LLM推論モデル推論の現状
Sebastian Raschkaは、2025年のLLM推論能力向上の主要トピックとして、特に推論時計算リソース拡大(推論時スケーリング)に焦点を当てた最新の研究動向を分析し、複数の実装戦略を解説している。
キーポイント
LLM推論モデルの定義と重要性
推論モデルは、中間ステップや思考プロセスを生成することで多段階問題を解決するように設計されたLLMであり、複雑な課題における性能向上に寄与する。
推論能力向上の二大戦略
推論能力を高める主な方法は、(1)学習時の計算リソース増加、または(2)推論時の計算リソース増加(推論時スケーリング)の二つに大別される。
推論時スケーリングへの焦点
本記事は、特に推論時計算の拡大(推論時スケーリング)という手法に着目し、DeepSeek R1以降の研究動向を中心に解説している。
多様な改善手法の組み合わせ
研究者らは、推論時計算拡大、強化学習、教師ありファインチューニング、蒸留など、複数の手法を組み合わせることで、より大きな効果を追求している。
推論時の計算スケーリングの重要性
LLMの推論能力向上には、訓練時の計算(大規模な訓練やファインチューニング)と推論時の計算(より長く「考える」ことや追加の計算)の両方を組み合わせることが重要である。
推論コストと応答長の関係
中間ステップや説明を含む長い応答を生成する手法では、応答長が推論コストに直結するため、訓練アプローチと推論スケーリングは本質的に結びついている。
記事の焦点
本記事では、DeepSeek R1リリース後に注目された、生成トークン数を明示的に制御する推論時の計算スケーリング手法に焦点を当てている。
影響分析・編集コメントを表示
影響分析
この記事は、LLMの実用性能を左右する核心的な能力である「推論」の最新研究動向、特に計算リソース配分の戦略に焦点を当てており、AI開発者や研究者が今後の技術開発の方向性を考える上で重要な示唆を提供している。推論時スケーリングへの注目は、モデル訓練後の運用段階での性能最適化という実用的な観点から、業界の関心を集める可能性が高い。
編集コメント
LLMの「推論」という基礎能力の向上手法を、特に実運用時のリソース配分という観点から整理した良質な解説記事。技術トレンドの核心を捉えており、開発現場の意思決定にも役立つ内容。
大規模言語モデル(LLM)の推論能力の向上は、2025年における最も注目を集めるトピックの一つとなっており、それには十分な理由があります。より強力な推論スキルを備えることで、LLMはより複雑な問題に取り組むことが可能になり、ユーザーが関心を持つ幅広いタスクにおいて、より有能なモデルとなるためです。
ここ数週間で、研究者たちは推論を改善するための多数の新戦略を共有しました。これには、推論時の計算リソース拡大(推論時スケーリング)、強化学習、教師ありファインチューニング、蒸留などが含まれます。そして多くのアプローチは、より大きな効果を得るためにこれらの技術を組み合わせています。
本記事では、推論に最適化されたLLMに関する最近の研究進歩を探求します。特に、DeepSeek R1のリリース以降に登場した、推論時の計算リソース拡大(推論時スケーリング)に焦点を当てます。

私が『Understanding Reasoning LLMs』で説明した、推論モデルを実装する4つの主要カテゴリー。本記事は推論時スケーリング手法に焦点を当てます。
LLMにおける推論の実装と改善:4つの主要カテゴリー
ほとんどの読者はすでにLLM推論モデルに精通していると思われるため、定義は簡潔に述べます:LLMベースの推論モデルとは、中間ステップや構造化された「思考」プロセスを生成することで、多段階の問題を解決するように設計されたLLMのことです。単に最終的な答えを出力するだけの単純な質問応答LLMとは異なり、推論モデルは思考プロセスを明示的に表示するか、内部で処理します。これにより、パズル、コーディング課題、数学的問題などの複雑なタスクにおいて、より優れたパフォーマンスを発揮することが可能になります。

基本的なLLMの一行の回答と、推論LLMの説明を含む回答との比較。
一般的に、推論を改善するには主に2つの戦略があります:(1) 学習時の計算リソースを増やす、または (2) 推論時の計算リソースを増やす(推論時スケーリングまたはテスト時スケーリングとも呼ばれる)。(推論時の計算リソースとは、学習後にユーザーのクエリに応じてモデルの出力を生成するために必要な処理能力を指します。)
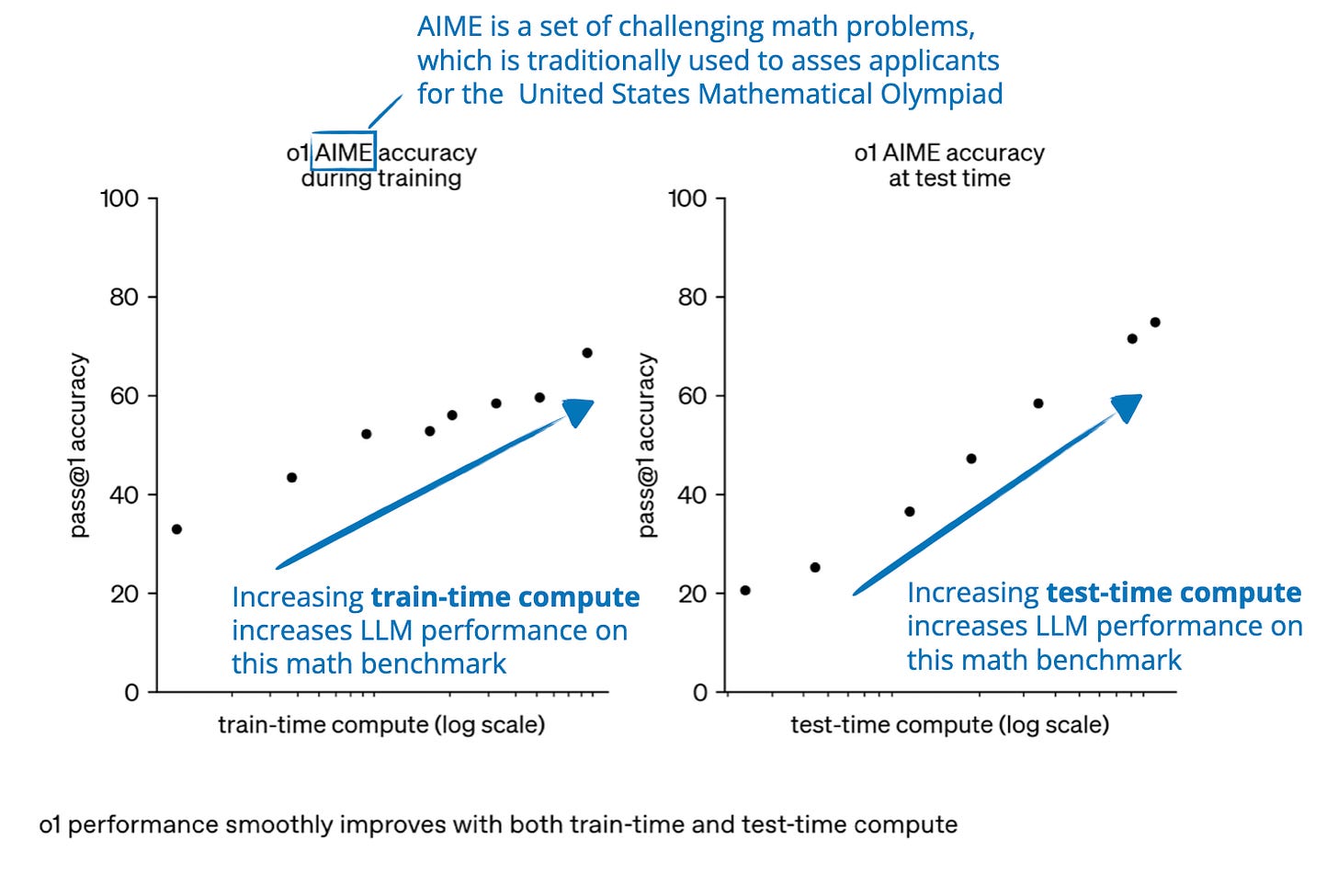
精度の向上は、学習時の計算リソースの増加、またはテスト時の計算リソースの増加によって達成可能。ここでテスト時の計算リソースは、推論時の計算リソースおよび推論時スケーリングと同義。出典: https://openai.com/index/learning-to-reason-with-llms/ の図を注釈付きで引用。
上記の図は、学習時「または」推論時の計算リソースによって推論が改善されるかのように見せています。しかし、LLMは通常、大規模な学習時の計算リソース(強化学習や特殊なデータを用いた大規模な学習やファインチューニング)と、増加した推論時の計算リソース(推論時にモデルが「より長く考える」ことや追加の計算を行うことを可能にする)を組み合わせることで、推論を改善するように設計されています。

推論時スケーリングと同義で使用される多くの用語。
推論モデルがどのように開発・改善されているかを理解するためには、異なる技術を個別に見ることが依然として有用であると考えます。私の前回の記事『Understanding Reasoning LLMs』では、以下の図にまとめられているように、4つのカテゴリーに細分化した分類について論じました。

上図の手法2〜4は、通常、出力に中間ステップや説明を含むため、より長い応答を生成するモデルを生み出します。推論コストは応答の長さに比例するため(例えば、応答が2倍の長さなら計算リソースも2倍必要)、これらの学習アプローチは本質的に推論スケーリングと関連しています。しかし、この推論時の計算リソース拡大に関するセクションでは、追加のサンプリング戦略、自己修正メカニズム、またはその他の方法を通じて、生成されるトークン数を明示的に調整する技術に特に焦点を当てます。
本記事では、2025年1月22日のDeepSeek R1リリース後に続いた、推論時の計算リソース拡大(推論時スケーリング)に焦点を当てた興味深い新しい研究論文とモデルリリースに焦点を当てます。(当初は本記事ですべてのカテゴリーの手法を網羅する予定でしたが、分量が過多となったため、学習時の計算リソース手法に焦点を当てた別記事を将来公開することを決定しました。)

私の前回の記事『Understanding Reasoning LLMs』(https://magazine.sebastianraschka.com/p/understanding-reasoning-llms)で論じた、DeepSeekの推論モデルの開発プロセス。
推論時の計算リソース拡大手法と、推論時スケーリングカテゴリーに焦点を当てた推論モデルの進歩のさまざまな領域について詳しく見る前に、少なくともすべての異なるカテゴリーの概要を簡単に説明させてください。
- 推論時の計算リソース拡大(推論時スケーリング)
このカテゴリーには、基礎となるモデルを学習させたり変更したりすることなく、推論時にモデルの推論能力を改善する手法が含まれます。
原文を表示
Improving the reasoning abilities of large language models (LLMs) has become one of the hottest topics in 2025, and for good reason. Stronger reasoning skills allow LLMs to tackle more complex problems, making them more capable across a wide range of tasks users care about.
In the last few weeks, researchers have shared a large number of new strategies to improve reasoning, including scaling inference-time compute, reinforcement learning, supervised fine-tuning, and distillation. And many approaches combine these techniques for greater effect.
This article explores recent research advancements in reasoning-optimized LLMs, with a particular focus on inference-time compute scaling that have emerged since the release of DeepSeek R1.
The four main categories of implementing reasoning models I explained in Understanding Reasoning LLMs. This article focuses on inference-time-scaling methods.
Implementing and improving reasoning in LLMs: The four main categories
Since most readers are likely already familiar with LLM reasoning models, I will keep the definition short: An LLM-based reasoning model is an LLM designed to solve multi-step problems by generating intermediate steps or structured "thought" processes. Unlike simple question-answering LLMs that just share the final answer, reasoning models either explicitly display their thought process or handle it internally, which helps them to perform better at complex tasks such as puzzles, coding challenges, and mathematical problems.
Side-by-side comparison of a basic LLM’s one-line answer and a reasoning LLM’s explanatory response.
In general, there are two main strategies to improve reasoning: (1) increasing training compute or (2) increasing inference compute, also known as inference-time scaling or test-time scaling. (Inference compute refers to the processing power required to generate model outputs in response to a user query after training.)
Accuracy improvements can be achieved through increased training or test-time compute, where test-time compute is synonymous with inference-time compute and inference-time scaling. Source: Annotated figure from https://openai.com/index/learning-to-reason-with-llms/
Note that the plots shown above make it look like we improve reasoning either via train-time compute OR test-time compute. However, LLMs are usually designed to improve reasoning by combining heavy train-time compute (extensive training or fine-tuning, often with reinforcement learning or specialized data) and increased test-time compute (allowing the model to "think longer" or perform extra computation during inference).
The many terms that are used synonymously with inference-time scaling.
To understand how reasoning models are being developed and improved, I think it remains useful to look at the different techniques separately. In my previous article, Understanding Reasoning LLMs, I discussed a finer categorization into four categories, as summarized in the figure below.
Methods 2-4 in the figure above typically produce models that generate longer responses because they include intermediate steps and explanations in their outputs. Since inference costs scale with response length (e.g., a response twice as long requires twice the compute), these training approaches are inherently linked to inference scaling. However, in this section on inference-time compute scaling, I focus specifically on techniques that explicitly regulate the number of generated tokens, whether through additional sampling strategies, self-correction mechanisms, or other methods.
In this article, I focus on the interesting new research papers and model releases focused on scaling inference-time compute scaling that followed after the DeepSeek R1 release on January 22nd, 2025. (Originally, I wanted to cover methods from all categories in this article, but due to the excessive length, I decided to release a separate article focused on train-time compute methods in the future.)
Development process of DeepSeek's reasoning models that I discussed in my previous article, Understanding Reasoning LLMs (https://magazine.sebastianraschka.com/p/understanding-reasoning-llms).
Before we look into Inference-time compute scaling methods and the different areas of progress on the reasoning model with a focus on the inference-time compute scaling category, let me at least provide a brief overview of all the different categories.
- Inference-time compute scaling
This category includes methods that improve model reasoning capabilities at inference time without training or modifying the underlying model weights. The core idea is to trade off increased computational resources for improved performance, which helps with making even fixed models more capable through techniques such as chain-of-thought reasoning, and various sampling procedures.
While I categorize inference-time compute scaling separately to focus on methods in this context, it is important to note that this technique can be applied to any LLM. For example, OpenAI developed its o1 model using reinforcement learning and then additionally leveraged inference-time compute scaling. Interestingly, as I discussed in my previous article on reasoning models (Understanding Reasoning LLMs), the DeepSeek R1 paper explicitly categorized common inference-time scaling methods (such as Process Reward Model-based and Monte Carlo Tree Search-based approaches) under "unsuccessful attempts." This suggests that DeepSeek did not explicitly use these techniques beyond the R1 model’s natural tendency to generate longer responses, which serves as an implicit form of inference-time scaling over the V3 base model. However, since explicit inference-time scaling is often implemented at the application layer rather than within the LLM itself, DeepSeek acknowledged that they could easily incorporate it into the R1 deployment or application.
- Pure reinforcement learning
This approach focuses solely on reinforcement learning (RL) to develop or improve reasoning capabilities. It typically involves training models with verifiable reward signals from math or coding domains. While RL allows models to develop more strategic thinking and self-improvement capabilities, it comes with challenges such as reward hacking, instability, and high computational costs.
- Reinforcement learning and supervised fine-tuning
This hybrid approach combines RL with supervised fine-tuning (SFT) to achieve more stable and generalizable improvements than pure RL. Typically, a model is first trained with SFT on high-quality instruction data and then further refined using RL to optimize specific behaviors.
- Supervised fine-tuning and model distillation
This method improves the reasoning capabilities of a model by instruction fine-tuning it on high-quality labeled datasets (SFT). If this high-quality dataset is generated by a larger LLM, then this methodology is also referred to as "knowledge distillation" or just "distillation" in LLM contexts. However, note that this differs slightly from traditional knowledge distillation in deep learning, which typically involves training a smaller model using not only the outputs (labels) but also the logits of a larger teacher model.
Ahead of AI is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
Inference-time compute scaling methods
The previous section already briefly summarized inference-time compute scaling. Before discussing the recent research in this category, let me describe the inference-time scaling in a bit more detail.
Inference-time scaling improves an LLM's reasoning by increasing computational resources ("compute") during inference. The idea why this can improve reasoning can be given with a simple analogy: humans give better responses when given more time to think, and similarly, LLMs can improve with techniques that encourage more "thought" during generation.
One approach here is prompt engineering, such as chain-of-thought (CoT) prompting, where phrases like "think step by step" guide the model to generate intermediate reasoning steps. This improves accuracy on complex problems but is unnecessary for simple factual queries. Since CoT prompts generate more tokens, they effectively make inference more expensive.

An example of classic CoT prompting from the 2022 Large Language Models are Zero-Shot Reasoners paper (https://arxiv.org/abs/2205.11916).
Another method involves voting and search strategies, such as majority voting or beam search, which refine responses by selecting the best output.
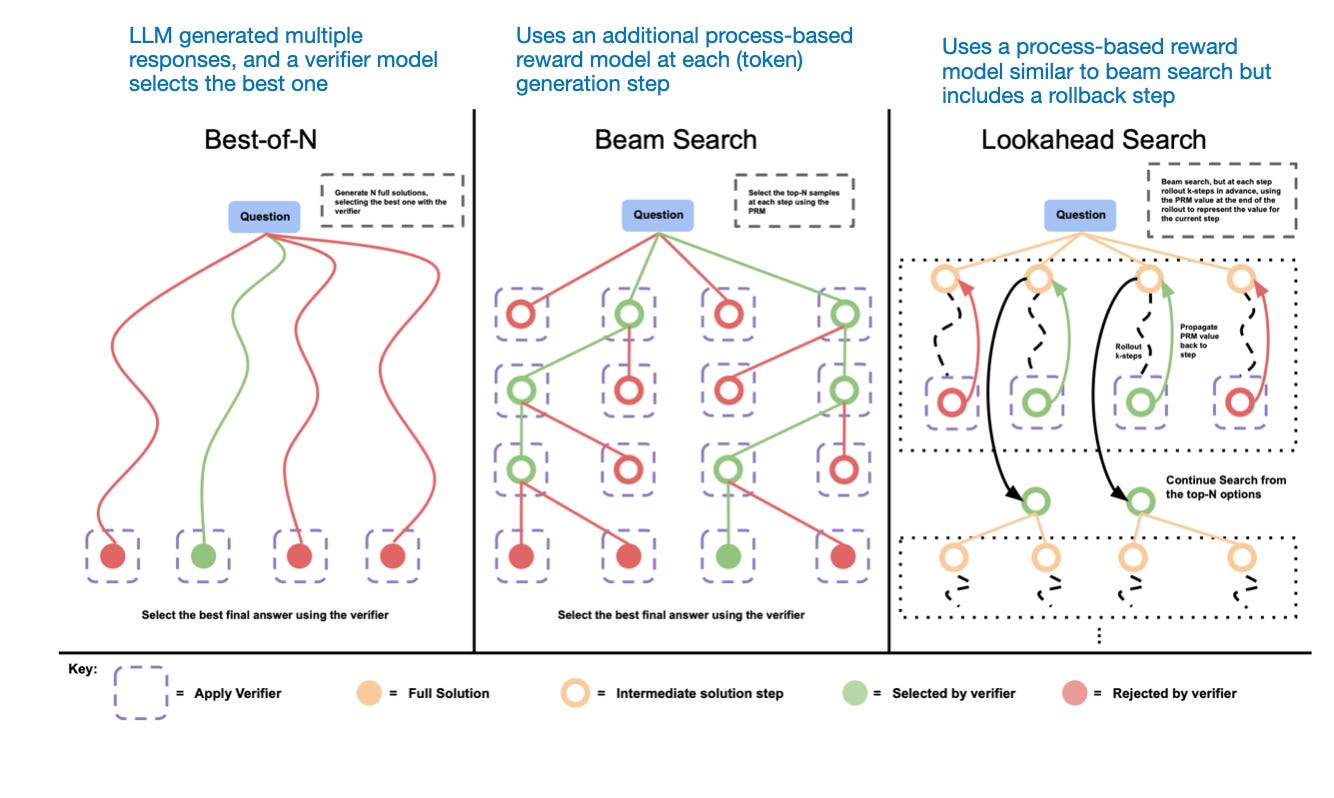
Different search-based methods rely on a process-reward-based model to select the best answer. Annotated figure from the LLM Test-Time Compute paper, https://arxiv.org/abs/2408.03314
- "s1: Simple test-time scaling"
The remainder of this article will be focused on the recent research advances in the inference-time scaling category for improving reasoning capabilities of LLMs. Let me start with a more detailed discussion of a paper that serves as an example of inference-time scaling.
So, one of the interesting recent research papers in this category is s1: Simple Test-Time Scaling (31 Jan, 2025), which introduces so-called "wait" tokens, which can be considered as a more modern version of the aforementioned "think step by step" prompt modification.
Note that this involves supervised finetuning (SFT) to generate the initial model, so it's not a pure inference-time scaling approach. However, the end goal is actively controlling the reasoning behavior through inference-time scaling; hence, I considered this paper for the "1. Inference-time compute scaling" category.
In short, their approach is twofold:
Create a curated SFT dataset with 1k training examples that include reasoning traces.
Control the length of responses by:
a) Appending "Wait" tokens to get the LLM to generate longer responses, self-verify, and correct itself, or
b) Stopping generation by adding an end-of-thinking token delimiter ("Final Answer:"). They call this length control "budget forcing."

Illustration of "wait" token insertion to control the length of the output. Annotated figure from https://arxiv.org/abs/2501.19393.
Budget forcing can be seen as a sequential inference scaling technique because it still generates one token at a time (but just more of it). In contrast, we have parallel techniques like majority voting, which aggregate multiple independent completions.
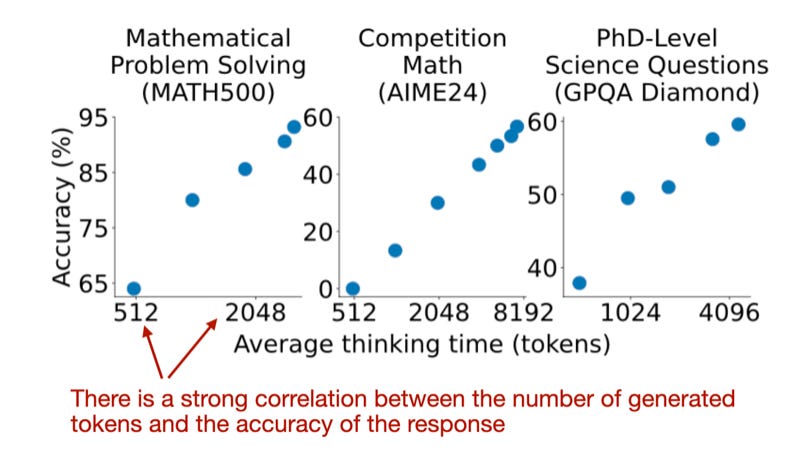
Correlation between response accuracy and length. Annotated figure from https://arxiv.org/abs/2501.19393.
They found their budget-forcing method more effective than other inference-scaling techniques I've discussed, like majority voting. If there's something to criticize or improve, I would've liked to see results for more sophisticated parallel inference-scaling methods, like beam search, lookahead search, or the best compute-optimal search described in Google's Scaling LLM Test-Time Compute Optimally Can Be More Effective Than Scaling Model Parameters paper last year. Or even a simple comparison with a classic sequential method like chain-of-thought prompting ("Think step by step").
Anyway, it's a really interesting paper and approach!
PS: Why "Wait" tokens? My guess is the researchers were inspired by the "Aha moment" figure in the DeepSeek-R1 paper, where researchers saw LLMs coming up with something like "Wait, wait. Wait. That's an aha moment I can flag here." which showed that pure reinforcement learning can induce reasoning behavior in LLMs.
Interestingly, they also tried other tokens like "Hmm" but found that "Wait" performed slightly better.

"Wait" vs "Hmm" tokens. Annotated figure from https://arxiv.org/abs/2501.19393.
Other noteworthy research papers on inference-time compute scaling
Since it's been a very active month on the reasoning model research front, I need to keep the summaries of other papers relatively brief to manage a reasonable length for this article. Hence, below are brief summaries of other interesting research articles related to inference-time compute scaling, sorted in ascending order by publication date.
As mentioned earlier, not all of these articles fall neatly into the inference-time compute scaling category, as some of them also involve specific training. However, these papers have in common that controlling inference-time compute is a specific mechanism of action. (Many distilled or SFT methods that I will cover in upcoming articles will lead to longer responses, which can be seen as a form of inference-time compute scaling. However, they do not actively control the length during inference, which makes these methods different from those covered here.)
- Test-Time Preference Optimization
22 Jan, Test-Time Preference Optimization: On-the-Fly Alignment via Iterative Textual Feedback, https://arxiv.org/abs/2501.12895
Test-time Preference Optimization (TPO) is an iterative process that aligns LLM outputs with human preferences during inference (this is without altering its underlying model weights). In each iteration, the model:
Generates multiple responses for a given prompt.
Score the responses with a reward model to select the highest- and lowest-scoring ones as "chosen" and "rejected" responses
Prompt the model to compare and critique the "chosen" and "rejected" responses
Refine the output by converting the critiques into textual suggestions to update the original model responses
By doing steps 1-4 iteratively, the model refines its original responses.
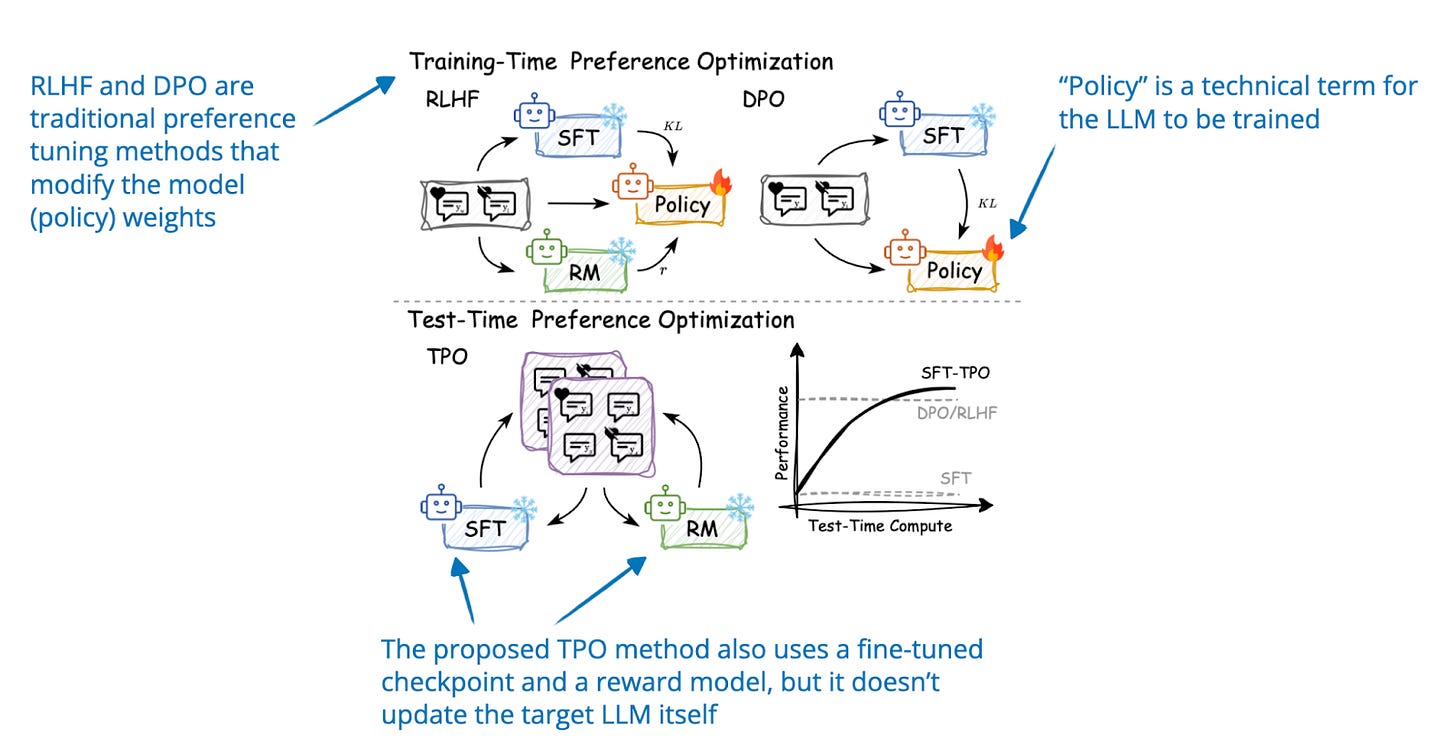
Annotated figure from "Test-Time Preference Optimization: On-the-Fly Alignment via Iterative Textual Feedback", https://arxiv.org/abs/2501.12895
- Thoughts Are All Over the Place
30 Jan, Thoughts Are All Over the Place: On the Underthinking of o1-Like LLMs, https://arxiv.org/abs/2501.18585
The researchers explore a phenomenon called "underthinking", where reasoning models frequently switch between reasoning paths instead of fully focusing on exploring promising ones, which lowers the problem solving accuracy.
To address this "underthinking" issue, they introduce a method called the Thought Switching Penalty (TIP), which modifies the logits of thought-switching tokens to discourage premature reasoning path transitions.
Their approach does not require model fine-tuning and empirically improves accuracy across multiple challenging test sets.

Annotated figure from "Thoughts Are All Over the Place: On the Underthinking of o1-Like LLMs", https://arxiv.org/abs/2501.18585
- Trading Inference-Time Compute for Adversarial Robustness
31 Jan, Trading Inference-Time Compute for Adversarial Robustness, https://arxiv.org/abs/2501.18841
Increasing inference-time compute improves the adversarial robustness of reasoning LLMs in many cases in terms of reducing the rate of successful attacks. Unlike adversarial training, this method does not need any special training or require prior knowledge of specific attack types.
However, there are some important exceptions. For example, the improvements in settings involving policy ambiguities or loophole exploitation are limited. Additionally, the reasoning-improved robustness increases can be reduced by new attack strategies such as "Think Less" and "Nerd Sniping".
So, while these findings suggest that scaling inference-time compute can improve LLM safety, this alone is not a complete solution to adversarial robustness.

Annotated figure from "Trading Inference-Time Compute for Adversarial Robustness", https://arxiv.org/abs/2501.18841
- Chain-of-Associated-Thoughts
4 Feb, CoAT: Chain-of-Associated-Thoughts Framework for Enhancing Large Language Models Reasoning, https://arxiv.org/abs/2502.02390
The researchers combine classic Monte Carlo Tree Search inference-time scaling with an "associative memory" that serves as the LLM's knowledge base during the exploration of reasoning pathways. Using this so-called associative memory, it's easier for the LLM to consider earlier reasoning pathways and use dynamically involving information during the response generation.

Annotated figure from "CoAT: Chain-of-Associated-Thoughts Framework for Enhancing Large Language Models Reasoning", https://arxiv.org/abs/2502.02390
- Step Back to Leap Forward
6 Feb, Step Back to Leap Forward: Self-Backtracking for Boosting Reasoning of Language Models, https://arxiv.org/abs/2502.0440
This paper proposes a self-backtracking mechanism that allows LLMs to improve
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み