Amazon Bedrock におけるプログラムによるツール呼び出しの実装
AWS は、LLM の外部ツール呼び出しにおける遅延とトークン消費を削減する「プログラムティック・ツール・コールリング(PTC)」の実装方法を Amazon Bedrock で紹介し、従来のラウンドトリップ型ワークフローの課題解決を示した。
キーポイント
従来のツール呼び出しのボトルネック
各ツール呼び出しごとにモデルへの完全な往復が必要であり、中間結果がコンテキストウィンドウを埋め尽くすことで遅延とトークンコストが増大する。
PTC(プログラムティック・ツール・コールリング)の仕組み
モデルは一度だけコード(Python 等)を生成し、サンドボックス環境でループや条件分岐を含む複雑な処理を実行させる。最終結果のみがモデルに戻されるため、効率性が劇的に向上する。
Amazon Bedrock での実装アプローチ
最大限の制御性を求める ECS 上の Docker サンドボックス、管理型サービスである AgentCore Code Interpreter、および Anthropic SDK に準拠したプロキシ経由の 3 つの実装パターンを提示している。
並列処理による効率化
asyncio.gather を使用して全従業員の経費データを並列に取得し、処理時間を短縮しています。
動的な予算チェックロジック
旅費合計が既定の閾値(5000)を超えた場合にのみカスタム予算情報を取得し、個別の制限額と比較する条件分岐を実装しています。
コンテキストウィンドウの最適化
モデルに渡されるのは最終的な要約のみであり、2,000件以上の生データや中間処理はPython側で完結し、推論コストとトークン使用量を大幅に削減します。
セルフホスト型 PTC の利点
マネージド環境と比較して、モデルの選択自由度が高い(Bedrock 対応)、サンドボックスのカスタマイズやセキュリティポリシー設定が可能、そしてデータとコード実行を自アカウント内に閉じ込められる点が挙げられます。
影響分析・編集コメントを表示
影響分析
この記事は、LLM を活用した複雑な業務自動化におけるコストとパフォーマンスのボトルネックを解消する具体的なアーキテクチャを示しており、実務レベルでの LLM 応用開発に即座に適用可能な知見を提供します。特に、大量データを扱うワークフローやプライバシー要件が厳しい環境において、従来のツール呼び出しパラダイムから PTC への移行を促す重要な指針となります。
編集コメント
LLM の実用化において、単に「賢い」だけでなく「効率的に動く」ことが求められる中、PTC という新しいパラダイムを AWS が体系的に提示した点は非常に重要です。特にコンテキストウィンドウの制限とコスト問題を解決する手法として、開発者がすぐに検討すべきアーキテクチャと言えます。
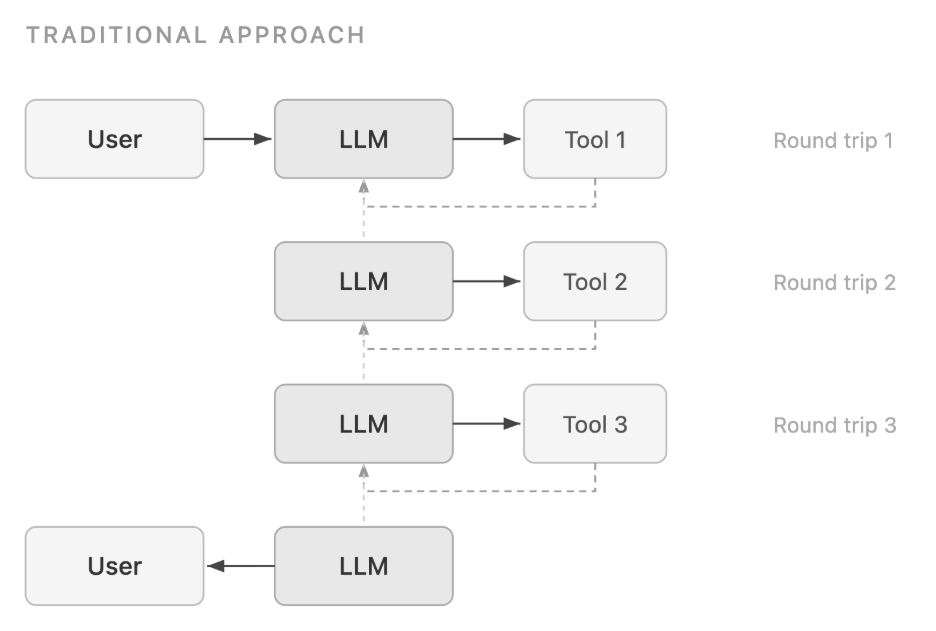
プログラムによるツール呼び出し(PTC)は、大規模言語モデル(LLM)が外部ツールと相互作用する方法におけるパラダイムシフトです。従来のツール呼び出しワークフローでは、各ツールの呼び出しにはモデルへの完全な往復通信が必要です。モデルがツールを呼び出し、結果を受け取り、それについて推論し、次のツールを呼び出すというプロセスが続きます。複数のツール呼び出しを伴うワークフローの場合、このアプローチは、すべての中間結果がモデルのコンテキストウィンドウを経由しなければならないため、遅延とトークン消費が増幅される原因となります。
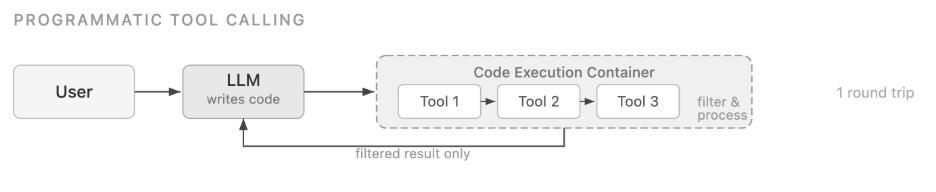
PTC は異なるアプローチを採用しています。ツール呼び出しを一つずつオーケストレーションするのではなく、モデルはコード(通常は Python)を記述し、サンドボックス化された実行環境内で複数のツールをプログラム的に呼び出します。このコードにはループ、条件分岐、フィルタリング、集計ロジックを含めることができます。モデルはコードを生成するために一度だけサンプリングされ、その後、実行環境がツールの呼び出しを処理し、最終的に処理された結果のみがモデルのコンテキストに返されます。これにより、マルチツールワークフローにおける遅延とトークン使用量が劇的に削減されます。PTC は、大規模なデータ処理、正確な数値計算、多段階プロセスのオーケストレーション、および生データがモデルのコンテキストに入らないことが求められるプライバシー重視のシナリオにおいて特に効果的です。
PTC は元々特定のベンダーに依存した機能として始まりましたが、その背後にあるパターン——モデルがコードを生成し、サンドボックスで実行し、最終的な出力のみがコンテキストに戻ってくる——はモデル非依存です。本稿では、Amazon Bedrock 上で PTC を実装する3つの方法を紹介します:最大限の制御性を得るための ECS 上のセルフホスト型 Docker サンドボックス、Amazon Bedrock AgentCore Code Interpreter を用いたマネージドソリューション、そしてその開発者体験を好むチーム向けのプロキシを介した Anthropic SDK 互換パスです。
従来のツール呼び出しにおけるボトルネック
例を考えてみましょう:「どのエンジニアリングチームのメンバーが第3四半期の旅行予算を超えたか?」従来のツール呼び出し(並列関数呼び出しがないと仮定)では、モデルは以下の手順を踏む必要があります:
- チームメンバーリストを取得するためのツールを呼び出す——20人分。
- 各人の経費記録を取得するためのツールを呼び出す——20回の別々のツール呼び出しで、それぞれ50〜100行の項目が返されます。
- 予算閾値を取得するための追加ツールを呼び出す。
- 2,000件を超える経費レコードをコンテキストウィンドウ内に受け取る。
- 自然言語で完全なデータセットを推論し、フィルタリング、比較、要約を行う。
これらの各ツール呼び出しには、モデルを経由する完全な往復通信が必要です。モデルはツール呼び出しを生成し、一時停止して結果を受け取り、それについて推論を行い、次のツール呼び出しを生成します。これが3つの複合的な問題を生み出します:
- トークン消費量:最終的にモデルが破棄する数千件の経費明細を含むすべての中間結果が、コンテキストウィンドウを通過します。
- レイテンシ(遅延):各ツール呼び出しには完全なモデル推論サイクルが必要です。20 回の順次ツール呼び出しは、20 回の推論往復を意味します。
- 精度:自然言語で数千件のレコードのフィルタリング、集約、比較を行うよう言語モデルに依頼することはエラーが発生しやすいものです。これらは数行の Python コードであれば正確に処理できる操作です。
PTC がこれを解決する方法
PTC はこのパターンを逆転させます。モデルは単一の Python コードブロックを作成し、そこでツール呼び出しを調整し、結果を処理して最終出力のみを返します。
 image
image 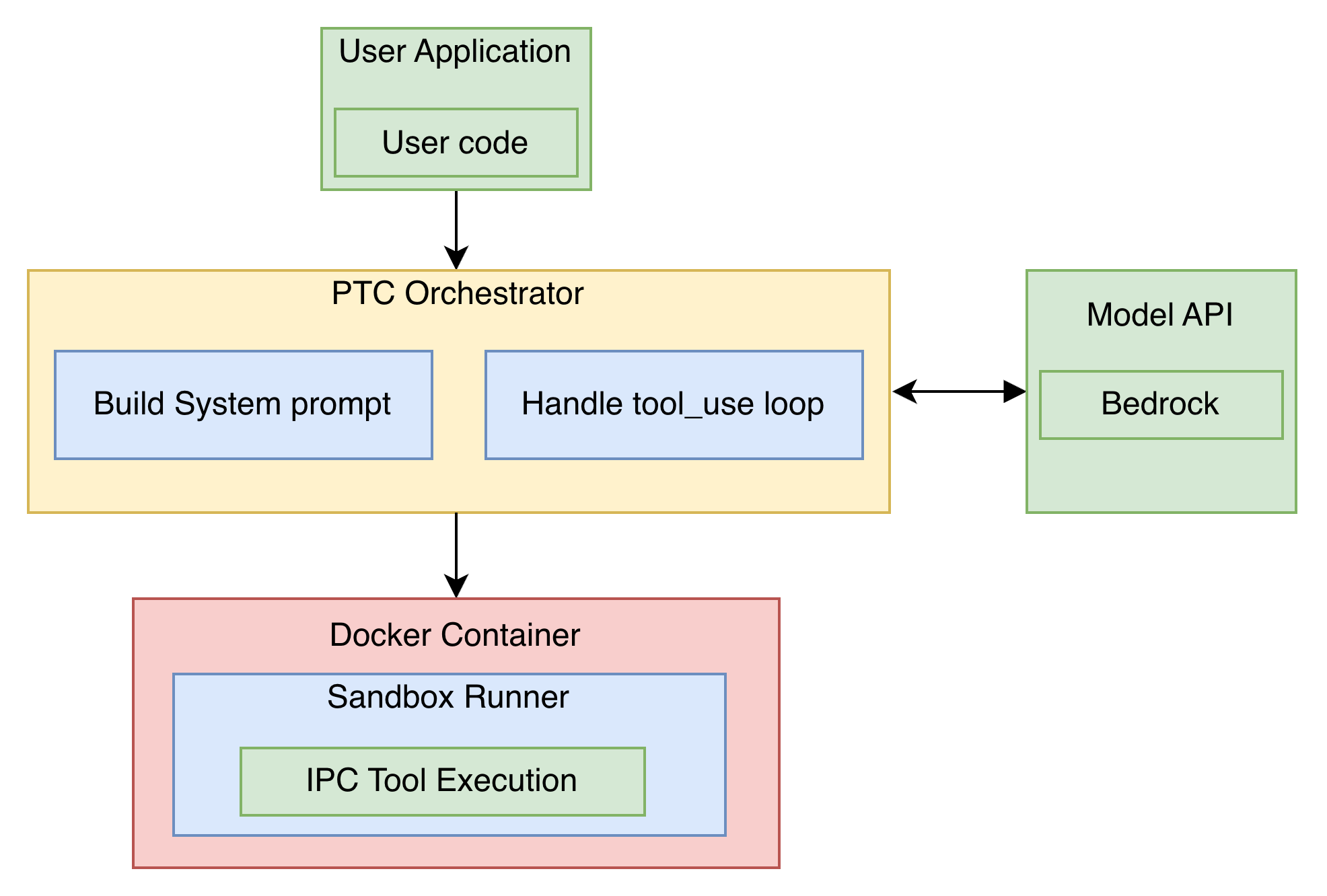 image
image
同じ経費監査の例を用いて、PTC が有効化された場合にモデルが生成する内容を示します:
import asyncio
import json
# ステップ 1: チームメンバーを取得
team_json = await get_team_members(department="engineering")
team = json.loads(team_json)
# ステップ 2: すべての経費レコードを並列に取得
expense_tasks = [
get_expenses(employee_id=m["id"], quarter="Q3")
for m in team
]
expenses_results = await asyncio.gather(*expense_tasks)*# ステップ 3: バジェットをフィルタリングして確認する*
exceeded = []
for member, exp_json in zip(team, expenses_results):
expenses = json.loads(exp_json)
total_travel = sum(
e["amount"] for e in expenses
if e["category"] == "travel" and e["status"] == "approved"
)
if total_travel > 5000:
budget_json = await get_custom_budget(user_id=member["id"])
budget = json.loads(budget_json)
limit = budget["budget_limit"]
if total_travel > limit:
exceeded.append({
"name": member["name"],
"spent": total_travel,
"limit": limit,
"exceeded_by": total_travel - limit
})
*# ステップ 4: サマリーのみがモデルのコンテキストに入る*
print(f"{len(exceeded)} members exceeded budget:")
print(json.dumps(exceeded, indent=2))
ここで注意すべき点は二つあります。第一に、asyncio.gather() は 20 件の経費照会を順次ではなく並列で発行するため、ツール呼び出しはほぼ同時に発生します。第二に、フィルタリング、集約、バジェット比較は自然言語ではなく Python で実行されます。最終的な print() の出力のみがモデルのコンテキストウィンドウに戻されます。2,000 件を超える生経費レコードは一切触れられません。モデルがサンプリングされるのはたった二回だけです:コードを生成する際と、最終出力を解釈する際の二回です。その間のすべて(ツール呼び出し、データ処理、フィルタリング)は追加のモデル推論なしにコンテナ内で完結します。
パート 1: Amazon Bedrock と Amazon ECS を用いたセルフホスト PTC
なぜセルフホストなのか
マネージド型の PTC(Programmatic Tool Calling)実装は、プロバイダーが管理するサンドボックス環境に依存しています。しかし、セルフホストを行うには十分な理由があります:
- モデル非依存:Amazon Bedrock で利用可能なすべてのモデルをサポートします(Claude、Qwen、MiniMax、Llama、Nova など多数)。
- 完全な制御権:サンドボックス環境をカスタマイズし、ドメイン固有の Python パッケージをインストールし、セキュリティポリシーを要件に合わせて設定できます。
- プライベートデプロイメント:コードの実行と中間データを自社の AWS アカウント内に保持できます。
アーキテクチャ
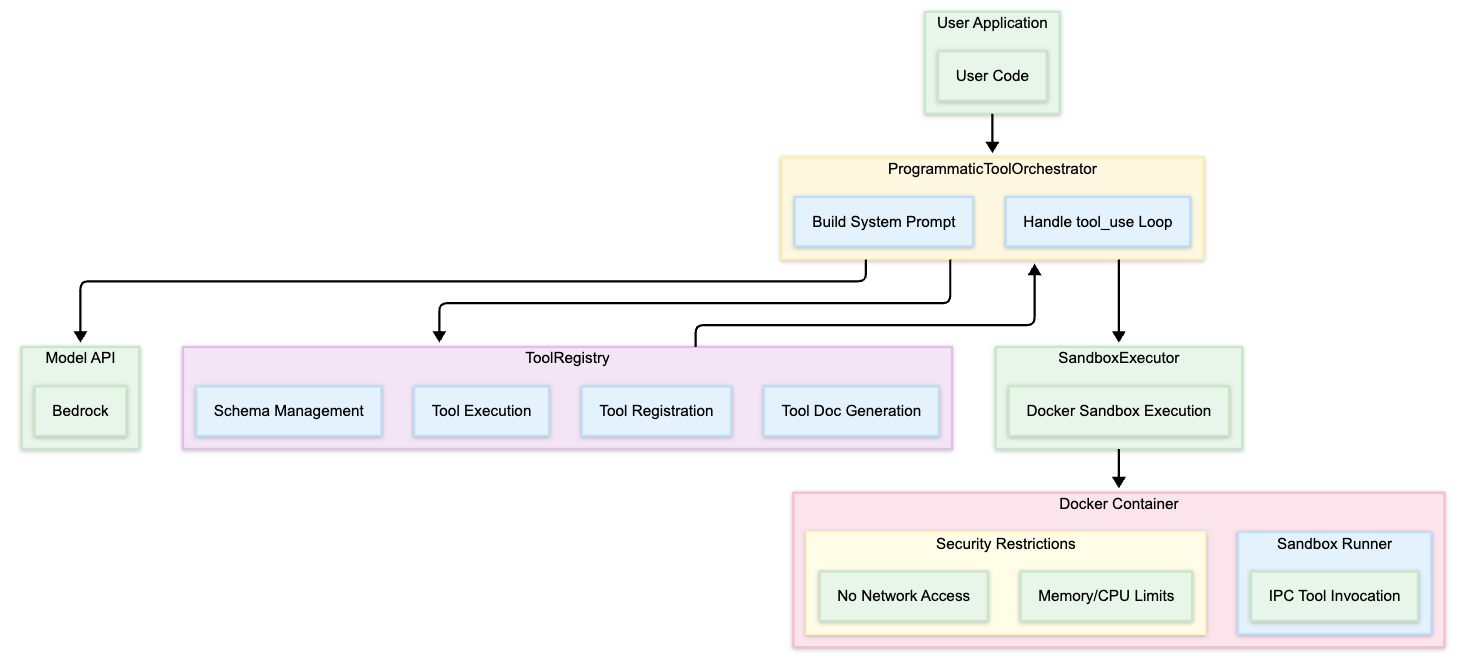
セルフホスト型ソリューションは 2 つのコンポーネントで構成されます:
- オーケストレーター:Boto3 を使用して InvokeModel API を呼び出し、Docker サンドボックスのライフサイクルを管理し、ツール呼び出しループを処理するアプリケーション(Amazon Elastic Container Service (Amazon ECS) タスク、AWS Lambda、またはその他の計算リソース)。
- Docker サンドボックス:モデル生成された Python コードを実行する隔離されたコンテナ。標準入力/標準エラーを介した IPC でオーケストレーターと通信します。
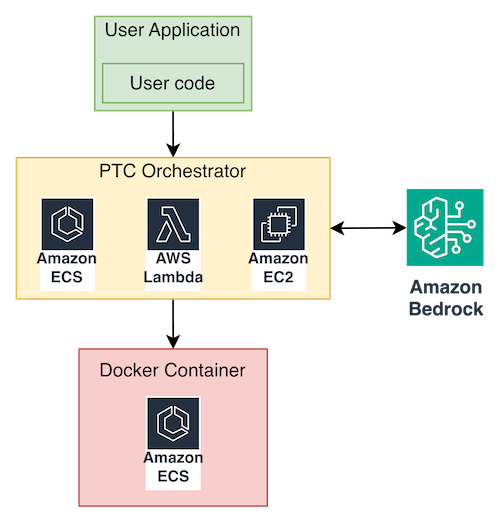
核となる考え方は単純です:通常は tool_config に含まれるツール定義を抽出し、代わりにシステムプロンプトに注入して、モデルに対してそれらのツールをオーケストレーションする Python コードの記述を指示します。生成されたコードは Docker サンドボックス内で実行されます。オーケストレーターは制御プレーンとして機能し、IPC を通じてツール呼び出しをインターセプトし、外部で実行した上で結果をサンドボックス内に再注入します。
システムプロンプト
システムプロンプトは、モデルが PTC(Programmatic Tool Calling)をネイティブにサポートしているかのように振る舞うようにする決定的な要素です。これは実行環境、利用可能なツール、およびコード生成のルールを記述したものです。簡略化されたバージョンを以下に示します:
*# コード実行環境の説明*
*## 中核機能*
execute_code ツールを使用して Python コードを実行できます。このコードは非同期ツール関数を呼び出すことができます。
{tools_doc}
*## 主要ルール*
*### 1. ステートレス環境*
- 各
execute_code呼び出しは新しい環境です。 - 変数は呼び出し間で保持されません。
- すべての操作は単一のコードブロック内で完了する必要があります。
*### 2. 基本構文*
- ツール呼び出しには
awaitを使用してください。 - 結果の出力には
print()を使用してください。 - データ処理、フィルタリング、集計は許可されています。
ベストプラクティス
正解:1 つのコードブロックで全タスクを完了する
import json
import asyncio
data = await get_orders(days=7)
orders = json.loads(data)
tasks = [get_detail(id=o['id']) for o in orders]
details = await asyncio.gather(*tasks)
for order, detail in zip(orders, details):
print(f"{order['name']}: {detail}")
不正:複数のコードブロック
*# 最初の実行*
data = await get_orders()
*# 2 回目の実行 - NameError: data が存在しない*
for item in data:
pass
このプロンプトは、モデルがネイティブな PTC(Programmatic Tool Calling)実装と同じパターンに従った、構造化された Python コードを生成するように導きます。具体的には、単一のコードブロック、非同期ツール呼び出し、および出力用の print() 関数です。
コアコンポーネント
SandboxExecutor – Docker サンドボックス実行環境
SandboxExecutor は中核コンポーネントです。隔離された Docker コンテナのライフサイクルを管理し、モデルが生成したコードを安全に実行し、ツール呼び出しのための IPC(Inter-Process Communication:プロセス間通信)プロトコルを処理します。
このシステムはデュアルプロセスアーキテクチャを採用しています。オーケストレーター(ECS タスク内で実行中)は、各コード実行リクエストに対して Docker コンテナを起動します。通信は標準入出力ストリームを通じて行われ、コンテナはツール呼び出しのリクエストを stderr に書き込み、オーケストレーターは stdin を通じてツールの結果を注入します。
ランナースクリプト
ランナースクリプトはオーケストレーターによって動的に生成され、起動時に各 Docker コンテナに注入されます。このスクリプトは以下の処理を担当します:
- コード実行 – モデル生成コードを非同期コンテキストにラップし、出力を取得して例外を処理する仕組み。
- IPC プロトコル – 構造化メッセージマーカー(例:__PTC_TOOL_CALL__, __PTC_END_CALL__, __PTC_OUTPUT__)を使用して、テキストストリーム内のツール呼び出し要求、結果、および最終出力を区別します。
- ツール関数生成 – 設定ファイルで定義された各ツールに対して動的に非同期 Python 関数を生成します。モデルのコードが await get_team_members(department="engineering") を呼び出すと、生成された関数が引数をシリアライズし、stderr にツール呼び出し要求を書き込みます。その後、オーケストレーターが stdin を介して結果を注入するまでブロックし、デシリアライズされた結果を返します。
ランナースクリプトは 2 つの実行モードをサポートしています:
- シングルモード – コードを一度だけ実行して終了します。ステートレスなワンショットタスクに適しています。
- ループモード – コンテナを実行状態に保ち、複数のコード実行を受け付けます。これにより、セッションの再利用や呼び出し間の状態保持が可能になります。
IPC プロトコル
テキストストリーム内で異なるメッセージタイプを確実に区別するために、システムは境界マーカーを定義しています:
- __PTC_TOOL_CALL__ / __PTC_END_CALL__ – ツール呼び出しリクエスト(ツール名と引数を JSON 形式)を囲むマーク。
- __PTC_OUTPUT__ – コード実行の最終出力を示すマーク。
ランナースクリプトが実行中のコード内でツール呼び出しを検出すると、その呼び出しを JSON としてシリアライズし、マーク間の標準エラー出力(stderr)に書き込み、結果を待つために標準入力(stdin)でブロックします。オーケストレーターは stderr を読み取り、ツール呼び出しを解析して実行し、その結果を再び stdin に書き戻します。ランナースクリプトはブロック解除され、実行を続行します。
オーケストレーターのループ
Amazon Bedrock で PTC(Programmatic Tool Calling)を有効化するには、以下の 3 つの要素が必要です:
- モデルに対してツールオーケストレーション用の Python コードを記述するよう指示するシステムプロンプト。
- モデルがサンドボックスへコードを送信するために使用する execute_code ツールの定義。
- システムプロンプトに埋め込まれたビジネスツールの説明(個別の Amazon Bedrock ツールとしてではなく)。
オーケストレーターは、Amazon Bedrock と Docker サンドボックスを結びつけます。以下がその中核となるループです:
import boto3
import json
import subprocess
import tempfile
import os
*# ── 設定 ──*
MODEL_ID = "us.anthropic.claude-sonnet-4-5-20250929-v1:0"
REGION = "us-west-2"
SANDBOX_IMAGE = "ptc-sandbox"
SYSTEM_PROMPT = "..." *# 上記に示した完全なシステムプロンプト*
翻訳全文
*# ステップ 1: ユーザークエリの送信 — モデルが Python コードを生成*\nmessages = [{"role": "user", "content": query}]\nresponse = call_bedrock(client, messages)\n\n*# ステップ 2: tool_use ブロックからコードを抽出*\nfor block in response["content"]:\nif block["type"] == "tool_use":\ncode = block["input"]["code"]\ntool_id = block["id"]\n\n*# ステップ 3: Docker サンドボックス内で実行*\noutput = execute_in_sandbox(code)\n\n*# ステップ 4: サンドボックスの出力を tool_result として送信*\nmessages.append({"role": "assistant", "content": response["content"]})\nmessages.append({\n"role": "user",\n"content": [{"type": "tool_result", "tool_use_id": tool_id, "content": output}]\n})\n\n*# ステップ 5: モデルが結果を解釈し、最終回答を生成*\nfinal = call_bedrock(client, messages)\nfor block in final["content"]:\nif block["type"] == "text":\nprint(block["text"]) \n
The orchestrator はユーザークエリを Amazon Bedrock に送信し、tool_use 応答からモデル生成コードを抽出して Docker サンドボックスで実行し、その出力を tool_result としてフィードバックします。その後、モデルは最終的な人間が読みやすい回答を生成し、サンプリングは合計 2 回のみ行われます。
Docker サンドボックスのセキュリティ
サンドボックスコンテナは厳格な隔離状態で実行されます。以下に、セキュリティ層を強化する docker run コマンドの例を示します:
docker run --rm \
--network none \
--read-only \
--tmpfs /tmp:size=64m \
--user sandbox \
--cap-drop ALL \
--memory 256m \
--cpus 0.5 \
-v /path/to/code.py:/sandbox/user_code.py:ro \
ptc-sandbox
これにより、ネットワークアクセスの不要化、読み取り専用ファイルシステム(一時領域用として小さな tmpfs を含む)、非ルートユーザーの使用、Linux 機能の剥奪、および厳格なメモリ/CPU リミットの設定が可能になります。モデルが生成したコードはサンドボックスから脱出できず、データを永続化することも、過度なリソースを消費することもできません。
パート 2: Amazon Bedrock AgentCore を用いた管理型 PTC
Docker コンテナや ECS インフラストラクチャの管理をしたくないチームのために、Amazon Bedrock AgentCore は、同じ PTC パターンを実装する管理型の Code Interpreter(コードインタプリタ)を提供します。モデルがコードを記述し、管理されたサンドボックスで実行され、最終的な出力のみがモデルコンテキストに返されます。以下は、コード実行に AgentCore Code Interpreter を使用するように修正した同様のアーキテクチャです:
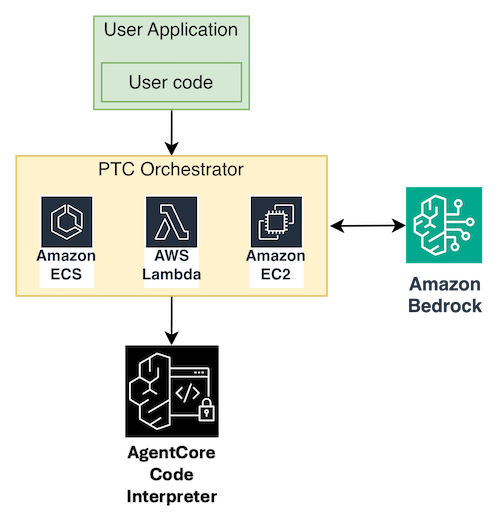
セルフホスト型アプローチとの決定的な違いは、ツールが IPC を介してクライアントにディスパッチされるのではなく、サンドボックスセッション内に事前にロードされる点です。Code Interpreter セッションを開始し、Python コードとしてツールの関数定義を注入した後、モデルに対してこれらの事前ロードされた関数を直接呼び出すコードを生成させます。
AgentCore では bedrock-agentcore boto3 クライアントを使用します:
import boto3
import json
bedrock = boto3.client("bedrock-runtime", region_name="us-west-2")
agentcore = boto3.client("bedrock-agentcore", region_name="us-west-2")*# コードインタプリタセッションを開始する*
session = agentcore.start_code_interpreter_session(
codeInterpreterIdentifier="aws.codeinterpreter.v1",
name="ptc-tools",
sessionTimeoutSeconds=900,
)
session_id = session["sessionId"]
*# サンドボックスにツール関数を事前読み込みする。*
*# この文字列は、実際のツール関数の定義に置き換えてください。*
tool_functions_code = """
def get_team_members(department):
ここに実装を入力 — JSON 文字列を返してください
pass
def get_expenses(employee_id, quarter="Q3"):
ここに実装を入力 — JSON 文字列を返してください
pass
def get_custom_budget(user_id):
ここに実装を入力 — JSON 文字列を返してください
pass
print("Tools loaded.")
"""
agentcore.invoke_code_interpreter(
codeInterpreterIdentifier="aws.codeinterpreter.v1",
sessionId=session_id,
name="executeCode",
arguments={"language": "python", "code": tool_functions_code}
)
セルフホスト型とマネージド型の比較
項目
セルフホスト型 (パート 1)
AgentCore (パート 2)
インフラストラクチャ
ECS + Docker を管理する必要がある
フルマネージド
原文を表示
Programmatic tool calling (PTC) is a paradigm shift in how large language models (LLMs) interact with external tools. In a traditional tool-calling workflow, each tool invocation requires a full round trip back to the model. The model calls a tool, receives the result, reasons about it, calls the next tool, and so on. For workflows that involve multiple tool calls, this creates compounding latency and token consumption because every intermediate result must pass through the model’s context window.
PTC takes a different approach. Instead of orchestrating tool calls one at a time, the model writes code, typically Python, that invokes multiple tools programmatically within a sandboxed execution environment. The code can include loops, conditionals, filtering, and aggregation logic. The model is only sampled once to produce the code. The execution environment then handles tool invocations, and only the final processed result is returned to the model’s context. This dramatically reduces both latency and token usage for multi-tool workflows. PTC is particularly effective for large data processing, precise numerical calculations, multi-step process orchestration, and privacy-sensitive scenarios where raw data shouldn’t enter the model’s context.
PTC originated as a provider-specific feature, but the underlying pattern—model generates code, sandbox executes it, only final output returns to context—is model-agnostic. In this post, we show three ways to implement PTC on Amazon Bedrock: a self-hosted Docker sandbox on ECS for maximum control, a managed solution using Amazon Bedrock AgentCore Code Interpreter, and an Anthropic SDK-compatible path through a proxy for teams that prefer that developer experience.
Bottlenecks in traditional tool calling
Consider this example: “Which engineering team members exceeded their Q3 travel budget?”With traditional tool calling (assuming no parallel function calling), the model must:
- Call a tool to get the team member list – 20 people.
- Call a tool to get expense records for each person – 20 separate tool calls, each returning 50–100 line items.
- Call additional tools to retrieve budget thresholds.
- Receive over 2,000 expense records into its context window.
- Reason over the full dataset in natural language to filter, compare, and summarize.
Each of those tool calls requires a full round trip through the model. The model generates a tool call, pauses, receives the result, reasons about it, generates the next tool call, and so on. This creates three compounding problems:
- Token consumption: Every intermediate result, including thousands of expense line items the model will ultimately discard, passes through the context window.
- Latency: Each tool invocation requires a full model inference cycle. 20 sequential tool calls means 20 inference round trips.
- Accuracy: Asking a language model to filter, aggregate, and compare thousands of records in natural language is error-prone. These are operations that a few lines of Python would handle precisely.
How PTC solves this
PTC flips the pattern. The model writes a single Python code block that orchestrates the tool calls, processes the results, and returns only the final output.
Using the same expense audit example, here’s what the model generates when PTC is enabled:
import asyncio
import json
# Step 1: Get team members
team_json = await get_team_members(department="engineering")
team = json.loads(team_json)
# Step 2: Fetch all expense records in parallel
expense_tasks = [
get_expenses(employee_id=m["id"], quarter="Q3")
for m in team
]
expenses_results = await asyncio.gather(*expense_tasks)
# Step 3: Filter and check budgets
exceeded = []
for member, exp_json in zip(team, expenses_results):
expenses = json.loads(exp_json)
total_travel = sum(
e["amount"] for e in expenses
if e["category"] == "travel" and e["status"] == "approved"
)
if total_travel > 5000:
budget_json = await get_custom_budget(user_id=member["id"])
budget = json.loads(budget_json)
limit = budget["budget_limit"]
if total_travel > limit:
exceeded.append({
"name": member["name"],
"spent": total_travel,
"limit": limit,
"exceeded_by": total_travel - limit
})
# Step 4: Only the summary enters the model's context
print(f"{len(exceeded)} members exceeded budget:")
print(json.dumps(exceeded, indent=2))There are two things to notice here. First, asyncio.gather() issues all 20 expense lookups in parallel rather than sequentially, the tool calls happen almost simultaneously. Second, the filtering, aggregation, and budget comparison happens in Python, not in natural language. Only the final print() output is returned to the model’s context window. The over 2,000 raw expense records don’t touch it.The model is sampled only twice: once to generate the code, and once to interpret the final output. Everything in between (the tool calls, the data processing, the filtering) happens inside the container without additional model inference.
Part 1: Self-hosted PTC with Amazon Bedrock and Amazon ECS
Why self-host
The managed PTC implementations rely on a provider-managed sandbox environment. But there are good reasons to self-host:
- Model-agnostic: Supports models available on Amazon Bedrock (for example, Claude, Qwen, MiniMax, Llama, Nova, and more.).
- Full control: Customize the sandbox environment, install domain-specific Python packages, and configure security policies to match your requirements.
- Private deployment: Keep code execution and intermediate data within your own AWS account.
Architecture
The self-hosted solution has two components:
- Orchestrator – Your application (Amazon Elastic Container Service (Amazon ECS) task, AWS Lambda, or a compute) that calls the InvokeModel API using Boto3, manages the Docker sandbox lifecycle, and handles the tool call loop.
- Docker sandbox – An isolated container that executes model-generated Python code. Communicates with the orchestrator through IPC over stdin/stderr.
The core idea is straightforward: take the tool definitions that normally go in tool_config, inject them into the system prompt instead, and instruct the model to write Python code that orchestrates those tools. The generated code runs in the Docker sandbox. The orchestrator acts as a control plane, intercepting tool calls through IPC, executing them externally, and injecting results back into the sandbox.
The system prompt
The system prompt is the critical piece that makes a model behave like it supports PTC natively. It describes the execution environment, the available tools, and the rules for generating code.A streamlined version is provided:
# Code Execution Environment Description
## Core Function
You can use the `execute_code` tool to run Python code. The code can call
asynchronous tool functions.
{tools_doc}
## Key Rules
### 1. Stateless Environment
- Each `execute_code` call is a fresh environment.
- Variables are not retained between calls.
- All operations must be completed in a single code block.
### 2. Basic Syntax
- Tool calls must use `await`.
- Use `print()` to output results.
- Data processing, filtering, and aggregation are allowed.
## Best Practices
### Correct: One code block completes all tasks
import json
import asyncio
data = await get_orders(days=7)
orders = json.loads(data)
tasks = [get_detail(id=o['id']) for o in orders]
details = await asyncio.gather(*tasks)
for order, detail in zip(orders, details):
print(f"{order['name']}: {detail}")
### Incorrect: Multiple code blocks
# First execution
data = await get_orders()
# Second execution - NameError: data does not exist
for item in data:
passThis prompt guides the model to produce well-structured Python code that follows the same patterns as the native PTC implementation, single code blocks, async tool calls, and print() for output.
Core components
SandboxExecutor – the Docker sandbox executor
SandboxExecutor is the central component. It manages the lifecycle of isolated Docker containers, executes model-generated code safely, and handles the IPC protocol for tool calls.The system uses a dual-process architecture. The orchestrator (running in your ECS task) launches a Docker container for each code execution request. Communication happens through standard I/O streams, the container writes tool call requests to stderr, and the orchestrator injects tool results through stdin.
The runner script
The runner script is dynamically generated by the orchestrator and injected into each Docker container at startup. It handles:
- Code execution – Wrapping the model-generated code in an async context, capturing output, and handling exceptions.
- IPC protocol – Using structured message markers (for example, __PTC_TOOL_CALL__, __PTC_END_CALL__, __PTC_OUTPUT__) to separate tool call requests, results, and final output in the text stream.
- Tool function generation – Dynamically creating async Python functions for each tool defined in the configuration. When the model’s code calls await get_team_members(department=”engineering”), the generated function serializes the arguments, writes a tool call request to stderr, blocks until the orchestrator injects the result using stdin, and returns the deserialized result.
The runner script supports two execution modes:
- Single mode – Executes the code once and exits. Suitable for stateless, one-shot tasks.
- Loop mode – Keeps the container running to accept multiple code executions, supporting session reuse and state retention between calls.
IPC protocol
To reliably separate different message types in a text stream, the system defines boundary markers:
- __PTC_TOOL_CALL__ / __PTC_END_CALL__ – Wraps a tool call request (tool name + arguments as JSON).
- __PTC_OUTPUT__ – Marks the final output of the code execution.
When the runner script encounters a tool call in the executing code, it serializes the call as JSON, writes it to stderr between the marker boundaries, and blocks on stdin waiting for the result. The orchestrator reads stderr, parses the tool call, executes the tool, and writes the result back to stdin. The runner script unblocks and continues execution.
The orchestrator loop
Enabling PTC on Amazon Bedrock requires three elements:
- A system prompt that instructs the model to write Python code for tool orchestration.
- An execute_code tool definition that the model uses to submit code to the sandbox.
- Business tool descriptions embedded in the system prompt (not as separate Amazon Bedrock tools).
The orchestrator ties together Amazon Bedrock and the Docker sandbox. Here is the core loop:import boto3import json
import subprocess
import tempfile
import os
# ── Configuration ──
MODEL_ID = "us.anthropic.claude-sonnet-4-5-20250929-v1:0"
REGION = "us-west-2"
SANDBOX_IMAGE = "ptc-sandbox"
SYSTEM_PROMPT = "..." # Full system prompt as shown above
TOOLS = [
{
"name": "execute_code",
"description": "Execute Python code in a sandboxed environment.",
"input_schema": {
"type": "object",
"properties": {
"code": {"type": "string", "description": "Python code to execute."}
},
"required": ["code"]
}
}
]
# ── Bedrock call ──
def call_bedrock(client, messages):
body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 4096,
"system": [{"type": "text", "text": SYSTEM_PROMPT}],
"tools": TOOLS,
"messages": messages,
})
response = client.invoke_model(
modelId=MODEL_ID,
contentType="application/json",
accept="application/json",
body=body,
)
return json.loads(response["body"].read())
# ── Sandbox execution ──
def execute_in_sandbox(code):
"""Run code in a hardened Docker container. Returns stdout."""
with tempfile.NamedTemporaryFile(mode="w", suffix=".py", delete=False) as f:
f.write("import json\n" + code)
tmp_path = f.name
try:
result = subprocess.run(
["docker", "run", "--rm",
"--network", "none", "--read-only",
"--tmpfs", "/tmp:size=64m",
"--user", "sandbox", "--cap-drop", "ALL",
"--memory", "256m", "--cpus", "0.5",
"-v", f"{tmp_path}:/sandbox/user_code.py:ro",
SANDBOX_IMAGE],
capture_output=True, text=True, timeout=30,
)
return result.stdout.strip() if result.returncode == 0 else result.stderr.strip()
finally:
os.unlink(tmp_path)
# ── PTC orchestration loop ──
client = boto3.client("bedrock-runtime", region_name=REGION)
query = "Which engineering team members exceeded their Q3 travel budget?"
# Step 1: Send user query — model generates Python code
messages = [{"role": "user", "content": query}]
response = call_bedrock(client, messages)
# Step 2: Extract code from tool_use block
for block in response["content"]:
if block["type"] == "tool_use":
code = block["input"]["code"]
tool_id = block["id"]
# Step 3: Execute in Docker sandbox
output = execute_in_sandbox(code)
# Step 4: Send sandbox output back as tool_result
messages.append({"role": "assistant", "content": response["content"]})
messages.append({
"role": "user",
"content": [{"type": "tool_result", "tool_use_id": tool_id, "content": output}]
})
# Step 5: Model interprets the result and produces final answer
final = call_bedrock(client, messages)
for block in final["content"]:
if block["type"] == "text":
print(block["text"])The orchestrator sends the user query to Amazon Bedrock, extracts the model-generated code from the tool_use response, runs it in the Docker sandbox, and feeds the output back as a tool_result. The model then produces its final human-readable answer, sampled only twice total.
Docker sandbox security
The sandbox container runs with strict isolation. Here is an example docker run command that enforces the security layers:
docker run --rm \
--network none \
--read-only \
--tmpfs /tmp:size=64m \
--user sandbox \
--cap-drop ALL \
--memory 256m \
--cpus 0.5 \
-v /path/to/code.py:/sandbox/user_code.py:ro \
ptc-sandboxThis facilitates: no network access, a read-only filesystem (with a small tmpfs for scratch space), a non-root user, Linux capabilities dropped, and hard memory/CPU limits. Model-generated code can’t escape the sandbox, persist data, or consume excessive resources.
Part 2: Managed PTC with Amazon Bedrock AgentCore Code Interpreter
For teams that don’t want to manage Docker containers and ECS infrastructure, Amazon Bedrock AgentCore provides a managed Code Interpreter that implements the same PTC pattern. The model writes code, a managed sandbox executes it, and only the final output returns to the model context. Here is the same architecture modified with the use of AgentCore Code Interpreter for code execution:
The key difference from the self-hosted approach is that tools are pre-loaded *into* the sandbox session rather than dispatched back to the client through IPC. You start a Code Interpreter session, inject your tool function definitions as Python code, and then let the model generate code that calls those pre-loaded functions directly.
AgentCore uses the bedrock-agentcore boto3 client:
import boto3
import json
bedrock = boto3.client("bedrock-runtime", region_name="us-west-2")
agentcore = boto3.client("bedrock-agentcore", region_name="us-west-2")
# Start a Code Interpreter session
session = agentcore.start_code_interpreter_session(
codeInterpreterIdentifier="aws.codeinterpreter.v1",
name="ptc-tools",
sessionTimeoutSeconds=900,
)
session_id = session["sessionId"]
# Pre-load tool functions into the sandbox.
# Replace this string with your actual tool function definitions.
tool_functions_code = """
def get_team_members(department):
# Your implementation here — return JSON string
pass
def get_expenses(employee_id, quarter="Q3"):
# Your implementation here — return JSON string
pass
def get_custom_budget(user_id):
# Your implementation here — return JSON string
pass
print("Tools loaded.")
"""
agentcore.invoke_code_interpreter(
codeInterpreterIdentifier="aws.codeinterpreter.v1",
sessionId=session_id,
name="executeCode",
arguments={"language": "python", "code": tool_functions_code}
)Self-hosted vs. managed comparison
Aspect
Self-hosted (Part 1)
AgentCore (Part 2)
Infrastructure
You manage ECS + Docker
Fully managed
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み