナリストを構築した。
業務効率と意思決定の加速
従来の SQL 記述や数日かかるデータチームへの問い合わせに代わり、金融アナリストが自然言語で複雑なデータを即座にクエリできる環境を実現し、意思決定スピードを大幅に向上させた。
影響分析・編集コメントを表示
影響分析
この記事は、大規模言語モデル(LLM)の導入において「技術的ポテンシャル」だけでなく、「データガバナンス」と「組織文化の変革」が成否を分ける決定的要因であることを示す実証事例です。特に金融という厳格な規制と複雑なデータ構造を持つ業界において、AI 実装のロードマップを再定義する重要な指針となり、他業種でも同様の「データ基盤先行型」のアプローチが求められる契機となります。
編集コメント
単なるツール導入の成功談ではなく、AI 実装における「データ基盤」と「組織横断協働」の重要性を浮き彫りにした貴重なケーススタディです。技術選定以前に、いかにデータを意味ある形に整え、人間と機械をつなぐ土台を作るかが問われています。
Vanguard は、個人投資家、機関投資家、金融専門家に対して、幅広い投資商品、助言、退職金サービス、洞察を提供するグローバルな資産運用会社です。私たちは独自の投資家所有構造の下で運営し、明確な目的を掲げています:すべての投資家の味方となり、公平に扱い、投資成功の最良の機会を与えることです。
Vanguard の金融アナリストが複雑なデータセットを照会する必要があった際、彼らは苛立たしい現実と向き合っていました。基本的な質問であっても、複雑な SQL クエリの作成が必要であり、場合によってはデータチームからの応答に長時間を要することでした。この課題は Vanguard 固有のものではありません。対話型 AI はスケーラブルな解決策として、アナリストに即座の回答を提供します。しかし、対話型 AI を導入するには、適切な基盤モデルを選ぶだけでなく、AI 対応データインフラストラクチャが必要です。
本稿では、Vanguard が AI 対応データの8つの指針に焦点を当てて「Virtual Analyst」ソリューションを構築した方法、その実装を支えた AWS のサービス、そして達成された具体的なビジネス成果についてご紹介します。
課題:AI とエンタープライズデータの複雑性が交差する時
バンガードのアナリストとビジネス関係者は、意思決定のためにより迅速で直接的な金融データへのアクセスを求めていました。既存のワークフローでは SQL の専門知識とデータチームのサポートが必要であり、典型的なリクエストには数日かかることがありました。AI 駆動ツールが正確でビジネスに関連する洞察を生成できるようにするためには、データインフラストラクチャに意味論的コンテキストとメタデータ管理が必要です。
Virtual Analyst プロジェクトが進むにつれ、チームは効果的な会話型 AI を構築することは機械学習の課題ではなく、データアーキテクチャの課題であることを発見しました。最も洗練されたファウンデーションモデルであっても、信頼性の高い結果を提供するには適切なデータ基盤が必要です。この認識がアプローチの根本的な転換をもたらしました。AI の機能にのみ焦点を当てるのではなく、バンガードは彼らが「AI 対応データ」と呼ぶものを構築する必要があったのです。
協働の必要性:サイロの打破
Virtual Analyst を構築するには、多くの組織が struggling していることを実現する必要があります。つまり、従来サイロ化されていたチームを連携させることです。バンガードはデータエンジニア、ビジネスアナリスト、コンプライアンス担当者、セキュリティチーム、そしてビジネス関係者を集結させました。各チームが重要な専門知識をもたらしました:
- データエンジニアは技術インフラを理解していました
- ビジネスアナリストは財務指標の意味論的意味を知っていました
- コンプライアンスチームは規制要件への適合を支援しました
- ビジネスユーザーは、洞察をどのように活用するかという実世界の文脈を提供しました。
この異機能間の協働は、所有権モデル、意味定義、品質基準が明確に理解され、活性化された、よく定義された異機能オペレーティングモデルを開発することで、AI の基盤となりました。チームは、すべてのチームが理解し貢献できる明確な所有権モデル、意味定義、品質基準がなければ、AI ソリューションは良好な基盤を持たないことに気づきました。Virtual Analyst プロジェクトは、初期の AI 使用事例を超えて広範な恩恵をもたらす新しいプロセスとフレームワークのための触媒となりました。以下の図は、Virtual Analyst アーキテクチャのために開発された AI レディデータブループリントを示しています。
ケーススタディ:Virtual Analyst
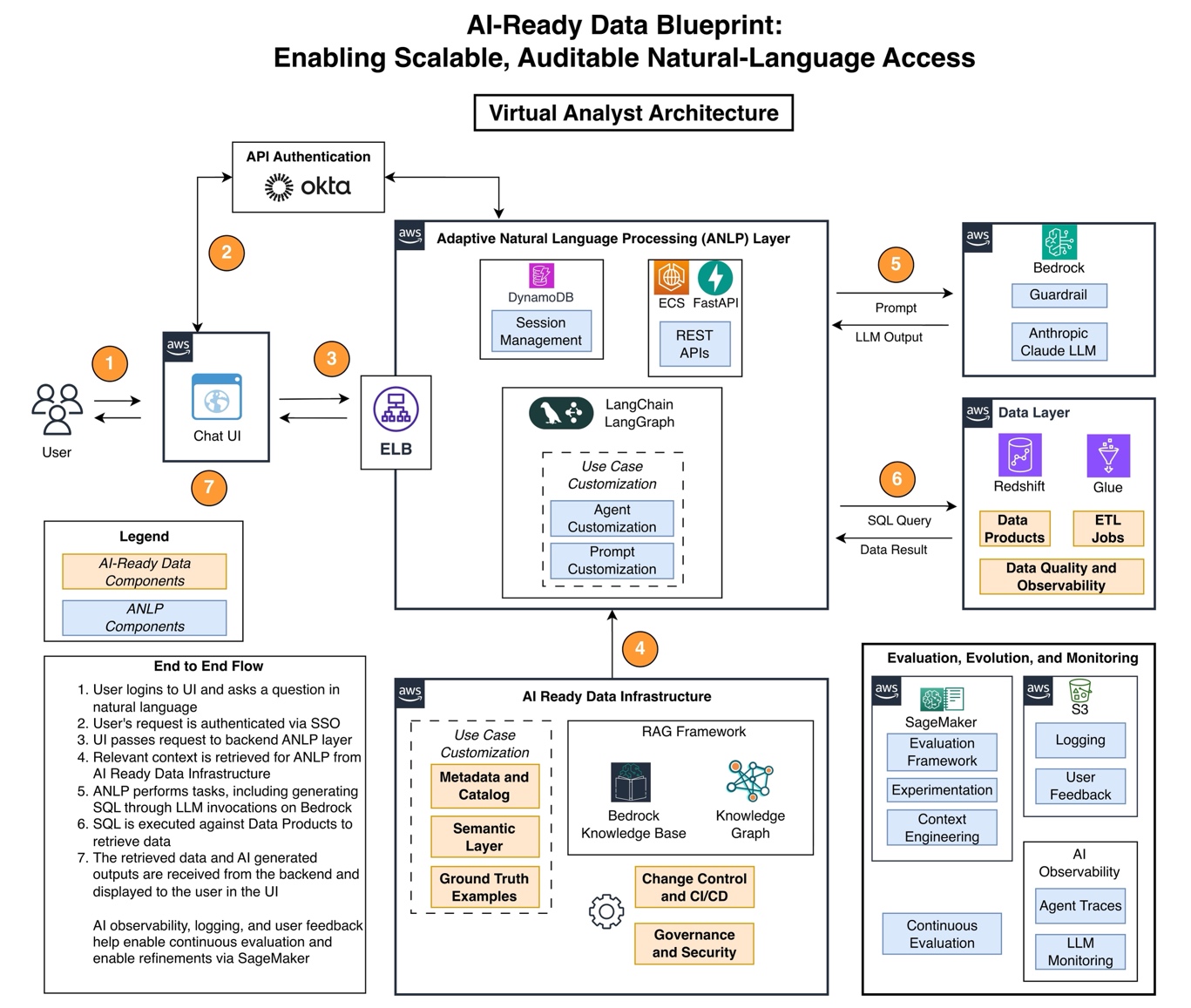 image
image
*このアーキテクチャは、単一の文脈固有の実装を反映しており、規範的というよりは例示的なものとして捉えるべきです。*
バンガードは、統合された包括的なサービススイートを提供する AWS を選択しました。AWS は、Amazon Redshift の高度な分析機能から、AWS Glue 上の自動データカタログ化、そして Amazon Bedrock におけるファウンデーションモデルへのアクセスに至るまで、AI 対応のデータアーキテクチャを構築するための豊富な機能セットを提供しています。さらに、AWS のセキュリティおよびコンプライアンス機能は、金融サービス業界が求める厳格な要件を満たしました。
Virtual Analyst は以下のサービスを利用しています:
- 自然言語理解を駆動するファウンデーションモデルのために Amazon Bedrock を使用
- バンガードの機密財務データを保護するため、AI の入力と出力をセキュリティで守るために Amazon Bedrock Guardrails を使用
- スケーラブルなコンピューティングインフラストラクチャのために Amazon Elastic Container Service (Amazon ECS) を使用
- 最小限のレイテンシで水平方向にスケーラブルなアーキテクチャ全体で会話履歴を保持するために Amazon DynamoDB を使用
- ストレージのために Amazon Simple Storage Service (Amazon S3) を使用
- 実験のために Amazon SageMaker を使用
- 集中型データウェアハウジングのために Amazon Redshift を使用
- データカタログ化および多数の抽出・変換・ロード(ETL)ジョブを駆動して正確なデータを統合するために AWS Glue を使用
AI対応データのための8つの指針
Virtual Analystの構築における彼らの旅を通じて、バンガードは既存の基盤となるデータ機能(例えばデータプラットフォーム、統合、相互運用性)を基礎としつつ、AI対応データを支援するために拡張する8つの指針を特定しました。これらの指針は、大規模な企業データでAIシステムを信頼性高く動作させることを試みる際に遭遇した現実世界の課題から生まれました。
明確なデータプロダクトおよび運用モデルの確立
高品質なデータには明確な責任所在が必要です。データプロダクトオーナーはビジネスとの整合性を担当し、エンジニアリング・スチュワードは技術的な品質を維持する責任を負います。データの鮮度や照合許容範囲に関するサービスレベル契約(SLA: Service-Level Agreements)と、下流の消費者向けの確立されたサポートモデルは、データプロダクトが再利用可能で適切に管理され、成果を提供するように設計されることを保証するのに役立ちます。各重要なデータ資産に対してビジネス側と技術側の両方のオーナーを割り当て、その責任範囲を文書化してください。
ガバナンスおよびセキュリティ対策の定義
企業アイデンティティ管理、ロールベースのデータアクセス制御、クエリレベルでの権限付与、保持ポリシーを確立するために、コンプライアンスチームおよびセキュリティチームと早期に連携してください。バンガードは規制要件を満たしつつビジネスのアジリティを支援するため、権限付与イベントのログ記録を実装しました。既存のデータアクセスポリシーを新しいAIシステムにマッピングし、必要に応じて行レベルおよび列レベルのセキュリティを実装してください。
技術的・業務的文脈を統合するメタデータカタログの構築
API を通じて両方を公開しつつ、技術メタデータと業務メタデータの双方を一元化する統一的なメタデータおよびカタログシステムを制御プレーンとして実装してください。多くの組織は完全な技術メタデータを維持している一方で、統合された業務文脈に欠陥があり、技術的実装とビジネス要件の間に不一致が生じています。技術メタデータには、テーブルやカラムの説明、データ型、変換におけるデータ系譜(data lineage)、類語およびカテゴリ指標、データセット間の関係マッピングが含まれます。この層は技術ドメインの専門家とデータ統制担当者が定義します。最も頻繁にアクセスされるデータセットから始め、他のデータソースへ展開する前に体系的にその技術メタデータを文書化してください。メタデータのバージョン管理を行い、発見可能性と精度を維持するためにマッピングの正確性を測定してください。業務メタデータは、特定属性に対するビジネス定義およびルール、ドメイン固有の用語やオントロジー(ontologies)、ビジネス所有権情報、利用文脈を捉えます。この層は、協働ガバナンスプロセスを通じてビジネスユーザーとドメイン専門家が貢献します。単一のカタログがこれら 2 つのメタデータタイプを統合し、AI システムが技術的構造とビジネスの意味の両方に合致する正確なクエリを生成できるようにします。
ビジネスメタデータを運用化するためのセマンティックレイヤーの実装
セマンティックレイヤーは、カタログで定義されたビジネスメタデータを、ユーザーフレンドリーな形式に変換することで運用化します。この実装層は、ビジネスの定義、ルール、オントロジーを実行可能なロジックへと翻訳し、組織が主要な指標や異なるデータ要素間の関係をどのように定義するかを標準化する役割を果たします。このレイヤーを整備することで、ビジネスアナリストは自然言語でデータの関係を記述できるようになり、それが構造化された SQL クエリとして解釈・変換されます。メタデータカタログに文書化されたビジネスの定義と関係性を強制することで、セマンティックレイヤーはクエリ全体の一貫性を高め、エラーのリスクを低減し、SQL の生成を効率化します。例えば、バンガード(Vanguard)のセマンティックレイヤーでは、顧客生涯価値(*customer lifetime value*)の定義を部署やシステム間で維持するために、ビジネスユーザーが定義したビジネスルールを実装しています。ビジネスステークホルダーと連携し、組織で最も頻繁に使用される上位 20 の指標について、その正確な定義と計算方法を文書化してください。
正解例の構築
正解例は、もう一つの重要な構成要素であり、ユーザーが問いかける可能性のある多様なクエリを示す「質問から SQL へのペア」のセットで構成されます。さまざまなユーザーの問い合わせとその正しいデータベース変換を説明する「質問から SQL へのペア」のライブラリを作成してください。ヴァンガードでは、3 つの目的を果たすために 50 を超える例証を集めました。1 つ目は AI モデルのための Few-shot プロンプト(モデルの応答を導くための例示となる質問と回答のペアを提供)です。2 つ目は評価ベンチマーク(既知の正解に対する精度を測定するもの)です。3 つ目は回帰テスト(新機能の変更が既存の機能を破損していないか検証するもの)です。これらの例は、AI システムが文脈内学習(in-context learning)を通じて学習することを支援します。まずは最も一般的なクエリパターンをカバーする 20〜30 の例から始め、発見されたユーザーフィードバックやエッジケースに基づいて拡張してください。
自動化されたデータ品質チェックの実装
ヴァンガードは、自動化されたチェックを通じてデータの信頼性を監視するための観測性ツール(observability tools)を設定しました:
- 分布チェック – データパターンの異常(値の急激な上昇や低下など)を検出します。
- 参照整合性チェック – テーブル間の関係が有効であることを検証します(例えば、すべての注文が有効な顧客を参照しているか)。
- 照合チェック – システム間でのデータの一貫性を確認します(例えば、ソースとウェアハウス間の合計値が一致するか)。
- 鮮度チェック – データ更新がスケジュール通りに発生することを確認します。
変更管理プロセスの確立
意味定義、例示データ、設定ファイルをバージョン管理下のコードとして扱ってください。変更管理および継続的インテグレーション・デプロイ(CI/CD)プロセスでは、意味定義、例示データ、パイプライン設定をコードとして扱い、段階的なデプロイとゲート付き承認による継続的インテグレーションを行います。このアプローチにより、KPI や SLA に影響を与える変更にはステークホルダーの承認が必要となりますが、改善内容の安全かつ迅速なデプロイも可能になります。データ環境の動的な性質を管理し、Virtual Analyst が変化に効果的に適応できることを確認するためには、確立された変更管理プロセスが不可欠です。Git などのバージョン管理システムにデータ定義の保存を開始し、本番環境への反映前にピアレビュー(同行レビュー)を必須とします。
継続的評価メカニズムの構築
最後に、継続的な評価および改善プロセスを用いて、節約されたアナリスト時間、インサイトまでの時間の短縮、ユーザー満足度、可能な場合は測定可能な収益や利益への影響といったビジネス指標を定義してください。システムは、例示データと意味の進化を図るための継続的回帰テストスイートとユーザーフィードバックループを維持し、モデルの劣化に対する自動アラートおよびビジネスへの影響追跡を行います。ビジネスステークホルダーにとって重要な 3〜5 の主要指標を定義し、AI システムの導入前にベースライン測定値を設定してください。
結果:実験から企業機能へ
AI 対応データへの注力は、測定可能な成果をもたらしました:
- Virtual Analyst の活用により、複雑な金融クエリに対するインサイトまでの時間を数日から数分に短縮
- SQL 知識を持たないビジネスユーザーがデータを直接アクセス可能に
- メタデータとセマンティックレイヤーの導入を通じて、AI が生成する SQL クエリの精度を向上
- 日常的な分析リクエストに対するデータチームの負荷を軽減
- 再利用可能なフレームワークを確立し、現在では複数の Vanguard ビジネスユニットで採用が進んでいる
今後の展望
Vanguard では、ナレッジグラフと検索拡張生成(RAG: Retrieval-Augmented Generation)が Virtual Analyst をさらに強化できる可能性を探る機会を検討しています。ナレッジグラフは、明確なエンティティ間の関係性、正規化された解決策、ドメイン横断的な文脈を提供し、曖昧な照合、結合推論、生成されたクエリの説明可能性を大幅に向上させる可能性があります。Amazon Bedrock Knowledge Bases を活用した RAG システムでは、例示ライブラリを活用して精度を高めつつ、モデルの品質と信頼性を段階的に改善するインテリジェントなフィードバックシステムの基盤を整えることができます。
結論:AI プロジェクトからデータ変革へ
本稿では、 Vanguard がデータ分析能力の変革を開始し、データを戦略的資産として活用するための新たな基準と働き方をどのように確立したかをご紹介しました。この AI プロジェクトは、組織が AI 機能を可能にするために必要な基盤を明らかにするものであり、これら8つの指針によって示されています。成功する AI とは単により優れたアルゴリズムのことではなく、企業規模で AI を支えるためのより良いデータ基盤を構築することです。AWS の統合されたデータおよびAI サービスと、規律あるデータプロダクトプラクティスを組み合わせることで、組織はモデルの能力を実際のビジネス成果に変換し、経営層が重要な意思決定に信頼して活用できるものへと変えることができます。
著者について

Ravi Narang
Ravi Narang は、人工知能(AI)、機械学習、データエンジニアリングにおいて25年以上の経験を持つデータおよびAI のリーダーです。Vanguard のAI/ML エンジニアリング部門長として、機関向けおよびアドバイザリー領域全体で意思決定を支援する高度な AI および生成AI ソリューションの設計と開発を主導しています。彼の専門分野は、データ準備、セマンティックモデリング、大規模言語モデル(LLM)運用、そしてエージェント型AI システムにまたがり、スケーラブルで信頼性が高く、高いインパクトを持つAI システムの構築に注力しています。

Rithvik Bobbili
Rithvik Bobbili は、バンガードの分析・インサイトセンターに所属する機械学習エンジニアスペシャリストです。バンガードでは 2 年以上勤務しており、従来の機械学習(Machine Learning)および生成 AI(Generative AI)の最新技術を活用した多数の AI/ML イニシアチブを支援してきました。彼はビジネス課題を解決するための生成 AI ソリューションの設計を専門としており、大規模言語モデル(LLM: Large Language Model)やエージェントなどを用いて、ビジネス価値を高める革新的なソリューションを提供しています。

Jiwon Yeom
Jiwon Yeom は、ニューヨーク市を拠点とする AWS のソリューションアーキテクトです。彼女は金融業界における生成 AI に注力しており、顧客がスケーラブルで安全かつ人間中心の AI ソリューションを構築できるよう支援することに情熱を燃やしています。仕事以外では、執筆活動や隠れた古書店巡りを趣味としています。

Matt Lanza
Matt Lanza は AWS のシニアソリューションアーキテクトです。彼は顧客が AWS 上でレジリエントな(耐障害性の高い)アーキテクチャを構築できるよう支援することに興味を持っています。機会があれば、運転を楽しむことも得意としています。
© [2026] *The Vanguard Group, Inc. All rights reserved. This material is provided for informational purposes only and is not intended to be investment advice or a recommendation to take any particular investment action.*
この文書は、情報提供を目的としてのみ提供されており、投資助言や特定の投資行動を取るよう推奨するものではありません。
原文を表示
Vanguard is a global investment management firm, offering a broad selection of investments, advice, retirement services, and insights to individual investors, institutions, and financial professionals. We operate under a unique, investor-owned structure and adhere to a straightforward purpose: To take a stand for all investors, to treat them fairly, and to give them the best chance for investing success.
When Vanguard’s financial analysts needed to query complex datasets, they faced a frustrating reality: even basic questions required writing intricate SQL queries and sometimes long response times from data teams. This challenge is not unique to Vanguard: conversational AI is a scalable solution, providing analysts immediate responses. However, deploying conversational AI requires more than choosing the right foundation model—it requires AI-ready data infrastructure.
In this post, you’ll learn how Vanguard built their Virtual Analyst solution by focusing on eight guiding principles of AI-ready data, the AWS services that powered their implementation, and the measurable business outcomes they achieved.
The challenge: When AI meets enterprise data complexity
Vanguard’s analysts and business stakeholders sought faster, more direct access to financial data for decision-making. The existing workflow required SQL expertise and data team support, with typical requests taking several days to fulfill. The data infrastructure required semantic context and metadata management to enable AI-powered tools to generate accurate, business-relevant insights.
As the Virtual Analyst project progressed, the team discovered that building effective conversational AI wasn’t a machine learning challenge—it was a data architecture challenge. The most sophisticated foundation models require proper data foundations to deliver reliable results. This realization led to a fundamental shift in approach: instead of focusing solely on AI capabilities, Vanguard needed to build what they termed *AI-ready data*.
The collaborative imperative: Breaking down silos
Building Virtual Analyst requires something many organizations struggle with: getting traditionally siloed teams to work together. Vanguard brought together data engineers, business analysts, compliance officers, security teams, and business stakeholders. Each team brought critical expertise:
- Data engineers understood the technical infrastructure
- Business analysts knew the semantic meaning of financial metrics
- Compliance teams helped meeting regulatory requirements
- Business users provided the real-world context for how they are going to use the insights.
This cross-functional collaboration became the foundation for AI by developing a well-defined, cross-functional operating model where ownership models, semantic definitions and quality standards were well understood and activated. The team realized that without clear ownership models, semantic definitions, and quality standards that all teams could understand and contribute to, the AI solution would not have a good foundation. The Virtual Analyst project served as a catalyst for new processes and frameworks that provide benefits far beyond the initial AI use case. The following figure shows the AI-ready data blueprint that was developed for the Virtual Analyst architecture.
Case Study: Virtual Analyst
*The architecture reflects a single, context-specific implementation, and it should be viewed as illustrative rather than prescriptive.*
Vanguard chose AWS for its comprehensive suite of integrated services. AWS offers a rich feature set for building AI-ready data architectures, from the advanced analytics capabilities of Amazon Redshift to the automated data cataloging on AWS Glue and the foundation model access on Amazon Bedrock. In addition, the security and compliance features of AWS met the stringent requirements of the financial services industry. The Virtual Analyst uses:
- Amazon Bedrock for foundation models that power natural language understanding
- Amazon Bedrock Guardrails to secure AI inputs and outputs to protect Vanguard’s sensitive financial data
- Amazon Elastic Container Service (Amazon ECS) for scalable compute infrastructure
- Amazon DynamoDB for conversation persistence across a horizontally scalable architecture with minimal latency
- Amazon Simple Storage Service (Amazon S3) for storage
- Amazon SageMaker for experimentation
- Amazon Redshift for centralized data warehousing
- AWS Glue for data cataloging while powering numerous extract, transform, load (ETL) jobs to consolidate accurate data
Eight guiding principles for AI-ready data
Through their journey building the Virtual Analyst, Vanguard identified eight guiding principles that build on existing foundational data capabilities (e.g. data platforms, integration, interoperability) and extend them to support AI-ready data. These principles emerged from real-world challenges encountered when trying to make AI systems work reliably with enterprise data at scale.
Establish clear data product and operating models
Higher quality data requires clear accountability. Data product owners are responsible for business alignment and engineering stewards should maintain technical quality. Service-level agreements (SLAs) for data freshness and reconciliation tolerance and established support models for downstream consumers will help ensure data products are reuseable, well-managed, and designed to deliver outcomes. Assign both business and technical owners to each critical data asset and document their responsibilities in writing.
Define governance and security measures
Work with your compliance and security teams early to establish enterprise identity management, role-based data access controls, query-level authorization, and retention policies. Vanguard implemented logging of authorization events to meet regulatory requirements while supporting business agility. Map your existing data access policies to the new AI system and implement row-level and column-level security where needed.
Build a metadata catalog that unifies technical and business context
Implement a unified metadata and catalog system as a control plane that centralizes both technical and business metadata while exposing them via APIs. Organizations often maintain complete technical metadata but lack integrated business context, creating misalignment between technical implementations and business requirements. Technical metadata includes table and column descriptions with data types, data lineage across transformations, synonyms and categorical indicators, and relationship mappings between datasets. Technical domain experts and data stewards define this layer. Start with your most frequently accessed datasets and systematically document their technical metadata before expanding to other data sources. Version your metadata and measure mapping accuracy to maintain discoverability and precision. Business metadata captures business definitions and rules for specific attributes, domain-specific terminology and ontologies, business ownership information, and usage context. Business users and domain experts contribute this layer through collaborative governance processes. A single catalog brings these two metadata types together, enabling AI systems to generate accurate queries that align with both technical structure and business meaning.
Implement a semantic layer to operationalize business metadata
The semantic layer operationalizes the business metadata defined in your catalog by transforming complex data structures into user-friendly formats. This implementation layer translates business definitions, rules, and ontologies into executable logic that standardizes how your organization defines key metrics and the relationships between different data elements. With this layer in place, business analysts can express their understanding of data relationships in natural language that can be interpreted and translated into structured SQL queries. By enforcing the business definitions and relationships documented in your metadata catalog, the semantic layer enhances consistency across queries, reduces the risk of errors, and streamlines SQL generation. For example, Vanguard’s semantic layer maintains the definition of *customer lifetime value* across departments and systems by implementing the business rules defined by their business users. Work with business stakeholders to document the top 20 metrics your organization uses most frequently, including their precise definitions and calculation methods.
Develop ground truth examples
Ground truth examples form another critical component, comprising a set of question-to-SQL pairs that illustrate various queries users might ask. Create a library of question-to-SQL pairs that illustrate various user queries and their correct database translations. Vanguard built a collection of over 50 exemplars that serve three purposes: few-shot prompts for the AI model (providing example question-answer pairs to guide the model’s responses), evaluation benchmarks (measuring accuracy against known correct answers), and regression testing (verifying new changes don’t break existing functionality). These examples help the AI system learn through in-context learning. Start with 20–30 examples covering your most common query patterns, then expand based on user feedback and edge cases you discover.
Implement automated data quality checks
Vanguard set up observability tools to monitor data reliability through automated checks:
- Distributional checks – Detecting anomalies in data patterns (such as sudden spikes or drops in values)
- Referential checks – Verifying that relationships between tables remain valid (for example, every order references a valid customer)
- Reconciliation checks – Confirming data consistency across systems (for example, totals match between source and warehouse)
- Freshness checks – Confirming data updates occur on schedule
Establish change control processes
Treat your semantic definitions, exemplars, and configurations as code under version control. Change control and continuous integration and deployment (CI/CD) processes treat semantic definitions, exemplars, and pipeline configurations as code under continuous integration with staged deployments and gated approvals. This approach requires stakeholder sign-off for changes that affect KPIs or SLAs while enabling safe, rapid deployment of improvements. An established change control process is essential for managing the dynamic nature of the data landscape, confirming Virtual Analyst can adapt to changes effectively. Start storing data definitions in a version control system such as Git, and require peer review before changes go to production.
Create continuous evaluation mechanisms
Finally, use continuous evaluation and improvement processes define business metrics including analyst hours saved, time-to-insight improvements, user satisfaction, and measurable revenue or profit impacts where possible. The system maintains continuous regression suites and user feedback loops to evolve examples and semantics, with automated alerts for model degradation and business impact tracking. Define 3–5 key metrics that matter to your business stakeholders and establish baseline measurements before launching your AI system.
Results: From experiment to enterprise capability
The focus on AI-ready data delivered measurable outcomes:
- Reduced time-to-insight from days to minutes for complex financial queries with the use of the Virtual Analyst
- Enabled business users to access data independently without SQL knowledge
- Achieved high accuracy in AI-generated SQL queries through metadata and semantic layer implementation
- Decreased data team workload for routine analytical requests
- Established a reusable framework now being adopted across multiple Vanguard business units.
Looking forward
Vanguard is evaluating opportunities to explore how knowledge graphs and Retrieval-Augmented Generation (RAG) can further enhance Virtual Analyst. Knowledge graphs could provide explicit entity relationships, canonical resolution, and cross-domain context that materially improves fuzzy matching, join inference, and explainability for generated queries. RAG systems using Amazon Bedrock Knowledge Bases can use the exemplar library to increase accuracy while paving the way for intelligent feedback systems that will progressively refine model quality and reliability.
Conclusion: From AI project to data transformation
In this post, we showed you how Vanguard established new standards and ways of working that began a transformation of its data analytics capabilities, leveraging data as a strategic asset. What began as an AI project revealed the groundwork an organization needs to enable AI capabilities, as shown with these eight guiding principles. Successful AI isn’t just about better algorithms—it’s about building better data foundations to support AI at enterprise scale. The combination of the integrated data and AI services of AWS, coupled with disciplined data product practices, helps organizations convert model capabilities into dependable business outcomes that executives can trust for critical decision making.
About Authors
Ravi Narang
Ravi Narang is a data and AI leader with over 25 years of experience in artificial intelligence, machine learning, and data engineering. As Head of AI/ML Engineering at Vanguard, he leads the design and development of advanced AI and generative AI solutions that power intelligent decision-making across institutional and advisory domains. His expertise spans data readiness, semantic modeling, large language model operations, and agentic AI systems, focusing on building scalable, trustworthy, and high-impact AI systems.
Rithvik Bobbili
Rithvik Bobbili is a Machine Learning Engineer Specialist within the Center for Analytics and Insights at Vanguard. He has been at Vanguard for over two years and has supported numerous AI/ML initiatives powered by both traditional machine learning as well as the latest advancements in generative AI. He specializes in designing generative AI solutions to solve business problems, working with LLMs, agents, and more to deliver innovative solutions that drive business value.
Jiwon Yeom
Jiwon Yeom is a Solutions Architect at AWS, based in New York City. She focuses on generative AI in the financial services industry and is passionate about helping customers build scalable, secure, and human-centered AI solutions. Outside of work, she enjoys writing and exploring hidden bookstores.
Matt Lanza
Matt Lanza is a Principal Solutions Architect at AWS. He is interested in helping customers build resilient architecture on AWS. He drives fast when he gets a chance.
© [2026] *The Vanguard Group, Inc. All rights reserved. This material is provided for informational purposes only and is not intended to be investment advice or a recommendation to take any particular investment action.*
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み