AutoGluonアシスタント:マルチエージェント協調によるコード不要のAutoML
Amazon Scienceが発表したAutoGluon Assistantは、マルチエージェントアーキテクチャと大規模言語モデルを活用し、コード不要で自然言語記述から機械学習モデルを構築するAutoMLフレームワークであり、Kaggle AutoML Grand Prixで10位を獲得した。
キーポイント
コード不要のAutoML実現
AutoGluon Assistantは、モデル選択やハイパーパラメータチューニングだけでなく、コーディング自体を不要にすることで、プログラミング知識のないドメイン専門家でも機械学習を利用可能にする。
マルチエージェントアーキテクチャ
MLZeroと呼ばれるマルチエージェントシステムを基盤とし、データ知覚、ツール知識、実行履歴、コード生成を分離した専門コンポーネントが協調して、現実世界の複雑な入力を処理する。
実証された性能
Kaggle AutoML Grand Prixで10位を獲得し、自動化エージェントとして唯一ポイントを獲得。Multimodal AutoML Agent Benchmarkで92%、外部ベンチマークMLE-bench Liteで86%の成功率を達成。
多様なデータ形式対応
表形式、画像、テキスト、時系列データなど、多様なデータ形式に対して自然言語記述から機械学習モデルを構築できる。
四つのコアモジュールによる自動化
AutoGluon Assistantは、知覚、意味記憶、エピソード記憶、反復コーディングの四つのモジュールで構成され、データ理解からコード生成・デバッグまでを自動化する。
エピソード記憶によるデバッグ支援
エピソード記憶は実行履歴を記録し、エラー発生時に過去の試行と結果を参照してデバッグコンテキストを提供し、反復的な改善を可能にする。
ベンチマークでの優れた性能
AutoGluon AssistantはMLE-bench Liteで86%の成功率を達成し、21課題中18課題で有効なソリューションを提出した。また、より困難なMultimodal AutoML Agent Benchmarkでは92%の成功率を記録した。
影響分析・編集コメントを表示
影響分析
この技術は、機械学習の民主化をさらに進め、プログラミング知識のない専門家が直接MLを活用できる可能性を開く。Kaggleコンペティションでの実績は、自動化システムが人間の専門家と競えるレベルに達していることを示しており、AutoML分野の新たな基準を設定する可能性がある。
編集コメント
Kaggleでの実績が示すように、自動化システムが人間の専門家と競えるレベルに達している点が注目される。ただし、Amazon自社の発表であるため、独立した第三者評価も待たれる。
AutoGluon アシスタント:マルチエージェント協働によるゼロコード AutoML
マルチエージェントアーキテクチャは、データ知覚、ツール知識、実行履歴、およびコード生成を分離することで、 messy な現実世界の入力にも対応できる機械学習の自動化を実現します。
機械学習
Haoyang Fang, Boran Han, Yuyang (Bernie) Wang
12 月 05 日 午前 10:24
2024 年の Kaggle AutoML グランプリ(数百チームが参加し、トップの AutoML プラクティショナーや Kaggle グランドマスターも含まれる、賞金総額 75,000 ドルの競技)において、当社の完全自動化されたフレームワークは 10 位を獲得しました。これは、同競技で得点を獲得した唯一の自動エージェントです。この成果は、私たちが追求してきた問いに対する回答を検証するものとなりました。すなわち、AutoML に通常付随するモデル選択やハイパーパラメータチューニングだけでなく、コーディングそのものを排除することは可能なのか?
自動化された機械学習の約束は、常に民主化にありました。しかし、ほとんどの AutoML ツールでは依然として、ユーザーがコードを書き、データ構造を準備し、機械学習のワークフローを理解する必要があります。プログラミングの背景を持たないドメインエキスパート、実験データを分析する科学者、予測モデルを構築するアナリスト、画像コレクションを取り扱う研究者にとって、このコーディング要件は不要な障壁となっています。
私たちはこの障壁を取り除くために AutoGluon Assistant を設計しました。大規模言語モデルによって駆動される革新的なマルチエージェントシステムである MLZero を基盤に、AutoGluon Assistant は自然言語による記述を、表形式データ、画像データ、テキストデータ、時系列データにわたって訓練された機械学習モデルへと変換します。本システムは、当社の多モーダル AutoML エージェントベンチマークで 92% の成功率を達成し、外部の MLE-bench Lite では 86% を記録しました。両方の評価において、成功率とソリューションの品質の面でトップクラスの性能を示しています。
真の自動化のためのマルチエージェントアーキテクチャ
従来の AutoML ツールは、クリーンで構造化された入力と、正しく API を呼び出す能力を持つユーザーを前提としています。現実世界の機械学習の問題は、より複雑な現実から始まります:曖昧なデータファイル、不明確なタスク定義、分類が必要なのか回帰が必要なのかもわからないユーザーです。MLZero は、Amazon Bedrock からの大規模言語モデルによって駆動される専門コンポーネントが協力して生データを動作するソリューションへと変換するというマルチエージェントアーキテクチャを通じて、この課題に対処します。
例えば、胸部 X 線画像とセグメンテーションマスクをアップロードし、「X 線内の疾患領域を検出する」ことを目標とする医療研究者を想定してください。知覚モジュールはピクセルレベルのセグメンテーションがタスクであると特定し、意味記憶(semantic memory)は意味論的セグメンテーションのために AutoGluon の MultiModalPredictor を選択し、反復コーディングモジュールがコードの生成と改良を行います。初期試行でマスク形式の不整合に遭遇した場合、エピソード記憶(episodic memory)がデバッグコンテキストを提供して前処理と後処理を調整し、研究者がコードを一切記述することなくセグメンテーションモデルのトレーニングを成功させます。
このシステムは4つの主要モジュールから構成されています:知覚モジュール、意味記憶、エピソード記憶、および反復コーディングです。知覚モジュールは任意のデータ入力を解釈し、ファイル構造と内容を解析して、形式の不整合や曖昧な命名に関わらず構造的な理解を構築します。ユーザーがターゲット変数の明確な表示がない CSV ファイルを提供する場合でも、知覚モジュールはカラムの分布と意味論を分析してタスク構造を推測します。
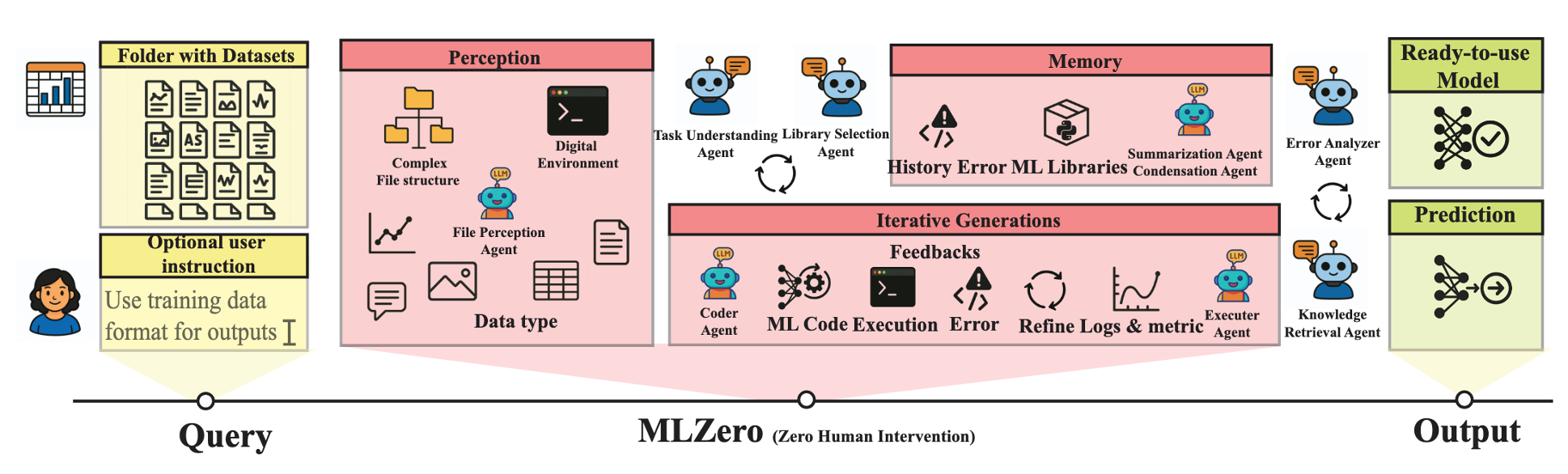 image AutoGluon Assistant の 4 つのコアモジュール(知覚、意味記憶、エピソード記憶、反復コーディング)の概要。意味記憶モジュールは、ML ライブラリに関する知識をシステムに付与し、AutoGluon の機能、API パターン、ベストプラクティスについて構造化された情報を維持します。ユーザーが AutoGluon Multimodal においてセマンティック・セグメンテーションタスクには SAM モデルが必要であることを事前に知る必要はなく、意味記憶によりシステムはタスクの特性に基づいて適切なツールを自動選択できます。
image AutoGluon Assistant の 4 つのコアモジュール(知覚、意味記憶、エピソード記憶、反復コーディング)の概要。意味記憶モジュールは、ML ライブラリに関する知識をシステムに付与し、AutoGluon の機能、API パターン、ベストプラクティスについて構造化された情報を維持します。ユーザーが AutoGluon Multimodal においてセマンティック・セグメンテーションタスクには SAM モデルが必要であることを事前に知る必要はなく、意味記憶によりシステムはタスクの特性に基づいて適切なツールを自動選択できます。
エピソード記憶は、実行履歴を時系列で維持し、システムが何を試したか、何が成功し、何が失敗したかを追跡します。コード実行時にエラーが発生した場合、このモジュールは関連する過去の試行とその結果を提示することで、デバッグの文脈を提供します。これは、完全な形での解決策が即座に現れるのではなく、改良を通じて解決策が生まれていく ML 開発の反復的な性質に対応したものです。
反復コーディングモジュールは、フィードバックループと拡張された記憶を備えた改善プロセスを実装しています。生成されたコードは実行され、結果またはエラーを出力し、次の試行に反映されます。これは、成功するまで、または最大反復回数に達するまで継続します。必要に応じて、各反復ごとにユーザーからの入力をオプションで受け付けることで、ガイダンスを提供できます。このアーキテクチャは高い自動化を維持しつつ、人間の監督のための柔軟性も確保しています。
この包括的なシステムを通じて、MLZero はノイズの多い生データと洗練された機械学習ソリューションとの間のギャップを埋めます。マルチエージェント協調パターンは、アーキテクチャが従来の単一エージェントシステムで相互に絡み合っている「データの理解」「機能の把握」「履歴の追跡」「コード生成」という各関心を分離しているため、あらゆるモダリティにおいて効果的であることが証明されています。
結果の分析
当社のシステムを確立された外部基準に対して検証するため、まず MLE-bench Lite 上で評価を行いました。このベンチマークは過去の Kaggle コンペティションから選ばれた 21 の多様な課題で構成されており、当社のモデルのパフォーマンスを他の主要な自動化システムのものと直接比較することが可能になります。当社のモデルは最高成功率である 86% を達成し、21 の課題のうち 18 で有効なソリューションの完成と提出に成功しました。全体としてのソリューション品質においては首位を獲得し、平均順位は 1.43 でした(次点のエージェントは 2.36)。当社のエージェントは金メダルを 6 つ獲得し、ベンチマーク内の全課題における総メダル数でもすべての競合他社を上回りました。
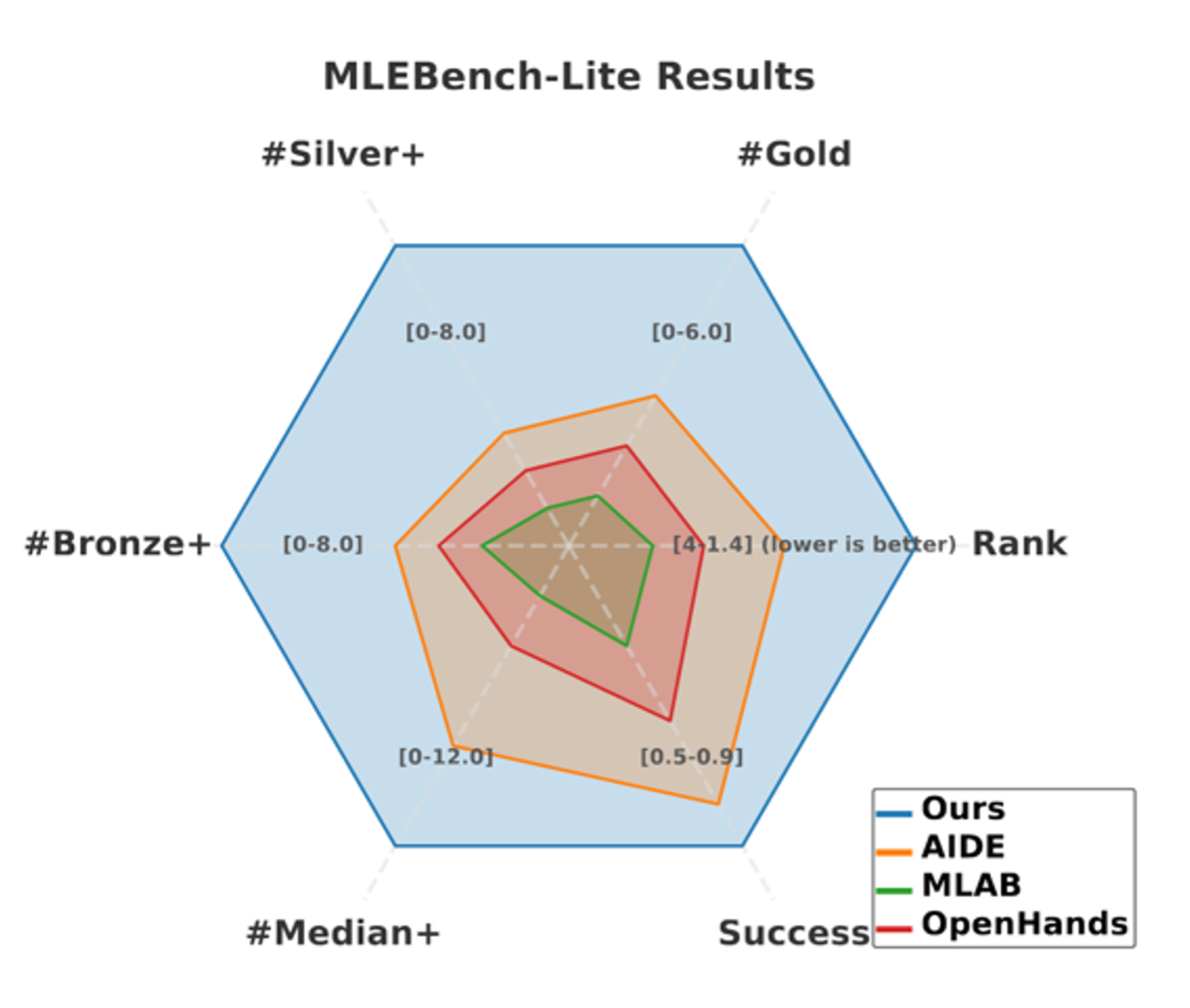 image AutoGluon Assistant は、ノイズを含む生データやフォーマットの不一致、複数のモダリティを特徴とする Multimodal AutoML Agent Benchmark の 25 タスクにおいて 92% の成功率を達成しました。コンパクトな 8B パラメータの LLM(大規模言語モデル)を使用した場合でも、45.3% の成功率を記録しています。既存のベンチマークでモデルの能力を実証した後、さらに独自の Multimodal AutoML Agent Benchmark でテストを行いました。これはより過酷なスイートであり、25 の多様なタスクから構成され、データはより生に近い形で、ノイズが多く、フォーマットの不一致や曖昧さが目立つデータセットを使用しています。このベンチマークでは、複数のデータモダリティ(表形式、画像、テキスト、ドキュメント)と問題タイプ(分類、回帰、検索、意味的セグメンテーション)、そして多言語・複数テーブル・大規模データセットといった困難なデータ構造が特徴です。AutoGluon Assistant(MLZero として実装)は全タスクで 92% の成功率を達成しました。コンパクトな 80 億パラメータの LLM で実装した場合でも、システムは依然として 45.3% の成功率を記録し、より大規模でリソース集約型の多くのエージェントよりも効果的であることを証明しました。
image AutoGluon Assistant は、ノイズを含む生データやフォーマットの不一致、複数のモダリティを特徴とする Multimodal AutoML Agent Benchmark の 25 タスクにおいて 92% の成功率を達成しました。コンパクトな 8B パラメータの LLM(大規模言語モデル)を使用した場合でも、45.3% の成功率を記録しています。既存のベンチマークでモデルの能力を実証した後、さらに独自の Multimodal AutoML Agent Benchmark でテストを行いました。これはより過酷なスイートであり、25 の多様なタスクから構成され、データはより生に近い形で、ノイズが多く、フォーマットの不一致や曖昧さが目立つデータセットを使用しています。このベンチマークでは、複数のデータモダリティ(表形式、画像、テキスト、ドキュメント)と問題タイプ(分類、回帰、検索、意味的セグメンテーション)、そして多言語・複数テーブル・大規模データセットといった困難なデータ構造が特徴です。AutoGluon Assistant(MLZero として実装)は全タスクで 92% の成功率を達成しました。コンパクトな 80 億パラメータの LLM で実装した場合でも、システムは依然として 45.3% の成功率を記録し、より大規模でリソース集約型の多くのエージェントよりも効果的であることを証明しました。
多様なワークフローのためのアクセス可能なインターフェース
AutoGluon Assistant は、異なるユーザーの好みやワークフローに適応させるために複数の対話モードをサポートしています。ユーザーは、迅速な自動化タスクのためにコマンドラインインターフェース(CLI)を介してシステムを呼び出すことも、既存のデータパイプラインへの統合のために Python API を使用することも、視覚的な対話と監視のために Web UI を利用することもできます。あるいは、他のエージェントツールとの統合には Model Context Protocol (MCP) を使用することも可能です。この柔軟性により、ユーザーがスクリプト、グラフィカルインターフェース、またはプログラムによる制御を好むかにかかわらず、同じ基盤となる自動化機能にアクセスすることができます。
AutoGluon Assistant の例として、システムはオプションの反復ごとのユーザー入力もサポートしており、ドメインエキスパートが反復的な改良中に専門知識を注入しながら、日常的な使用においては自動化を維持できるようにしています。例えば、医療画像データを扱う場合、エキスパートはスキャンプロトコルに固有のカスタム正規化に向けてシステムを誘導することがあります。エピソードメモリは、これらの介入とシステムによって生成された試行の両方を追跡し、自動化が機械的な複雑性を処理する一方で、ユーザーが関連する洞察を持っている場合に戦略的な方向性を提供する協力的なダイナミクスを生み出します。
本システムはオープンソースであり、Github で利用可能です。技術詳細については、NeurIPS 2025 の論文で公開されています。
研究分野:機械学習
タグ:AutoGluon, Agentic AI
原文を表示
AutoGluon assistant: Zero-code AutoML through multiagent collaboration
A multiagent architecture separates data perception, tool knowledge, execution history, and code generation, enabling ML automation that works with messy, real-world inputs.
Machine learning
Haoyang Fang Boran Han Yuyang (Bernie) Wang December 05, 10:24 AM December 05, 10:24 AM At the 2024 Kaggle AutoML Grand Prix a $75,000 competition featuring hundreds of teams including top AutoML practitioners and Kaggle grandmasters our fully automated framework placed 10th, making it the only automated agent to score points in the competition. This achievement validated our answer to a question we'd been pursuing: could we eliminate not just the model selection and hyperparameter tuning typically associated with AutoML, but the coding itself?
The promise of automated machine learning has always been democratization. Yet most AutoML tools still require users to write code, prepare data structures, and understand ML workflows. For domain experts without programming backgrounds scientists analyzing experimental data, analysts building forecasting models, or researchers working with image collections this coding requirement creates an unnecessary barrier.
We designed AutoGluon Assistant to remove this barrier. Built on MLZero, a novel multiagent system powered by large language models, AutoGluon Assistant transforms natural-language descriptions into trained machine learning models across tabular, image, text, and time series data. The system achieved a 92% success rate on our Multimodal AutoML Agent Benchmark and 86% on the external MLE-bench Lite, with leading performance in both success rate and solution quality.
A multiagent architecture for true automation
Traditional AutoML tools assume clean, structured inputs and users capable of invoking APIs correctly. Real-world ML problems begin with messier realities: ambiguous data files, unclear task definitions, and users who may not know whether they need classification or regression. MLZero addresses this through a multiagent architecture where specialized components powered by large language models from Amazon Bedrock collaborate to transform raw inputs into working solutions.
For example, consider a medical researcher who uploads chest x-ray images with segmentation masks, describing the goal as "locate disease regions in x-rays." The perception module identifies pixel-level segmentation as the task, semantic memory selects AutoGluon's MultiModalPredictor for semantic segmentation, and the iterative coding module generates and refines code. When the initial attempt encounters mask format incompatibilities, episodic memory provides debugging context to adjust preprocessing and postprocessing, successfully training a segmentation model all without the researcher writing any code.
The system comprises four core modules: perception, semantic memory, episodic memory, and iterative coding. The perception module interprets arbitrary data inputs, parsing file structures and content to build structured understanding regardless of format inconsistencies or ambiguous naming. Where users might provide CSV files without clear indication of target variables, perception analyzes column distributions and semantics to infer task structure.
image Overview of AutoGluon Assistant's four core modules: perception, semantic memory, episodic memory, and iterative coding. The semantic-memory module enriches the system with knowledge of ML libraries, maintaining structured information about AutoGluon's capabilities, API patterns, and best practices. Rather than requiring users to know that semantic-segmentation tasks require the SAM model in AutoGluon Multimodal, semantic memory enables the system to select appropriate tools based on task characteristics.
Episodic memory maintains chronological execution records, tracking what the system has attempted, what succeeded, and what failed. When code execution produces errors, this module provides debugging context by surfacing relevant previous attempts and their outcomes. This addresses the iterative nature of ML development, where solutions emerge through refinement rather than appearing fully formed.
The iterative-coding module implements a refinement process with feedback loops and augmented memory. Generated code executes, produces results or errors, and informs subsequent attempts. This continues until either successful execution or a maximum iteration limit, with optional per-iteration user input for guidance when needed. The architecture maintains high automation while preserving flexibility for human oversight.
Through this comprehensive system, MLZero bridges the gap between noisy raw data and sophisticated ML solutions. The multiagent collaboration pattern proves effective across modalities because the architecture separates concerns understanding data, knowing capabilities, tracking history, and generating code that traditionally intertwine in single-agent systems.
Breaking down results
To validate our system against an established, external standard, we first evaluated it on MLE-bench Lite. This benchmark consists of 21 diverse challenges from previous Kaggle competitions, allowing us to directly compare our model's performance to those of other leading automated systems. Our model achieved the highest success rate, 86%, meaning it successfully completed and submitted valid solutions for 18 of the 21 challenges. It secured the top position in overall solution quality, with an average rank of 1.43 in the standings, compared to the next-best agent's 2.36. Our agent won six gold medals and outperformed all competitors in total medal counts across the benchmark's challenges.
image AutoGluon Assistant achieved 92% success on the Multimodal AutoML Agent Benchmark's 25 tasks, featuring raw data with noise, format inconsistencies, and multiple modalities. Even with a compact 8B-parameter LLM, it achieved 45.3% success. After proving our model's capabilities on an existing benchmark, we further tested it on our own Multimodal AutoML Agent Benchmark, a more challenging suite comprising 25 diverse tasks with less-processed datasets, where data is closer to its raw form with more noise, format inconsistencies, and ambiguities. This benchmark features multiple data modalities (tabular, image, text, document) and problem types (classification, regression, retrieval, semantic segmentation) and challenging data structures (multilingual, multitable, and large-scale datasets). AutoGluon Assistant (as MLZero) achieved a 92% success rate across all tasks. When implemented with a compact, eight-billion-parameter LLM, the system still achieved a 45.3% success rate, proving more effective than many larger, more resource-intensive agents.
Accessible interfaces for diverse workflows
AutoGluon Assistant supports multiple interaction modes to fit different user preferences and workflows. Users can invoke the system through a command-line interface for quick automation tasks, a Python API for integration into existing data pipelines, or a Web UI for visual interaction and monitoring, or they can use the Model Context Protocol (MCP) to integrate it with other agentic tools. This flexibility ensures that whether users prefer scripting, graphical interfaces, or programmatic control, they can access the same underlying automation capabilities.
Example of the AutoGluon AssistantThe system also supports optional per-iteration user input, allowing domain experts to inject specialized knowledge during iterative refinement while maintaining automation for routine use. When working with medical imaging data, for instance, experts might guide the system toward custom normalizations specific to their scanning protocols. Episodic memory tracks these interventions alongside system-generated attempts, creating a collaborative dynamic where automation handles mechanical complexity while users contribute strategic direction when they possess relevant insights.
The system is open source and available on Github, with technical details published in our NeurIPS 2025 paper.
Research areas: Machine learning
Tags: AutoGluon, Agentic AI
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み