Google AI、自動音声認識およびテキスト読み上げモデルの学習用マルチリンガルアフリカ語音声データセット「WAXAL」を公開
Google AIと共同研究者は、24のアフリカ言語をカバーする多言語音声データセット「WAXAL」を公開し、自動音声認識とテキスト読み上げモデルの学習におけるデータ分布問題の解消を目指している。
キーポイント
多言語アフリカ音声データセット「WAXAL」の公開
Google AIと共同研究者が、24のアフリカ言語をカバーするオープンな多言語音声データセット「WAXAL」を公開した。
ASRとTTSの異なる要件に対応した二重構造
WAXALは、多様な話者と自然環境での自発的音声からなるASRコンポーネントと、制御された環境での単一話者高品質音声からなるTTSコンポーネントに分かれて設計されている。
画像プロンプトによる自然なASRデータ収集手法
ASRデータは、話者に画像を見せて母語で説明させる「画像プロンプト音声」方式で収集され、より自然な語彙・構文のバリエーションを捉えている。
現実世界の多様性を内包した実用的データセット
WAXALは完全にクリーンなベンチマークデータセットではなく、話者、ドメイン、音響条件にわたる実際の変動性を含む、現場収集型の多言語ASRデータに近い。
影響分析・編集コメントを表示
影響分析
このリリースは、音声技術におけるデータ分布問題に直接取り組む重要な進展であり、特にアフリカ言語のような低リソース言語の音声技術開発を加速させる可能性がある。ASRとTTSの異なる要件を考慮したデータ設計は、実用的な音声モデル開発のベストプラクティスを示しており、業界全体のデータ収集方法に影響を与える可能性がある。
編集コメント
音声AIの民主化に向けた実践的な一歩。特に、ASRとTTSで異なるデータ要件を明確に区別した設計は、今後の音声データセット構築の参考になる。
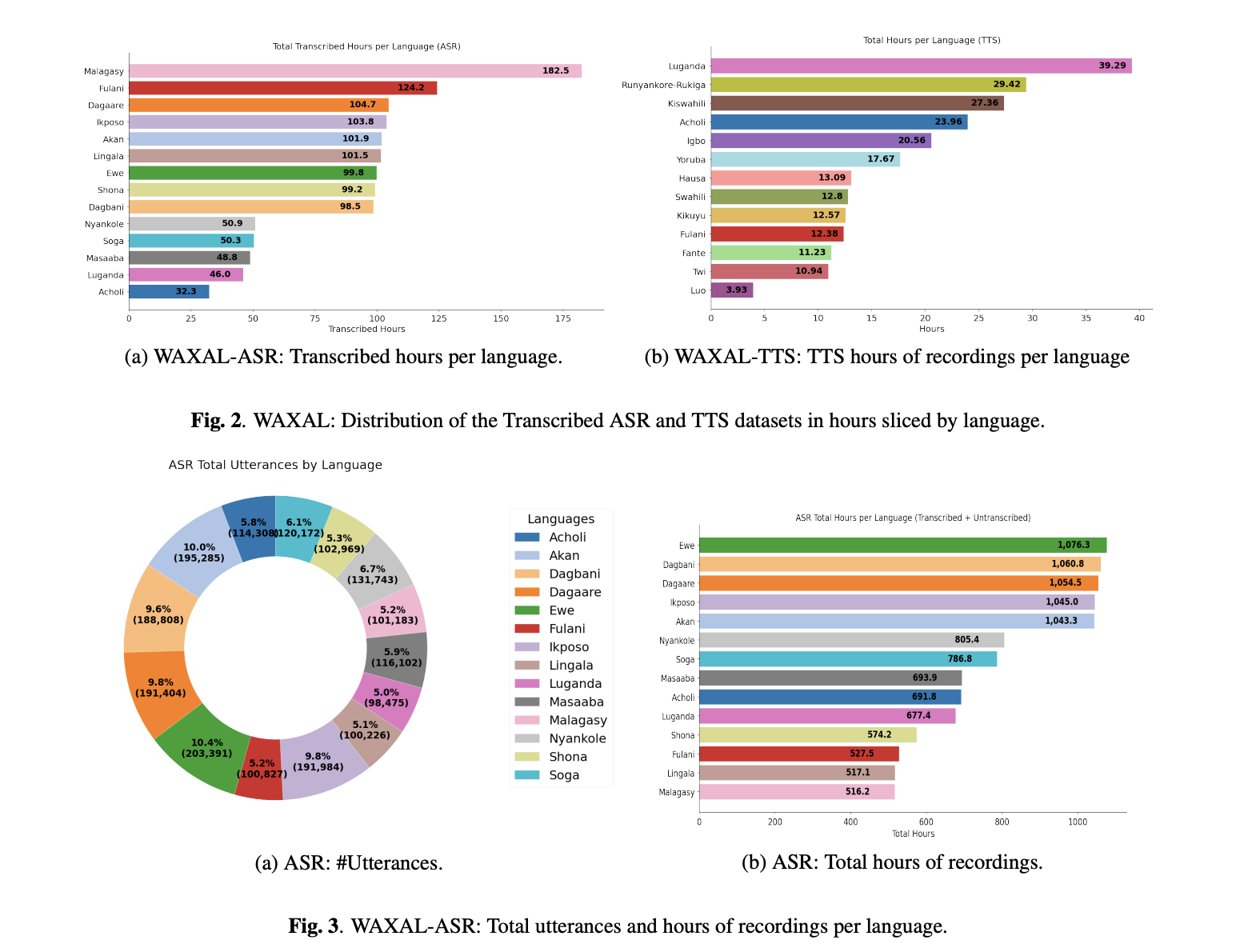
音声技術には依然としてデータ分布の問題があります。自動音声認識(ASR)およびテキスト読み上げ(TTS)システムはリソース豊富な言語において急速に改善しましたが、多くのアフリカ諸言語はオープンなコーパスにおいて依然として不十分な表現しかされていません。Google の研究者チームと他の協力者らは、24 言語をカバーするアフリカ諸言語向けのオープン多言語音声データセット「WAXAL」を発表しました。このデータセットには、転記された自然な音声から構築された ASR コンポーネントと、スタジオ品質の単一話者録音から構築された TTS コンポーネントが含まれています。
ASR と TTS は異なるデータ要件を持つため、WAXAL は 2 つのリソースとして構造化されています。ASR サイドは、多様な話者、自然な環境、そして自発的な言語生成を中心に設計されています。一方、TTS サイドは、制御された録音条件、音韻的にバランスの取れたスクリプト、および合成に適したクリーンな単一話者の音声を中心に設計されています。この分離は技術的に重要です:ノイズの多い現実世界の環境における堅牢な認識に有用なデータセットは、通常、強力な単一話者 TTS モデルを生成するデータセットとは同一ではありません。
 imagehttps://arxiv.org/pdf/2602.02734
imagehttps://arxiv.org/pdf/2602.02734
ASR データの収集方法
WAXAL の ASR(自動音声認識)部分は、画像プロンプトを用いた音声収集によって行われました。話者には画像が提示され、母国語で見たものを記述するよう求められました。これは単純な台本読みよりも自然な設定です。録音は各話者の自然環境で行われ、最小持続時間は 15 秒とされました。収集プロセスでは、話者の年齢、性別、言語、録音環境などのメタデータも追跡されました。収集された全音声のうち一部のみが転写されました。研究チームによると、現在の ASR リリースには、記録された全音声の約 10% に相当する転写が含まれています。これらの転写は、利用可能な場合は現地の文字を使用し、そうでない場合は英語アルファベットによる転写を用いて、有償の現地言語専門家によって作成されました。
これは多言語 ASR システムを構築するすべての人にとって重要です。画像プロンプトによる音声は、厳密に台本化された読みよりも、より自然な語彙および構文の変異を捉える傾向がありますが、その反面、転写が困難になり、話者間やドメイン間、音響条件間のばらつきが増大します。WAXAL はこのトレードオフを回避するのではなく、むしろこれに踏み込んでいます。その結果得られるのは完璧にクリーンなベンチマークデータセットではなく、現実の変動性が組み込まれたフィールド収集型多言語 ASR データに近いものです。
TTS(テキスト読み上げ)データの収集方法
WAXAL の TTS(テキスト読み上げ)側は、非常に異なるアプローチで構築されました。TTS データセットは、高品質な単一話者合成音声のために設計されています。各対象言語に対して、研究チームは約 108,500 語の音韻的にバランスの取れたスクリプトを作成しました。72 名のコミュニティ参加者を契約し、男女の声優を均等に割り当てて、背景ノイズを低減し音声の忠実度を維持するために、プロフェッショナルなスタジオのような環境で録音を行いました。各声優あたり約 16 時間のクリーンで編集済みのオーディオが目標とされました。
これは合成にとって適切な設計選択です。TTS モデルは、ASR(自動音声認識)システムに比べて、発音の一貫性、録音条件、マイク品質、話者アイデンティティの均質性をはるかに重視します。したがって WAXAL は、「音声データ」を単一のカテゴリとして扱うという一般的な過ちを避け、実際には ASR と TTS のパイプラインが非常に異なる教師信号を必要とする点を考慮しています。
キーポイント
WAXAL は、リソース不足のアフリカ言語向け ASR および TTS(テキスト読み上げ)のために構築されたオープンな多言語音声コーパスです。
ASR データは、実世界の環境で収集された画像プロンプト付きの自然音声を使用しています。
TTS データは、音韻的にバランスの取れたスクリプトによるスタジオ品質の単一話者録音を使用しています。
論文とデータセットはこちらでご覧ください。また、Twitter でフォローすることもできますし、12 万人以上の ML サブレッドに参加したり、ニュースレターを購読したりするのもご自由にどうぞ。待ってください!Telegram をご利用ですか?今なら Telegram でも私たちに参加できます。
Google AI が WAXAL を公開:自動音声認識およびテキスト読み上げモデルの学習のための多言語アフリカ語音声データセット(続き 4/4)
この投稿は、MarkTechPost で最初に発表された「Google AI が WAXAL を公開:自動音声認識およびテキスト読み上げモデルの学習のための多言語アフリカ語音声データセット」の記事です。
原文を表示
Speech technology still has a data distribution problem. Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) systems have improved rapidly for high-resource languages, but many African languages remain poorly represented in open corpora. A team of researchers from Google and other collaborators introduce WAXAL, an open multilingual speech dataset for African languages covering 24 languages, with an ASR component built from transcribed natural speech and a TTS component built from studio-quality single-speaker recordings.
WAXAL is structured as two separate resources because ASR and TTS have different data requirements. The ASR side is designed around diverse speakers, natural environments, and spontaneous language production. The TTS side is designed around controlled recording conditions, phonetically balanced scripts, and cleaner single-speaker audio suited for synthesis. That separation is technically important: a dataset that is useful for robust recognition in noisy real-world settings is usually not the same dataset that produces strong single-speaker TTS models.
imagehttps://arxiv.org/pdf/2602.02734
How the ASR data was collected
The ASR portion of WAXAL was collected using image-prompted speech. Speakers were shown images and asked to describe what they saw in their native language, which is a more natural setup than simple prompted reading. Recordings were captured in speakers’ natural environments, each with a minimum duration of 15 seconds. The collection process also tracked metadata such as speaker age, gender, language, and recording environment. Only a subset of the full collected audio was transcribed: the research team states that the current ASR release includes transcriptions for about 10% of the total recorded audio. Those transcriptions were produced by paid local linguistic experts, using local scripts where available and English-alphabet transliteration otherwise.
This is important for anyone building multilingual ASR systems. Image-prompted speech tends to capture more natural lexical and syntactic variation than tightly scripted reading, but it also makes transcription harder and increases variation across speakers, domains, and acoustic conditions. WAXAL leans into that tradeoff rather than avoiding it. The result is not a perfectly clean benchmark dataset; it is closer to a field-collected multilingual ASR data with real variability baked in.
How the TTS data was collected
The TTS side of WAXAL was built very differently. The TTS dataset was designed for high-quality, single-speaker synthetic voices. For each target language, the research team created a phonetically balanced script of approximately 108,500 words. They contracted 72 community participants, evenly split between male and female voice actors, and recorded them in professional studio-like environments to reduce background noise and preserve audio fidelity. The target was approximately 16 hours of clean edited audio per voice actor.
This is the right design choice for synthesis. TTS models care much more about consistency in pronunciation, recording conditions, microphone quality, and speaker identity than ASR systems do. WAXAL therefore avoids the common mistake of treating ‘speech data’ as a single category, when in practice ASR and TTS pipelines want very different supervision signals.
Key Takeaways
WAXAL is an open multilingual speech corpus built for low-resource African language ASR and TTS.
The ASR data uses image-prompted, natural speech collected in real-world environments.
The TTS data uses studio-quality, single-speaker recordings with phonetically balanced scripts.
Check out Paper and Dataset here. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
The post Google AI Releases WAXAL: A Multilingual African Speech Dataset for Training Automatic Speech Recognition and Text-to-Speech Models appeared first on MarkTechPost.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み