RingがAmazon Bedrock Knowledge Basesでグローバルカスタマーサポートを拡張する方法
RingはAmazon Bedrock Knowledge Basesを活用したRAGベースの多言語サポートチャットボットを構築し、リージョンごとのインフラ展開を不要にすることで、追加ロケールへの拡張コストを21%削減しつつ、10の国際リージョンで一貫した顧客体験を維持した。
キーポイント
RAGベースの多言語サポートシステム構築
RingはAmazon Bedrock Knowledge Basesを使用して、Retrieval-Augmented Generation(RAG)ベースのサポートチャットボットを構築し、ルールベースの従来システムの限界を克服した。
コスト削減とスケーラビリティの実現
リージョンごとのインフラ展開を不要にすることで、追加ロケールへの拡張コストを21%削減し、10の国際リージョンへの効率的な拡張を実現した。
メタデータ駆動フィルタリングによる地域特化対応
メタデータ駆動フィルタリングを実装し、リージョン固有のコンテンツを適切に提供することで、多様な顧客問い合わせに対応できるシステムを構築した。
コンテンツ管理ワークフローの分離
コンテンツ管理をインジェスト、評価、プロモーションのワークフローに分離し、効率的な運用を実現した。
地域コンテンツフィルタリングの設定
Amazon Bedrock Knowledge Basesでは、ベクター検索時にcontentLocaleキーを使用して特定の地域(例:en-GB)のコンテンツのみをフィルタリングする設定が可能です。
検索結果数の制御
numberOfResultsパラメータで取得する検索結果の数を指定でき、例では10件に設定されています。
ベクトルストアの選択肢と考慮点
Amazon Bedrock Knowledge Basesでは、Amazon OpenSearch Serverless(高度な検索機能向け)とAmazon S3 Vectors(コスト効率重視)の2つの主要なベクトルストアオプションがあり、ユースケースに応じて選択する必要がある。
影響分析・編集コメントを表示
影響分析
この記事は、大規模企業が生成AI技術を実務に適用する具体的な成功事例を示しており、特にグローバル展開におけるコスト削減と顧客体験の一貫性維持というビジネス課題への解決策を提供している。RAG技術の実用化が進む中で、AWSプラットフォーム上での実装パターンとして参考になる内容である。
編集コメント
AWS公式ブログからの技術事例紹介であり、営業PR色が強いが、RAG技術の実践的応用とグローバル展開における具体的な数値(21%コスト削減)を示している点で参考になる。
num_results = 10
market = "en-GB"
knowledge_base_id = "A2BCDEFGHI"
user_text = "ドアベルのバッテリー交換方法を教えてください"
# リージョン別コンテンツフィルタリングの設定
vector_search_config = {"numberOfResults": num_results}
vector_search_config["filter"] = {
"equals": {
"key": "contentLocale",
"value": market
}
}
# Amazon Bedrock ナレッジベースからの検索実行
response = boto3.client("bedrock-agent-runtime").retrieve(
knowledgeBaseId=knowledge_base_id,
retrievalQuery={"text": user_text},
retrievalConfiguration={
"vectorSearchConfiguration": vector_search_config,
},
)原文を表示
*This post is cowritten with David Kim, and Premjit Singh from Ring.*
Scaling self-service support globally presents challenges beyond translation. In this post, we show you how Ring, Amazon’s home security subsidiary, built a production-ready, multi-locale Retrieval-Augmented Generation (RAG)-based support chatbot using Amazon Bedrock Knowledge Bases. By eliminating per-Region infrastructure deployments, Ring reduced the cost of scaling to each additional locale by 21%. At the same time, Ring maintained consistent customer experiences across 10 international Regions.
In this post, you’ll learn how Ring implemented metadata-driven filtering for Region-specific content, separated content management into ingestion, evaluation and promotion workflows, and achieved cost savings while scaling up. The architecture described in this post uses Amazon Bedrock Knowledge Bases, Amazon Bedrock, AWS Lambda, AWS Step Functions, and Amazon Simple Storage Service (Amazon S3). Whether you’re expanding support operations internationally or looking to optimize your existing RAG architecture, this implementation provides practical patterns you can apply to your own multi-locale support systems.
The support evolution journey for Ring
Customer support at Ring initially relied on a rule-based chatbot built with Amazon Lex. While functional, the system had limitations with predefined conversation patterns that couldn’t handle the diverse range of customer inquiries. During peak periods, 16% of interactions escalated to human agents, and support engineers spent 10% of their time maintaining the rule-based system. As Ring expanded across international locales, this approach became unsustainable.
Requirements for a RAG-based support system
Ring faced a challenge: how to provide accurate, contextually relevant support across multiple international locales without creating separate infrastructure for each Region. The team identified four requirements that would inform their architectural approach.
- Global content localization
The international presence of Ring required more than translation. Each territory needed Region-specific product information, from voltage specifications to regulatory compliance details, provided through a unified system. Across the UK, Germany, and eight other locales, Ring needed to handle distinct product configurations and support scenarios for each Region.
- Serverless, managed architecture
Ring wanted their engineering team focused on improving customer experience, not managing infrastructure. The team needed a fully managed, serverless solution.
- Scalable knowledge management
With hundreds of product guides, troubleshooting documents, and support articles constantly being updated, Ring needed vector search technology that could retrieve precise information from a unified repository. The system had to support automated content ingestion pipelines so that the Ring content team could publish updates that would become available across multiple locales without manual intervention.
- Performance and cost optimization
The average end-to-end latency requirement for Ring was 7–8 seconds and performance analysis revealed that cross-Region latency accounted for less than 10% of total response time. This finding allowed Ring to adopt a centralized architecture rather than deploying separate infrastructure in each Region, which reduced operational complexity and costs.
To address these requirements, Ring implemented metadata-driven filtering with content locale tags. This approach serves Region-specific content from a single centralized system. For their serverless requirements, Ring chose Amazon Bedrock Knowledge Bases and Lambda, which removed the need for infrastructure management while providing automatic scaling.
Overview of solution
Ring designed their RAG-based chatbot architecture to separate content management into two core processes: Ingestion & Evaluation and Promotion. This two-phase approach allows Ring to maintain continuous content improvement while keeping production systems stable.
Ingestion and evaluation workflow
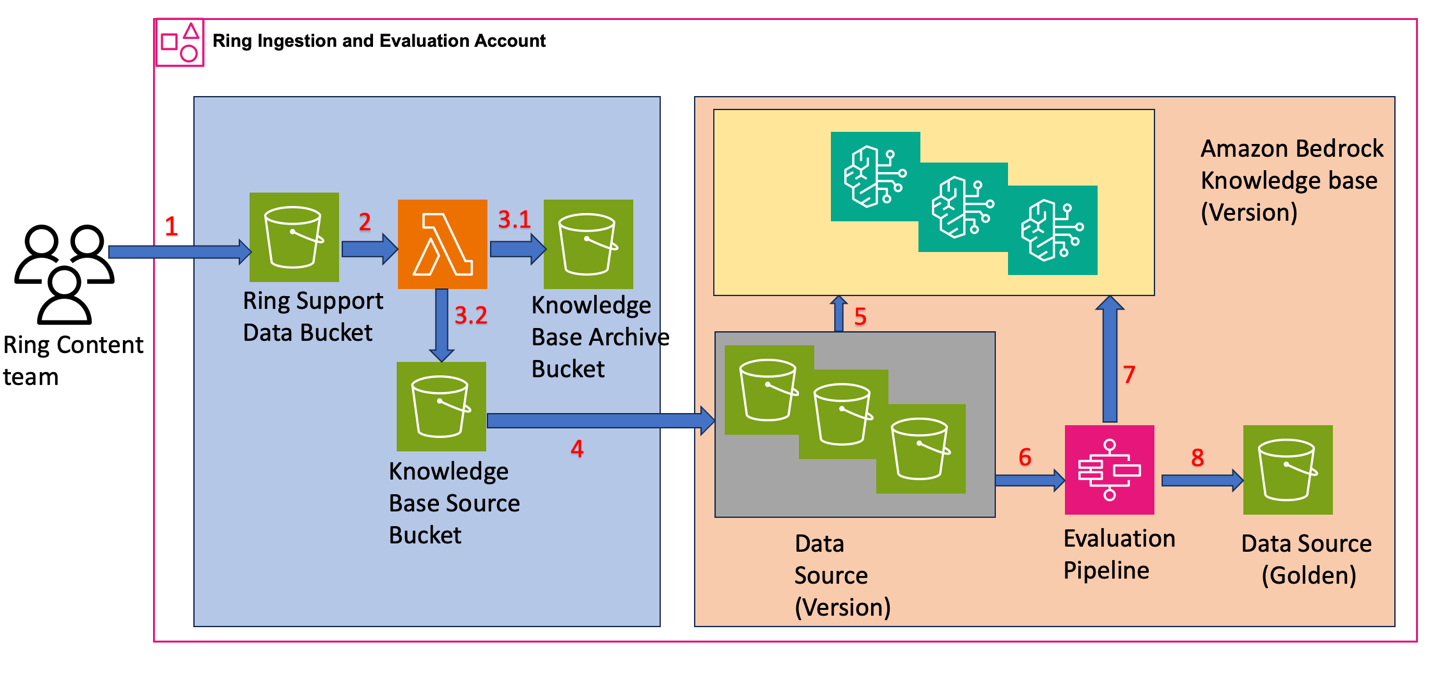
*Figure 1:** Architecture diagram showing the Ring ingestion and evaluation workflow with Step Functions orchestrating daily knowledge base creation, evaluation, and quality validation using Knowledge Bases and S3 storage.*
- Content upload – The Ring content team uploads support documentation, troubleshooting guides, and product information to Amazon S3. The team structured the S3 objects with content in encoded format and metadata attributes. For example, a file for the content “Steps to Replace the doorbell battery” has the following structure:
{
"properties": {
"slug": "abcde",
"contentLocale": "en-GB", # unique identifier
"sourceFormat": "md", # locale information
"metadataAttributes": {
"group": "Service",
"slug": "abcde",
"contentLocale": "en-GB"
},
"content": "U3RlcHMgdG8gUmVwbGFjZSB0aGUgZG9vcmJlbGwgYmF0dGVyeTo=
VXNlIHRoZSBpbmNsdWRlZCBzZWN1cml0eSBzY3Jld2RyaXZlciB0byByZW1vdmUgd
GhlIHNlY3VyaXR5IHNjcmV3IGxvY2F0ZWQgb24gdGhlIGJvdHRvbSBvZiB0aGUgZm
FjZXBsYXRlCgpSZW1vdmUgdGhlIGZhY2VwbGF0ZSBieSBwcmVzc2luZyBpbiBvbiB
0aGUgc2lkZXMgYW5kIGNhcmVmdWxseSBwdWxsaW5nIGl0IG91dCBhbmQgb2ZmCgpS
ZW1vdmUgdGhlIGJhdHRlcnkgZnJvbSB0aGUgZG9vcmJlbGwKCkNvbm5lY3QgdGhlI
GNoYXJnaW5nIGNhYmxlIHRvIHRoZSBiYXR0ZXJ5J3MgY2hhcmdpbmcgcG9ydAoKQ2h
hcmdlIHVudGlsIG9ubHkgdGhlIGdyZWVuIGxpZ2h0IHJlbWFpbnMgbGl0ICh3aGlsZ
SBjaGFyZ2luZywgeW91J2xsIHNlZSBib3RoIGEgc29saWQgZ3JlZW4gYW5kIGFtYmV
yIGxpZ2h0KQoKUmUtaW5zZXJ0IHRoZSBjaGFyZ2VkIGJhdHRlcnkgaW50byB0aGUgZ
G9vcmJlbGwKCkRlLWF0dGFjaCB0aGUgZmFjZXBsYXRlCgpTZWN1cmUgd2l0aCB0aGU
gc2VjdXJpdHkgc2NyZXc= # base64 encoded
}
}- Content processing – Ring configured Amazon S3 bucket event notifications with Lambda as the target to automatically process uploaded content.
- Raw and processed content storage The Lambda function performs two key operations:
Copies the raw data to the Knowledge Base Archive Bucket
- Extracts metadata and content from raw data, storing them as separate files in the Knowledge Base Source Bucket with contentLocale classification (for example, {locale}/Service.Ring.{Upsert/Delete}.{unique_identifier}.json)
For the doorbell battery example, the Ring metadata and content files have the following structure:
{locale}/Service.Ring.{Upsert/Delete}.{unique_identifier}.metadata.json
{
"metadataAttributes" : {
"group": "Service",
"slug": "abcde",
"contentLocale": "en-GB"
}
}{locale}/Service.Ring.{Upsert/Delete}.{unique_identifier}.json
{
"content": "Steps to Replace the doorbell battery:
Use the included security screwdriver to remove the security screw located on the bottom of the faceplate
Remove the faceplate by pressing in on the sides and carefully pulling it out and off
Remove the battery from the doorbell
Connect the charging cable to the battery's charging port
Charge until only the green light remains lit (while charging, you'll see both a solid green and amber light)
Re-insert the charged battery into the doorbell
Re-attach the faceplate
Secure with the security screw
}- Daily Data Copy and Knowledge Base Creation
Ring uses AWS Step Functions to orchestrate their daily workflow that:
- Copies content and metadata from the Knowledge Base Source Bucket to Data Source (Version)
- Creates a new Knowledge Base (Version) by indexing the daily bucket as data source for vector embedding
Each version maintains a separate Knowledge Base, giving Ring independent evaluation capabilities and straightforward rollback options.
- Daily Evaluation Process
The AWS Step Functions workflow continues using evaluation datasets to:
- Run queries across Knowledge Base versions
- Test retrieval accuracy and response quality to compare performance between versions
- Publish performance metrics to Tableau dashboards with results organized by contentLocale
- Quality Validation and Golden Dataset Creation
Ring uses the Anthropic Claude Sonnet 4 large language model (LLM)-as-a-judge to:
- Evaluate metrics across Knowledge Base versions to identify the best-performing version
- Compare retrieval accuracy, response quality, and performance metrics organized by contentLocale
- Promote the highest-performing version to Data Source (Golden) for production use
This architecture supports rollbacks to previous versions for up to 30 days. Because content is updated approximately 200 times per week, Ring decided not to maintain versions beyond 30 days.
Promotion workflow: customer-facing
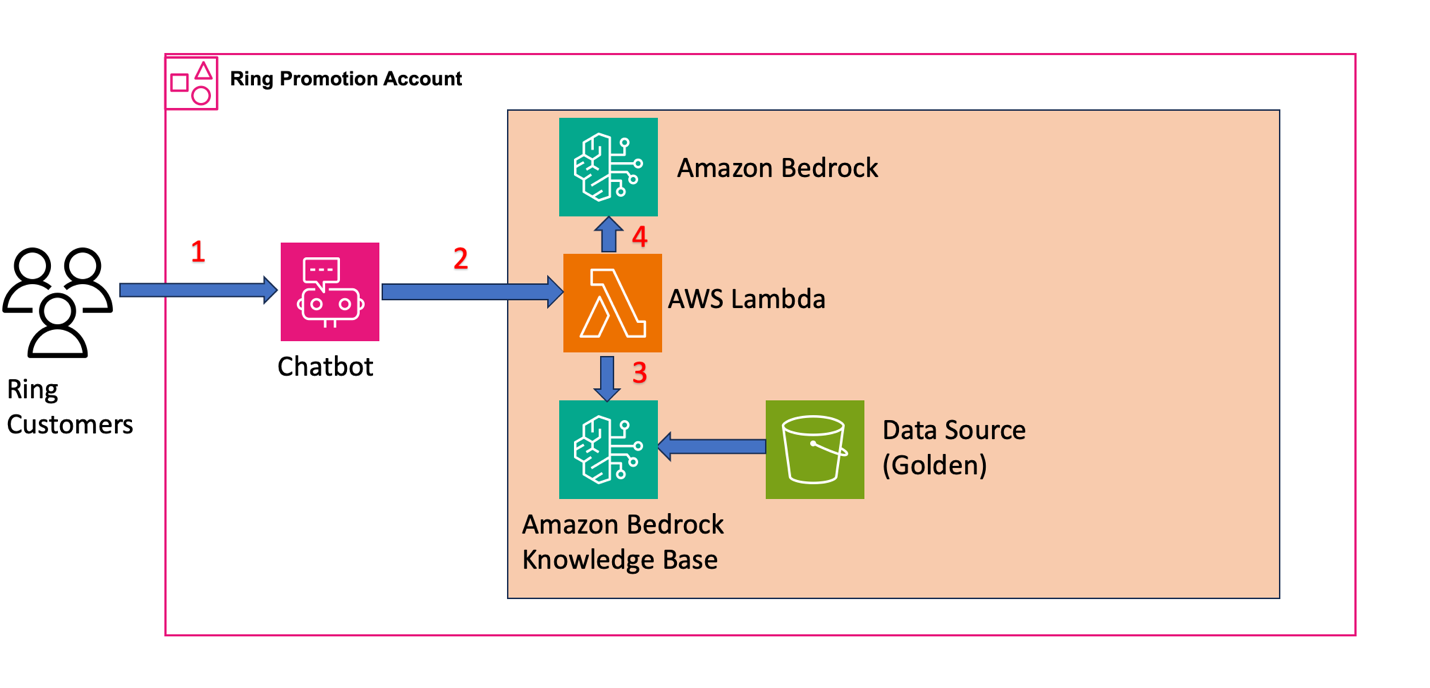
*Figure 2:** Architecture diagram showing the Ring production chatbot system where customer queries flow through AWS Lambda to retrieve context from Knowledge Bases and generate responses using foundation models*
- Customer interaction – Customers initiate support queries through the chatbot interface. For example, a customer query for the battery replacement scenario looks like this:
{
"text": "How can I replace the doorbell battery?",
"market": "en-GB"
}- Query orchestration and knowledge retrieval
Ring configured Lambda to process customer queries and retrieve relevant content from Amazon Bedrock Knowledge Bases. The function:
- Transforms incoming queries for the RAG system
- Applies metadata filtering with contentLocale tags using equals operator for precise Regional content targeting
- Queries the validated Golden Data Source to retrieve contextually relevant content
Here’s the sample code Ring uses in AWS Lambda:
## Metadata Filtering for Regional Content Targeting
num_results = 10
market = "en-GB"
knowledge_base_id = "A2BCDEFGHI"
user_text = "How can I replace the doorbell battery?"
# Configure Regional content filtering
vector_search_config = {"numberOfResults": num_results}
vector_search_config["filter"] = {
"equals": {
"key": "contentLocale",
"value": market
}
}
# Run Amazon Bedrock Knowledge Base search
response = boto3.client("bedrock-agent-runtime").retrieve(
knowledgeBaseId=knowledge_base_id,
retrievalQuery={"text": user_text},
retrievalConfiguration={
"vectorSearchConfiguration": vector_search_config,
},
)- Response generation
In the Lambda function, the system:
- Sorts the retrieved content based on relevance score and selects the highest-scoring context
- Combines the top-ranked context with the original customer query to create an augmented prompt
- Sends the augmented prompt to LLM on Amazon Bedrock
- Configures locale-specific prompts for each contentLocale
- Generates contextually relevant responses returned through the chatbot interface
Other considerations for your implementation
When building your own RAG-based system at scale, consider these architectural approaches and operational requirements beyond the core implementation:
Vector store selection
The Ring implementation uses Amazon OpenSearch Serverless as the vector store for their knowledge bases. However, Amazon Bedrock Knowledge Bases also supports Amazon S3 Vectors as a vector store option. When choosing between these options, consider:
- Amazon OpenSearch Serverless: Provides advanced search capabilities, real-time indexing, and flexible querying options. Best suited for applications requiring complex search patterns or when you need additional OpenSearch features beyond vector search.
- Amazon S3 vectors: Offers a more cost-effective option for straightforward vector search use cases. S3 vector stores provide automatic scaling, built-in durability, and can be more economical for large-scale deployments with predictable access patterns.
In addition to these two options, AWS supports integrations with other data store options, including Amazon Kendra, Amazon Neptune Analytics, and Amazon Aurora PostgreSQL. Evaluate your specific requirements around query complexity, cost optimization, and operational needs when selecting your vector store. The prescriptive guidance provides a good starting point to evaluate vector stores for your RAG use case.
Versioning architecture considerations
While Ring implemented separate Knowledge Bases for each version, you might consider an alternative approach involving separate data sources for each version within a single knowledge base. This method leverages the x-amz-bedrock-kb-data-source-id filter parameter to target specific data sources during retrieval:
vector_search_config["filter"] = {
"equals": {
"key": "x-amz-bedrock-kb-data-source-id",
"value": ''
}
}
# Execute Bedrock Knowledge Base search
response = boto3.client("bedrock-agent-runtime").retrieve(
knowledgeBaseId=knowledge_base_id,
retrievalQuery={"text": user_text},
retrievalConfiguration={
"vectorSearchConfiguration": vector_search_config,
},
)When choosing between these approaches, weigh these specific trade-offs:
- Separate knowledge bases per version (the approach that Ring uses): Provides data source management and cleaner rollback capabilities, but requires managing more knowledge base instances.
- Single knowledge base with multiple data sources: Reduces the number of knowledge base instances to maintain, but introduces complexity in data source routing logic and filtering mechanisms, plus requires maintaining separate data stores for each data source ID.
Disaster recovery: Multi-Region deployment
Consider your disaster recovery requirements when designing your RAG architecture. Amazon Bedrock Knowledge Bases are Regional resources. To achieve robust disaster recovery, deploy your complete architecture across multiple Regions:
- Knowledge bases: Create Knowledge Base instances in multiple Regions
- Amazon S3 buckets: Maintain cross-Region copies of your Golden Data Source
- Lambda functions and Step Functions workflows: Deploy your orchestration logic in each Region
- Data synchronization: Implement processes to keep content synchronized across Regions
The centralized architecture serves its traffic from a single Region, prioritizing cost optimization over multi-region deployment. Evaluate your own Recovery Time Objective (RTO) and Recovery Point Objective (RPO) requirements to determine whether a multi-Region deployment is necessary for your use case.
Foundation model throughput: Cross-Region inference
Amazon Bedrock foundation models are Regional resources with Regional quotas. To handle traffic bursts and scale beyond single-Region quotas, Amazon Bedrock supports cross-Region inference (CRIS). CRIS automatically routes i
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み