Amazon SageMaker AIでClaudeとLangGraph、管理型MLflowを使用したサーバーレス会話型AIエージェントの構築
AWSはAmazon Bedrock、LangGraph、SageMaker AI上のManaged MLflowを組み合わせたサーバーレス会話型AIエージェントの実装例を公開し、顧客サービスの注文管理における自然言語理解とコンテキスト維持の課題解決を示唆している。
キーポイント
既存ソリューションの限界
従来のルールベースチャットボットは自然言語理解が不十分で、LLM単体ではビジネス運用に必要な構造化と信頼性が欠如しており、顧客は両者の課題に直面している。
統合アーキテクチャの提示
Amazon BedrockでLLMを呼び出し、LangGraphでグラフベースの会話フロー(意図識別→確認→解決)を制御し、SageMaker AI上のManaged MLflowでモデル管理を行う統合ソリューションを提供する。
注文管理エージェントの実装
顧客の注文確認やキャンセルといった具体的なタスクに対し、自然な会話を通じて情報を収集し、正確に実行する「Agentic flow」の具体的な実装パターンを示している。
影響分析・編集コメントを表示
影響分析
この記事は、LLMを単なるチャットツールではなく、ビジネスプロセスを自動化する「エージェント」として位置づけるための具体的な設計パターンを示しています。特に、LLMの出力の不安定性をLangGraphによる制御フローで補完し、MLflowによる管理で再現性を担保するアプローチは、企業におけるAI実装のベストプラクティスとして注目されるべきものです。
編集コメント
技術的な革新性よりも、実務での適用可能性に重点を置いた記事です。LLM導入における「構造化」と「信頼性」のバランスを取るための具体的なコード実装例として、開発者にとって参考価値が高い内容です。
カスタマーサービスチームは、継続的な課題に直面しています。既存のチャットベースのアシスタントは、硬直した応答によってユーザーを苛立たせており、一方、直接の実装された大規模言語モデル(LLM)は、信頼性の高いビジネス運用に必要な構造を持っていません。顧客が注文に関する問い合わせ、キャンセル、またはステータス更新について支援を必要とする場合、従来のアプローチでは自然言語を理解できないか、多段階の会話全体で文脈を維持することができません。
本記事では、Amazon Bedrock、LangGraph、および Amazon SageMaker AI 上の管理された MLflow を使用して、知的な対話型エージェントを構築する方法を探ります。
ソリューション概要
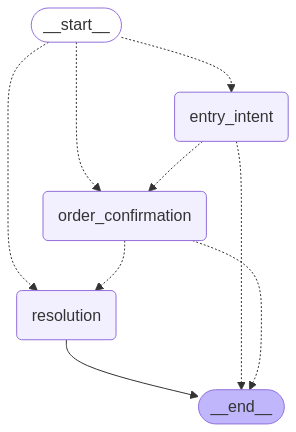
本記事で紹介する対話型 AI エージェントは、既存のカスタマーサービス自動化ソリューションにとって一般的だがしばしば困難なユースケースである顧客の注文問い合わせに対応するための実用的な実装を示しています。私たちは、顧客が自然な会話を通じて注文に関する情報を検索したり、キャンセルなどのアクションを実行したりできるように支援することで、これらの課題に対処する知的な注文管理エージェントを実装します。本システムは、3 つの主要なステージを持つグラフベースの対話フローを使用します:
- エントリー意図 – お客様の要望を特定し、必要な情報を収集する
- 注文確認 – 見つかった注文の詳細を表示し、お客様の意図を確認する
- 解決 – お客様のリクエストを実行し、完了させる
このエージェントフローは以下のグラフィックに示されています。
問題の提示
ほとんどのカスタマーサービス自動化ソリューションは、それぞれに重大な制限を持つ 2 つのカテゴリーに分類されます。
ルールベースのチャットアシスタントは、自然言語理解においてしばしば失敗し、ユーザー体験を不快なものにします。これらは通常、人間の会話のニュアンスを処理できない硬直した意思決定ツリーに従います。ユーザーが期待される入力から逸脱するとこれらのシステムは機能せず、ユーザーがアシスタントに適応するよう強要されます。例えば、ルールベースのチャットアシスタントは「注文をキャンセルしたい」と認識できても、「今買ったものを返品したい」という表現には対応できない場合があります。これは、後者が事前に定義されたパターンに一致しないためです。
一方、現代の大規模言語モデル(LLM)は自然言語を理解する点では卓越していますが、直接使用すると独自の課題に直面します。LLM は本来的に状態を維持したり、多段階のプロセスに従ったりしないため、会話管理が困難になります。LLM をバックエンドシステムに接続するには慎重なオーケストレーションが必要であり、そのパフォーマンスの監視には特有の観測可能性(observability)の課題が生じます。最も重要な点は、ドメイン知識へのアクセスがない場合、LLM が説得力はあるが誤った情報を生成する可能性があることです。
これらの制限を実際の例で理解するために、一見単純なカスタマーサービスのシナリオを考えてみましょう:ユーザーは注文状況の確認やキャンセルを依頼する必要があります。この対話では、ユーザーの意図を理解し、注文番号やアカウント詳細などの関連情報を抽出し、バックエンドシステムと照合して情報を検証し、実行前にアクションを確認し、会話全体を通じて文脈を維持することが必要です。構造化されたアプローチがない場合、ルールベースのシステムも生身の LLM も、メモリ(記憶)、計画、および外部システムとの統合を要するこれらの多段階プロセスを処理できません。
これらの根本的な限界こそが、既存のアプローチが実世界での応用において一貫して不十分である理由を説明しています。ルールベースのシステムは、自然な会話と構造化されたビジネスプロセスを効果的に橋渡すことができません。一方、大規模言語モデル(LLM)は、複数の対話にわたって状態を維持することができません。どちらのアプローチも、データ取得や更新のためにバックエンドシステムとシームレスに統合できず、パフォーマンスやユーザーエクスペリエンスに関する可視性が限定的です。最も重要な点は、現在のソリューションが、自然な会話に必要な柔軟性と、信頼性の高いカスタマーサービスに必要なビジネスルールの強制という、両者のバランスを取ることができないことです。
このソリューションは、AI エージェントを通じてこれらの課題に対処します。これは、LLM の自然言語処理能力と、構造化されたワークフロー、ツール統合、包括的な観測可能性を組み合わせたシステムです。
ソリューションアーキテクチャ
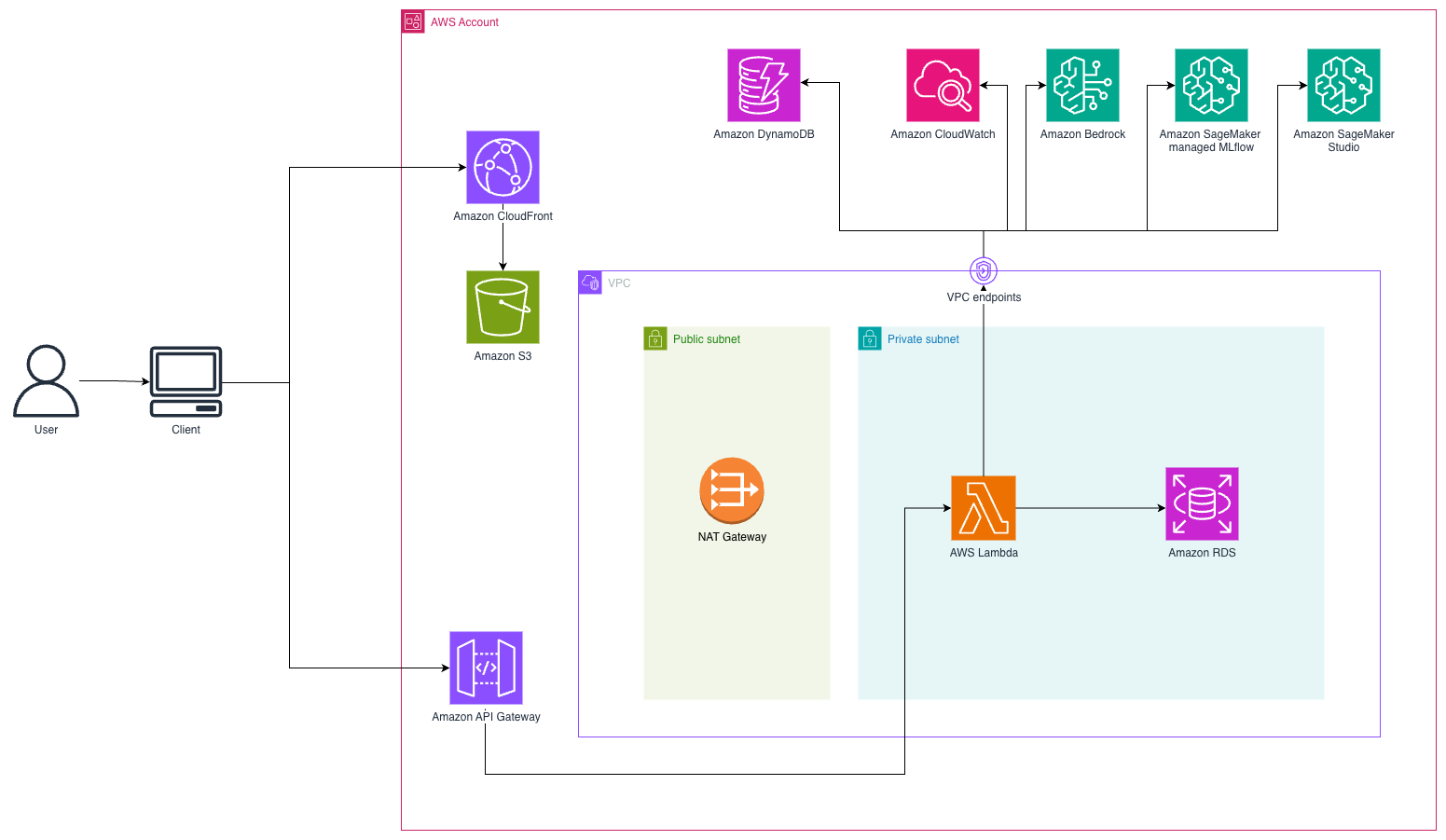
本ソリューションは、リアルタイムのカスタマーインタラクションのために WebSocket ベースのアーキテクチャを採用したサーバーレス型会話 AI システムを実装しています。顧客は Amazon Simple Storage Service(Amazon S3)にホストされた React フロントエンドにアクセスし、Amazon CloudFront を経由して配信されます。顧客がメッセージを送信すると、システムは Amazon API Gateway を通じて永続的な WebSocket 接続を確立し、会話フローをオーケストレーションする AWS Lambda 関数と通信します。以下の図にソリューションアーキテクチャを示します。
エージェントアーキテクチャ
本ソリューションでは、AI エージェント(LLM がタスク達成の方法を制御しつつ、自らのプロセスやツール使用を動的に指示するシステム)を利用します。単純な LLM アプリケーションとは異なり、これらのエージェントは複数の対話にわたって状態と文脈を維持し、外部ツールを使用して情報を収集したりアクションを実行したりでき、過去の結果に基づいて次のステップを推論し、ある程度の自律性を持って動作します。エージェントのワークフローは、初期化、ユーザー意図の理解、必要なアクションの計画、必要に応じたツールの呼び出し実行、応答の生成、および将来の対話のための会話状態の更新という構造化されたパターンに従います。
効果的な対話型エージェントを構築するには、以下の 4 つの中核的機能が必要です:
- ユーザーを理解し対応するための知能
- 対話全体にわたって文脈を維持する記憶力
- 外部システムでアクションを実行する能力
- 複雑な多段階ワークフローを管理するオーケストレーション
本実装では、これらの要件を満たすために、特定の Amazon Web Services (AWS) サービスおよびフレームワークを活用しています。
Amazon Bedrock はインテリジェンス層として機能し、一貫した API を通じて最先端の ファウンデーションモデル(FMs)へのアクセスを提供します。Amazon Bedrock は、ユーザーが何を実現しようとしているかを理解するための意図認識、注文番号や顧客詳細などの重要な情報を特定するためのエンティティ抽出、文脈に即した適切な応答を作成するための自然言語生成、会話フローにおける次の最適なアクションを決定するための意思決定、および外部システムと対話するためのツール使用の調整を処理するために使用されます。このインテリジェンス層により、当社のエージェントは自然言語を理解しながらも、信頼性の高いカスタマーサービスに必要な構造化された意思決定を維持することができます。
状態管理(エージェントメモリ)は Amazon DynamoDB を通じて処理され、中断やシステム再起動があった場合でも会話コンテキストに対する永続的ストレージを提供します。状態には、一意の会話識別子としてのセッション ID、コンテキスト維持のための完全な会話履歴、モデルのコンテキストウィンドウに最適化されたフォーマット済みのトランスクリプト、注文番号や顧客詳細などの抽出情報、および確認ステータスや情報取得の成功を示すプロセスフラグが含まれます。この永続的な状態により、当社のエージェントは複数の対話にわたってコンテキストを維持することができ、生来の LLM 実装における主要な制限の一つに対処しています。
状態管理のスニペットコード(完全な実装については、backed/app.py のコードを参照してください):
# 会話の状態を DynamoDB に保存する
ttl_value = int(time.time()) + (3600 * 4) # 4 時間
item = {
'conversationId': session_id,
'state': json.dumps(state_dict),
'chat_status': state_dict['session_end'],
'update_ts_pst': str(datetime.now(pst)),
'ttl': ttl_value,
'timestamp': int(time.time())
}
ddb_table.put_item(Item=item)
この状態には、一定期間の非アクティブ後に会話を自動的に期限切れにする Time-To-Live (TTL) 値が含まれており、ストレージコストの管理に役立ちます。
関数呼び出し、すなわちツール使用は、エージェントが外部システムと構造化された方法で対話することを可能にします。アクションを記述しようとする自由形式のテキストを生成する代わりに、モデルは特定の引数を備えた事前定義された関数に対する構造化された呼び出しを生成します。これは、LLM に説明書付きの一連のツールを与え、LLM がそれらのツールをいつ使用するか、そしてどのような情報を提供するかを決定すると考えることができます。私たちの実装では、Amazon Relational Database (Amazon RDS) for PostgreSQL データベースに接続する特定のツールを定義しています:顧客照会用の get_user、注文詳細用の get_order_by_id、顧客の注文一覧表示用の get_customer_orders、注文キャンセル用の cancel_order、および注文変更用の update_order です。
以下のコードスニペットは、アシスタントとユーザー間のメッセージシーケンス、ならびに必要な正しいツール名と入力またはパラメータを適切に処理するために使用されます。(実装の詳細については、backend/utils/utils.py を参照してください)
翻訳全文
tool_config = {
"toolChoice": {"auto": {}},
"tools": [
{
"toolSpec": {
"name": "get_order_by_id",
"description": "注文 ID に基づいて特定の注文の詳細を取得します。",
"inputSchema": {
"json": {
"type": "object",
"properties": {
"order_id": {
"type": "string",
"description": "注文の一意な識別子です。",
}
},
"required": ["order_id"],
},
},
},
}
]
}
上記のスニペットコードはツール定義の一例を示すのみですが、実装では 3 つの異なるツールが設定されています。詳細については、backend/tools_config/entry_intent_tool.py または backend/tools_config/agent_tool.py を参照してください。
この機能により、モデルは現実世界のデータやシステムに根ざし、事実に基づく情報を提供することで幻覚を軽減し、単独では不可能な機能を拡張するとともに、システム間の相互作用に一貫したパターンを強制します。関数呼び出しの構造的性質により、モデルは推測を行うのではなく、明確に定義されたインターフェースを通じて特定のデータのみを要求することができます。
LangGraph は、有向グラフアプローチを使用して状態保持型かつ多段階のアプリケーションを構築するためのオーケストレーションフレームワークを提供します。会話の状態を明示的に追跡し、各ノードが特定の会話フェーズを担当する関心の分離を実現し、文脈に基づいた動的な意思決定のための条件付きルーティング、ループや反復パターンを処理するためのサイクル検出機能、および新しいノードの追加や既存フローの変更が容易な柔軟なアーキテクチャを提供します。LangGraph は、会話のフローチャートを作成するものと考えられ、各ボックスは会話の特定の部分を表し、矢印はそれらの間をどのように移動するかを示します。
会話の流れは、LangGraph を使用して有向グラフとして実装されています。参考までに、ソリューションアーキテクチャセクションにあるエージェントフローのグラフィックをご参照ください。
以下のコードスニペットは、異なるユーザーインタラクションにわたって情報を収集し、エージェントに適切な文脈を提供するための構造グラフコンテキストである状態グラフを示しています:
class State(TypedDict):
# Messages tracked in the conversation history
messages: list
# Transcription attributes tracks updates posted by the agent
transcript: list
# Session Id is the unique identifier attribute of the conversation
session_id: str
# Order number
order_number: str
# tracks in the conversation is still active
session_end: bool
# tracks the current node in the conversation
current_turn: int
# tracks the next node in the conversation
next_node: str
# track status of the confirmation
order_confirmed: bool
# track status of the orders eligible
order_info_found: bool
This state object maintains the relevant information about the conversation, allowing the system to make informed decisions about routing and responses.
Our conversation flow uses three main nodes: the entry intent node handles initial user requests and extracts key information, the order confirmation node verifies details and confirms user intent, and the resolution node executes requested actions and provides closure. This approach offers explicit state management, conditional routing, separation of concerns, reusability across different conversation flows, and clear visualization of conversation paths:
ノードとエッジの定義
graph_builder = StateGraph(State)
ノードの追加
graph_builder.add_node("entry_intent", entry_intent.node)
graph_builder.add_node("order_confirmation", order_confirmation.node)
graph_builder.add_node("resolution", resolution.node)
ルーティングロジックを持つ条件付きエッジの追加
graph_builder.add_conditional_edges(
START,
initial_router,
{
'entry_intent': 'entry_intent',
'order_confirmation': 'order_confirmation',
'resolution': 'resolution'
}
)
ノード間のエッジは、StateGraph の内容に基づき、以下のコードスニペットに示すように、実行時のフローを決定するために条件付きロジックを使用します:
graph_builder.add_conditional_edges(
'entry_intent',
lambda x: x["next_node"],
{
'order_confirmation': 'order_confirmation',
'__end__': END
}
)
会話グラフ内の各ノードは、現在の状態を処理して更新された状態を返す Python 関数として実装されています。エントリー意図ノードは初期のユーザーリクエストを扱い、注文番号などの重要な情報を抽出し、顧客の問い合わせを解釈することで次のステップを決定します。このノードでは、関連する注文情報を探すためのツールを使用し、注文番号や顧客識別子などの主要な詳細を抽出して、進行に必要な情報が揃っているかどうかを判断します。
注文確認ノードは、見つかった注文の詳細を顧客に提示することで詳細を検証し、ユーザーの意図を確認し、これが議論中の正しい注文であることを検証し、顧客がその注文について抱いている意図を確認します。
解決ノードは、要求されたアクションを実行して完了を提供します。具体的には、ステータスの提供や注文のキャンセルなどの必要なアクションを実行し、要求されたアクションの成功した完了を確認し、注文に関するフォローアップ質問に回答し、会話に対する自然な結論を提供します:
@mlflow.trace(span_type=SpanType.AGENT)
def node(state: Dict[str, Any]) -> Dict[str, Any]:
"""
チャットメッセージの処理と注文情報の管理を行うエントリー意図ノード。
このノードは以下の処理を担当します:
- チャットモデルを用いた初期メッセージの処理
- 注文情報取得のためのツール実行
- 状態の管理と更新
- 注文情報に基づく動的なルーティング
"""
完全な実装の詳細については、以下のリポジトリを参照してください:backend/nodes。
各ノードは、状態から関連情報を抽出し、大規模言語モデル(LLM)を使用してユーザーメッセージを処理し、必要なツールを実行し、新しい情報で状態を更新し、フロー内の次のノードを決定するという一貫したパターンを使用しています。
観測可能性が不可欠となるのは、LLM アプリケーションには非決定的な出力など独自の課題があるためです。同じ入力であっても
原文を表示
Customer service teams face a persistent challenge. Existing chat-based assistants frustrate users with rigid responses, while direct large language model (LLM) implementations lack the structure needed for reliable business operations. When customers need help with order inquiries, cancellations, or status updates, traditional approaches either fail to understand natural language or can’t maintain context across multistep conversations.
This post explores how to build an intelligent conversational agent using Amazon Bedrock, LangGraph, and managed MLflow on Amazon SageMaker AI.
Solution overview
The conversational AI agent presented in this post demonstrates a practical implementation for handling customer order inquiries, a common but often challenging use case for existing customer service automation solutions. We implement an intelligent order management agent that addresses these challenges by helping customers find information about their orders and take actions such as cancellations through natural conversation. The system uses a graph-based conversation flow with three key stages:
- Entry intent – Identifies what the customer wants and collects necessary information
- Order confirmation –Presents found order details and verifies customer intentions
- Resolution – Executes the customer’s request and provides closure
This agentic flow is illustrated in the following graphic.
Problem statement
Most customer service automation solutions fall into two categories, each with significant limitations.
Rule-based chat assistant often fail at natural language understanding, leading to frustrating user experiences. They typically follow rigid decision trees that can’t handle the nuances of human conversation. When users deviate from expected inputs, these systems fail, forcing users to adapt to the assistant rather than the other way around. For example, a rule-based chat assistant might recognize “I want to cancel my order” but fail with “I need to return something I just bought” because it doesn’t match predefined patterns.
Meanwhile, modern LLMs excel at understanding natural language but present their own challenges when used directly. LLMs don’t inherently maintain state or follow multistep processes, making conversation management difficult. Connecting LLMs to backend systems requires careful orchestration, and monitoring their performance presents unique observability challenges. Most critically, LLMs may generate plausible but incorrect information when they lack access to domain knowledge.
To understand these limitations for a real-world example, consider a seemingly simple customer service scenario: a user needs to check on an order status or request a cancellation. This interaction requires understanding the user’s intent, extracting relevant information like order numbers and account details, verifying information against backend systems, confirming actions before execution, and maintaining context throughout the conversation. Without a structured approach, both rule-based systems and raw LLMs can’t handle these multistep processes that require memory, planning, and integration with external systems.
These fundamental limitations explain why existing approaches consistently fall short in real-world applications. Rule-based systems can’t effectively bridge natural conversation with structured business processes, while LLMs can’t maintain state across multiple interactions. Neither approach can seamlessly integrate with backend systems for data retrieval and updates, and both provide limited visibility into performance and user experience. Most critically, current solutions can’t balance the flexibility needed for natural conversation with the business rule enforcement required for reliable customer service.
This solution addresses these challenges through AI agents—systems that combine the natural language capabilities of LLMs with structured workflows, tool integration, and comprehensive observability.
Solution architecture
This solution implements a serverless conversational AI system using a WebSocket-based architecture for real-time customer interactions. Customers access a React frontend hosted on Amazon Simple Storage Service (Amazon S3) and delivered through Amazon CloudFront. When customers send messages, the system establishes a persistent WebSocket connection through Amazon API Gateway to AWS Lambda functions that orchestrate the conversation flow. The following diagram illustrates the solution architecture.
Agent architecture
This solution uses AI agents, systems where LLMs dynamically direct their own processes and tool usage while maintaining control over how they accomplish tasks. Unlike simple LLM applications, these agents maintain state and context across multiple interactions, can use external tools to gather information or perform actions, reason about their next steps based on previous outcomes, and operate with some degree of autonomy. The agent workflow follows a structured pattern of initialization, understanding user intent, planning required actions, executing tool calls when needed, generating responses, and updating conversation state for future interactions.
To build effective conversational agents, we need four core capabilities:
- Intelligence to understand and respond to users
- Memory to maintain context across conversations
- Ability to take actions in external systems
- Orchestration to manage complex multistep workflows
Our implementation addresses these requirements through specific Amazon Web Services (AWS) services and frameworks.
Amazon Bedrock serves as the intelligence layer, providing access to state-of-the-art foundation models (FMs) through a consistent API. Amazon Bedrock is used to handle intent recognition to understand what users are trying to accomplish, entity extraction to identify key information such as order numbers and customer details, natural language generation to create contextually appropriate responses, decision-making to determine the next best action in conversation flows, and coordination of tool use to interact with external systems. This intelligence layer enables our agent to understand natural language while maintaining the structured decision-making needed for reliable customer service.
State management (agent memory) is handled through Amazon DynamoDB, which provides persistent storage for conversation context even if there are interruptions or system restarts. The state includes session IDs as unique conversation identifiers, complete conversation history for context maintenance, formatted transcripts optimized for model context windows, extracted information such as order numbers and customer details, and process flags indicating confirmation status and information retrieval success. This persistent state allows our agent to maintain context across multiple interactions, addressing one of the key limitations of raw LLM implementations.
State management snippet code (for full implementation you can reference the code in backed/app.py):
# Save conversation state to DynamoDB
ttl_value = int(time.time()) + (3600 * 4) # 4 hrs
item = {
'conversationId': session_id,
'state': json.dumps(state_dict),
'chat_status': state_dict['session_end'],
'update_ts_pst': str(datetime.now(pst)),
'ttl': ttl_value,
'timestamp': int(time.time())
}
ddb_table.put_item(Item=item)
The state includes a Time-To-Live (TTL) value that automatically expires conversations after a period of inactivity, helping to manage storage costs.
Function calling, also known as tool use, enables our agent to interact with external systems in a structured way. Instead of generating free-form text that attempts to describe an action, the model generates structured calls to predefined functions with specific parameters. You can think of this as giving the LLM a set of tools complete with instruction manuals, where the LLM decides when to use these tools and what information to provide. Our implementation defines specific tools that connect to an Amazon Relational Database (Amazon RDS) for PostgreSQL database: get_user for customer lookups, get_order_by_id for order details, get_customer_orders for listing customer orders, cancel_order for order cancellations, and update_order for order modifications.
The following code snippet allows proper handling of the message sequence between the assistant and user along with the right tool name and inputs or parameters required. (For implementation details, refer to backend/utils/utils.py):
def use_tool(messages):
tool_use = messages[-1]["content"][-1].get("toolUse")
if tool_use:
tool_name = tool_use["name"]
tool_input = tool_use["input"]
# Process the tool call
tool_result = _process_tool_call(tool_name, tool_input)
# Format response for the model
message = {
"role": "user",
"content": [
{
"toolResult": {
"toolUseId": tool_use["toolUseId"],
"content": [
{"text": json.dumps(tool_result)}
],
"status": "success",
}
}
],
}
return message
The tools are defined with JSON schemas that provide clear contracts for the model to follow:
tool_config = {
"toolChoice": {"auto": {}},
"tools": [
{
"toolSpec": {
"name": "get_order_by_id",
"description": "Retrieves the details of a specific order based on the order ID.",
"inputSchema": {
"json": {
"type": "object",
"properties": {
"order_id": {
"type": "string",
"description": "The unique identifier for the order.",
}
},
"required": ["order_id"],
},
},
},
}
]
}The previous snippet code shows only one example of tool definition, however in the implementation there are three different tools configured. For full details, refer to backend/tools_config/entry_intent_tool.py or backend/tools_config/agent_tool.py
This capability grounds the model to real-world data and systems, reduces hallucinations by providing factual information, extends the model’s capabilities beyond what it could do alone, and enforces consistent patterns for system interactions. The structured nature of function calling means that the model can only request specific data through well-defined interfaces rather than making assumptions.
LangGraph provides the orchestration framework for building stateful, multistep applications using a directed graph approach. It offers explicit tracking of conversation state, separation of concerns where each node handles a specific conversation phase, conditional routing for dynamic decision-making based on context, cycle detection to handle loops and repetitive patterns, and flexible architecture that’s straightforward to extend with new nodes or modify existing flows. You can think of LangGraph as creating a flowchart for your conversation, where each box represents a specific part of the conversation and the arrows show how to move between them.
The conversation flow is implemented as a directed graph using LangGraph. For reference, check the agentic flow graphic in the Solution architecture section.
The following code snippet shows the state graph that is a structure graph context used to collect information across different user interactions giving the agent the proper context:
class State(TypedDict):
# Messages tracked in the conversation history
messages: list
# Transcription attributes tracks updates posted by the agent
transcript: list
# Session Id is the unique identifier attribute of the conversation
session_id: str
# Order number
order_number: str
# tracks in the conversation is still active
session_end: bool
# tracks the current node in the conversation
current_turn: int
# tracks the next node in the conversation
next_node: str
# track status of the confirmation
order_confirmed: bool
# track status of the orders eligible
order_info_found: bool
This state object maintains the relevant information about the conversation, allowing the system to make informed decisions about routing and responses.
Our conversation flow uses three main nodes: the entry intent node handles initial user requests and extracts key information, the order confirmation node verifies details and confirms user intent, and the resolution node executes requested actions and provides closure. This approach offers explicit state management, conditional routing, separation of concerns, reusability across different conversation flows, and clear visualization of conversation paths:
# Define nodes and edges
graph_builder = StateGraph(State)
# Add nodes
graph_builder.add_node("entry_intent", entry_intent.node)
graph_builder.add_node("order_confirmation", order_confirmation.node)
graph_builder.add_node("resolution", resolution.node)
# Add conditional edges with routing logic
graph_builder.add_conditional_edges(
START,
initial_router,
{
'entry_intent': 'entry_intent',
'order_confirmation': 'order_confirmation',
'resolution': 'resolution'
}
)
The edges between nodes use conditional logic to determine the flow on a runtime execution as shown in the following code snippet based on the content of the StateGraph:
graph_builder.add_conditional_edges(
'entry_intent',
lambda x: x["next_node"],
{
'order_confirmation': 'order_confirmation',
'__end__': END
}
)
Each node in the conversation graph is implemented as a Python function that processes the current state and returns an updated state. The entry intent node handles initial user requests, extracts key information such as order numbers, and determines next steps by interpreting customer queries. It uses tools to search for relevant order information, extract key details such as order numbers or customer identifiers, and determines if enough information is available to proceed. The order confirmation node verifies details and confirms user intent by presenting found order details to the customer, verifying this is the correct order being discussed, and confirming the customer’s intentions regarding the order. The resolution node executes requested actions and provides closure by executing necessary actions such as providing status or canceling orders, confirming successful completion of requested actions, answering follow-up questions about the order, and providing a natural conclusion to the conversation:
@mlflow.trace(span_type=SpanType.AGENT)
def node(state: Dict[str, Any]) -> Dict[str, Any]:
"""
Entry intent node for processing chat messages and managing order information.
This node handles:
1. Initial message processing with the chat model
2. Tool execution for order information retrieval
3. State management and updates
4. Dynamic routing based on order information
"""
For full implementation details, refer to: backend/nodes.
The nodes use a consistent pattern of extracting relevant information from the state, processing the user message using the LLM, executing the necessary tools, updating the state with new information, and determining the next node in the flow.
Observability becomes essential because LLM applications present unique challenges including nondeterministic outputs where the same input
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み